 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCloud2Edge Elastic AI Framework for Prototyping and Deployment of AI Inference Engines in Autonomous Vehicles
Sep 23, 2020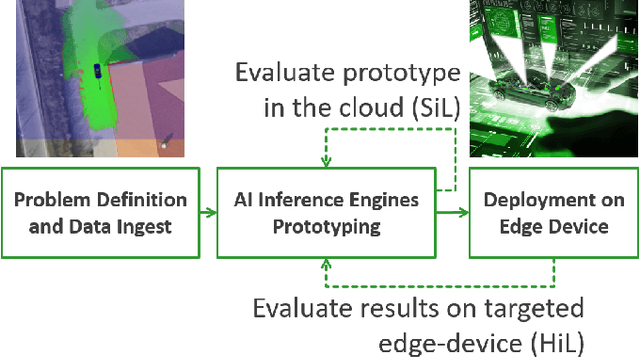
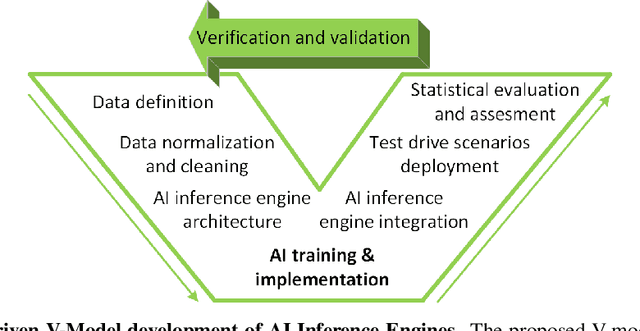
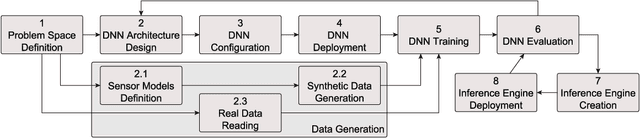
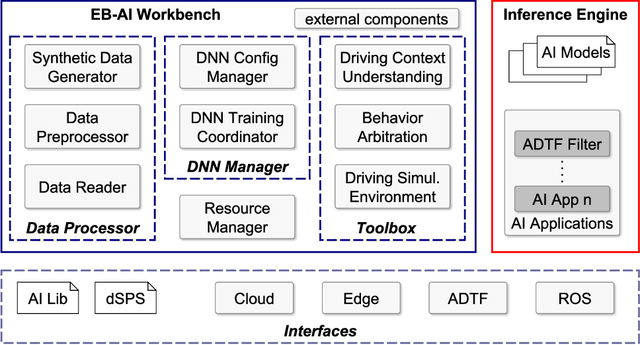
Self-driving cars and autonomous vehicles are revolutionizing the automotive sector, shaping the future of mobility altogether. Although the integration of novel technologies such as Artificial Intelligence (AI) and Cloud/Edge computing provides golden opportunities to improve autonomous driving applications, there is the need to modernize accordingly the whole prototyping and deployment cycle of AI components. This paper proposes a novel framework for developing so-called AI Inference Engines for autonomous driving applications based on deep learning modules, where training tasks are deployed elastically over both Cloud and Edge resources, with the purpose of reducing the required network bandwidth, as well as mitigating privacy issues. Based on our proposed data driven V-Model, we introduce a simple yet elegant solution for the AI components development cycle, where prototyping takes place in the cloud according to the Software-in-the-Loop (SiL) paradigm, while deployment and evaluation on the target ECUs (Electronic Control Units) is performed as Hardware-in-the-Loop (HiL) testing. The effectiveness of the proposed framework is demonstrated using two real-world use-cases of AI inference engines for autonomous vehicles, that is environment perception and most probable path prediction.
A Methodology to Select Topology Generators for WANET Simulations (Extended Version)
Aug 26, 2019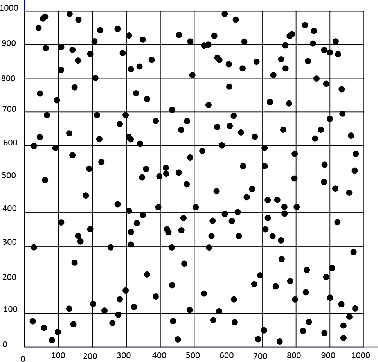

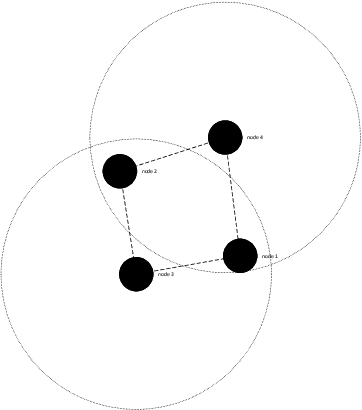

Many academic and industrial research works on WANETs rely on simulations, at least in the first stages, to obtain preliminary results to be subsequently validated in real settings. Topology generators (TG) are commonly used to generate the initial placement of nodes in artificial WANET topologies, where those simulations take place. The significance of these experiments heavily depends on the representativeness of artificial topologies. Indeed, if they were not drawn fairly, obtained results would apply only to a subset of possible configurations, hence they would lack of the appropriate generality required to port them to the real world. Although using many TGs could mitigate this issue by generating topologies in several different ways, that would entail a significant additional effort. Hence, the problem arises of what TGs to choose, among a number of available generators, to maximise the representativeness of generated topologies and reduce the number of TGs to use. In this paper, we address that problem by investigating the presence of bias in the initial placement of nodes in artificial WANET topologies produced by different TGs. We propose a methodology to assess such bias and introduce two metrics to quantify the diversity of the topologies generated by a TG with respect to all the available TGs, which can be used to select what TGs to use. We carry out experiments on three well-known TGs, namely BRITE, NPART and GT-ITM. Obtained results show that using the artificial networks produced by a single TG can introduce bias.