 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Frame is Worth One Token: Efficient Generative World Modeling with Delta Tokens
Apr 06, 2026Anticipating diverse future states is a central challenge in video world modeling. Discriminative world models produce a deterministic prediction that implicitly averages over possible futures, while existing generative world models remain computationally expensive. Recent work demonstrates that predicting the future in the feature space of a vision foundation model (VFM), rather than a latent space optimized for pixel reconstruction, requires significantly fewer world model parameters. However, most such approaches remain discriminative. In this work, we introduce DeltaTok, a tokenizer that encodes the VFM feature difference between consecutive frames into a single continuous "delta" token, and DeltaWorld, a generative world model operating on these tokens to efficiently generate diverse plausible futures. Delta tokens reduce video from a three-dimensional spatio-temporal representation to a one-dimensional temporal sequence, for example yielding a 1,024x token reduction with 512x512 frames. This compact representation enables tractable multi-hypothesis training, where many futures are generated in parallel and only the best is supervised. At inference, this leads to diverse predictions in a single forward pass. Experiments on dense forecasting tasks demonstrate that DeltaWorld forecasts futures that more closely align with real-world outcomes, while having over 35x fewer parameters and using 2,000x fewer FLOPs than existing generative world models. Code and weights: https://deltatok.github.io.
Scaling Laws for Robust Comparison of Open Foundation Language-Vision Models and Datasets
Jun 05, 2025



In studies of transferable learning, scaling laws are obtained for various important foundation models to predict their properties and performance at larger scales. We show here how scaling law derivation can also be used for model and dataset comparison, allowing to decide which procedure is to be preferred for pre-training. For the first time, full scaling laws based on dense measurements across a wide span of model and samples seen scales are derived for two important language-vision learning procedures, CLIP and MaMMUT, that use either contrastive only or contrastive and captioning text generative loss. Ensuring sufficient prediction accuracy for held out points, we use derived scaling laws to compare both models, obtaining evidence for MaMMUT's stronger improvement with scale and better sample efficiency than standard CLIP. To strengthen validity of the comparison, we show scaling laws for various downstream tasks, classification, retrieval, and segmentation, and for different open datasets, DataComp, DFN and Re-LAION, observing consistently the same trends. We show that comparison can also be performed when deriving scaling laws with a constant learning rate schedule, reducing compute cost. Accurate derivation of scaling laws provides thus means to perform model and dataset comparison across scale spans, avoiding misleading conclusions based on measurements from single reference scales only, paving the road for systematic comparison and improvement of open foundation models and datasets for their creation. We release all the pre-trained models with their intermediate checkpoints, including openMaMMUT-L/14, which achieves $80.3\%$ zero-shot ImageNet-1k accuracy, trained on 12.8B samples from DataComp-1.4B. Code for reproducing experiments in the paper and raw experiments data can be found at https://github.com/LAION-AI/scaling-laws-for-comparison.
What is the Added Value of UDA in the VFM Era?
Apr 25, 2025Unsupervised Domain Adaptation (UDA) can improve a perception model's generalization to an unlabeled target domain starting from a labeled source domain. UDA using Vision Foundation Models (VFMs) with synthetic source data can achieve generalization performance comparable to fully-supervised learning with real target data. However, because VFMs have strong generalization from their pre-training, more straightforward, source-only fine-tuning can also perform well on the target. As data scenarios used in academic research are not necessarily representative for real-world applications, it is currently unclear (a) how UDA behaves with more representative and diverse data and (b) if source-only fine-tuning of VFMs can perform equally well in these scenarios. Our research aims to close these gaps and, similar to previous studies, we focus on semantic segmentation as a representative perception task. We assess UDA for synth-to-real and real-to-real use cases with different source and target data combinations. We also investigate the effect of using a small amount of labeled target data in UDA. We clarify that while these scenarios are more realistic, they are not necessarily more challenging. Our results show that, when using stronger synthetic source data, UDA's improvement over source-only fine-tuning of VFMs reduces from +8 mIoU to +2 mIoU, and when using more diverse real source data, UDA has no added value. However, UDA generalization is always higher in all synthetic data scenarios than source-only fine-tuning and, when including only 1/16 of Cityscapes labels, synthetic UDA obtains the same state-of-the-art segmentation quality of 85 mIoU as a fully-supervised model using all labels. Considering the mixed results, we discuss how UDA can best support robust autonomous driving at scale.
Your ViT is Secretly an Image Segmentation Model
Mar 24, 2025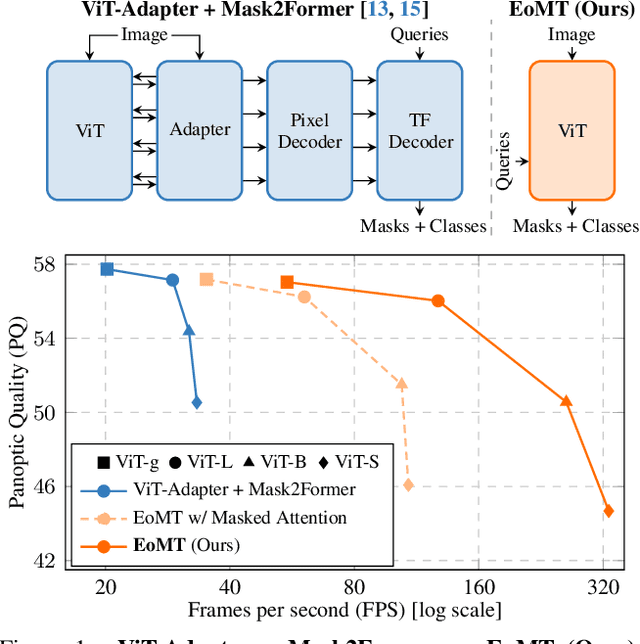
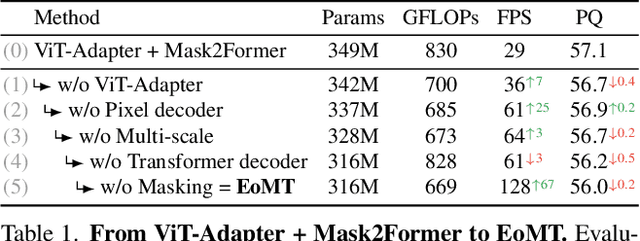
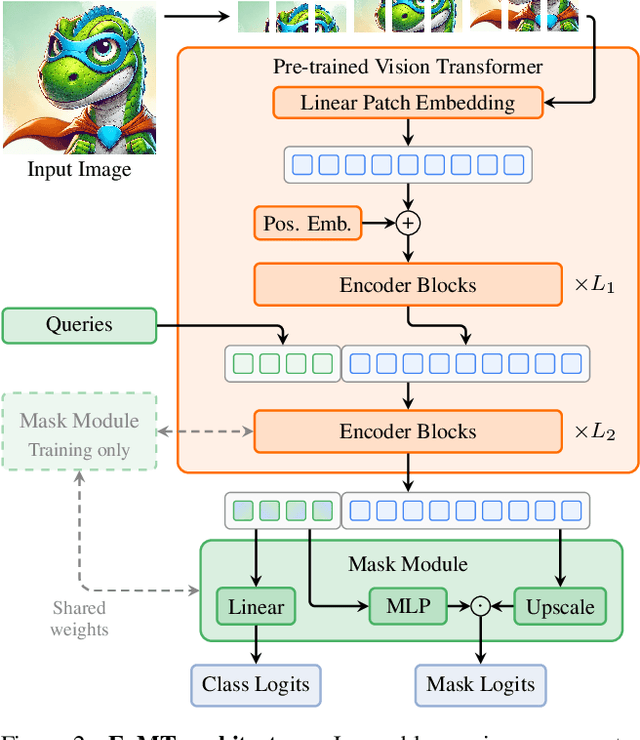
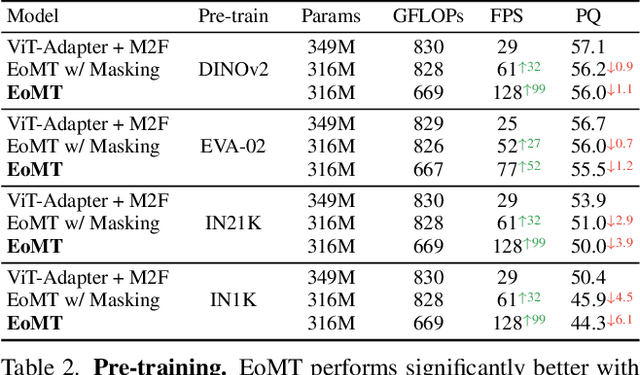
Vision Transformers (ViTs) have shown remarkable performance and scalability across various computer vision tasks. To apply single-scale ViTs to image segmentation, existing methods adopt a convolutional adapter to generate multi-scale features, a pixel decoder to fuse these features, and a Transformer decoder that uses the fused features to make predictions. In this paper, we show that the inductive biases introduced by these task-specific components can instead be learned by the ViT itself, given sufficiently large models and extensive pre-training. Based on these findings, we introduce the Encoder-only Mask Transformer (EoMT), which repurposes the plain ViT architecture to conduct image segmentation. With large-scale models and pre-training, EoMT obtains a segmentation accuracy similar to state-of-the-art models that use task-specific components. At the same time, EoMT is significantly faster than these methods due to its architectural simplicity, e.g., up to 4x faster with ViT-L. Across a range of model sizes, EoMT demonstrates an optimal balance between segmentation accuracy and prediction speed, suggesting that compute resources are better spent on scaling the ViT itself rather than adding architectural complexity. Code: https://www.tue-mps.org/eomt/.
2024 BRAVO Challenge Track 1 1st Place Report: Evaluating Robustness of Vision Foundation Models for Semantic Segmentation
Sep 25, 2024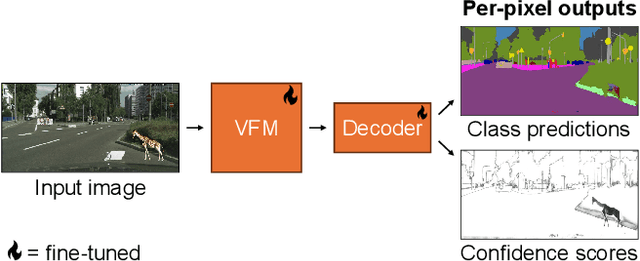



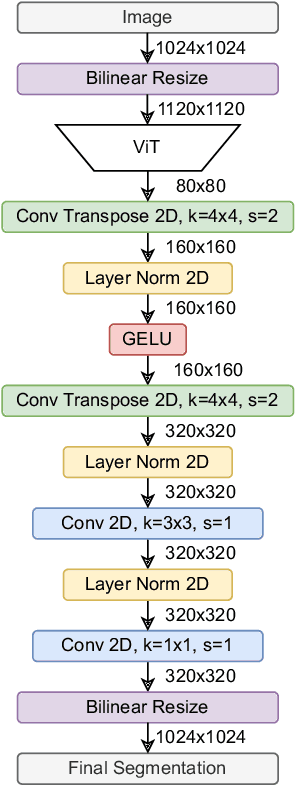
In this report, we present our solution for Track 1 of the 2024 BRAVO Challenge, where a model is trained on Cityscapes and its robustness is evaluated on several out-of-distribution datasets. Our solution leverages the powerful representations learned by vision foundation models, by attaching a simple segmentation decoder to DINOv2 and fine-tuning the entire model. This approach outperforms more complex existing approaches, and achieves 1st place in the challenge. Our code is publicly available at https://github.com/tue-mps/benchmark-vfm-ss.
Exploring the Benefits of Vision Foundation Models for Unsupervised Domain Adaptation
Jun 17, 2024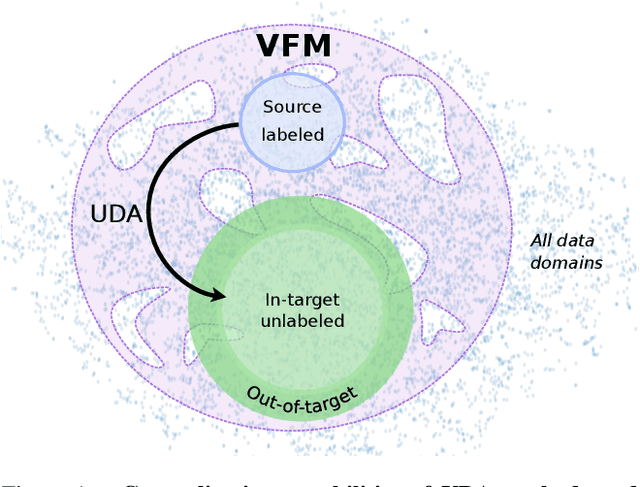
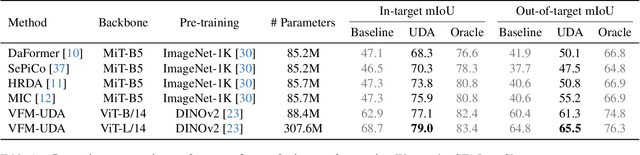
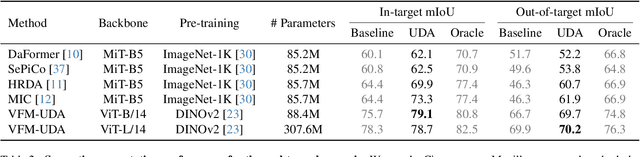
Achieving robust generalization across diverse data domains remains a significant challenge in computer vision. This challenge is important in safety-critical applications, where deep-neural-network-based systems must perform reliably under various environmental conditions not seen during training. Our study investigates whether the generalization capabilities of Vision Foundation Models (VFMs) and Unsupervised Domain Adaptation (UDA) methods for the semantic segmentation task are complementary. Results show that combining VFMs with UDA has two main benefits: (a) it allows for better UDA performance while maintaining the out-of-distribution performance of VFMs, and (b) it makes certain time-consuming UDA components redundant, thus enabling significant inference speedups. Specifically, with equivalent model sizes, the resulting VFM-UDA method achieves an 8.4$\times$ speed increase over the prior non-VFM state of the art, while also improving performance by +1.2 mIoU in the UDA setting and by +6.1 mIoU in terms of out-of-distribution generalization. Moreover, when we use a VFM with 3.6$\times$ more parameters, the VFM-UDA approach maintains a 3.3$\times$ speed up, while improving the UDA performance by +3.1 mIoU and the out-of-distribution performance by +10.3 mIoU. These results underscore the significant benefits of combining VFMs with UDA, setting new standards and baselines for Unsupervised Domain Adaptation in semantic segmentation.
How to Benchmark Vision Foundation Models for Semantic Segmentation?
Apr 18, 2024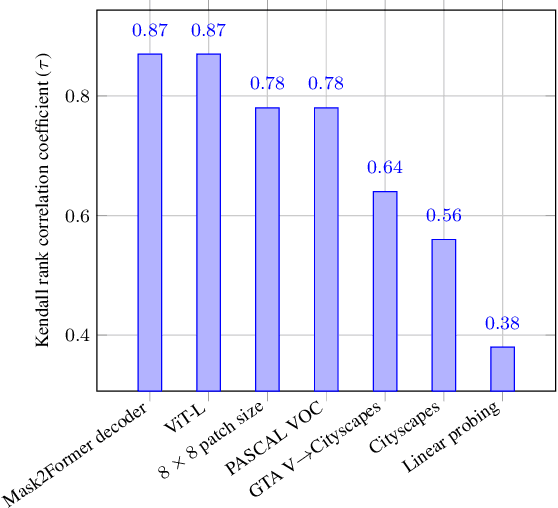
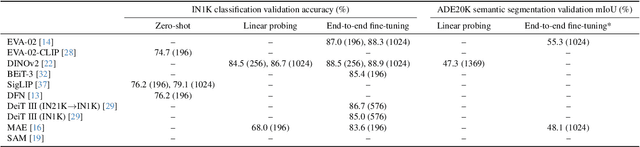

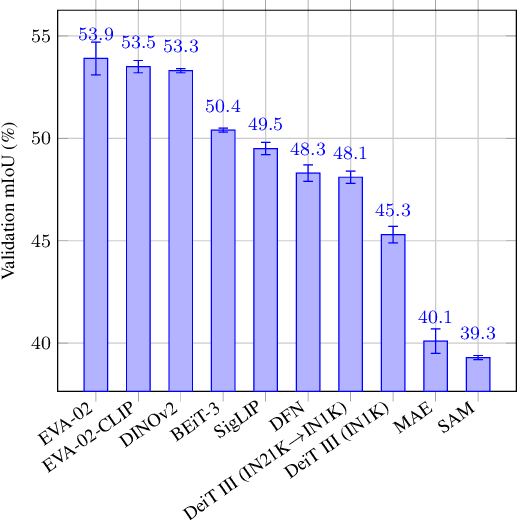
Recent vision foundation models (VFMs) have demonstrated proficiency in various tasks but require supervised fine-tuning to perform the task of semantic segmentation effectively. Benchmarking their performance is essential for selecting current models and guiding future model developments for this task. The lack of a standardized benchmark complicates comparisons. Therefore, the primary objective of this paper is to study how VFMs should be benchmarked for semantic segmentation. To do so, various VFMs are fine-tuned under various settings, and the impact of individual settings on the performance ranking and training time is assessed. Based on the results, the recommendation is to fine-tune the ViT-B variants of VFMs with a 16x16 patch size and a linear decoder, as these settings are representative of using a larger model, more advanced decoder and smaller patch size, while reducing training time by more than 13 times. Using multiple datasets for training and evaluation is also recommended, as the performance ranking across datasets and domain shifts varies. Linear probing, a common practice for some VFMs, is not recommended, as it is not representative of end-to-end fine-tuning. The benchmarking setup recommended in this paper enables a performance analysis of VFMs for semantic segmentation. The findings of such an analysis reveal that pretraining with promptable segmentation is not beneficial, whereas masked image modeling (MIM) with abstract representations is crucial, even more important than the type of supervision used. The code for efficiently fine-tuning VFMs for semantic segmentation can be accessed through the project page at: https://tue-mps.github.io/benchmark-vfm-ss/.
Neural Architecture Search for Visual Anomaly Segmentation
May 02, 2023This paper presents the first application of neural architecture search to the complex task of segmenting visual anomalies. Measurement of anomaly segmentation performance is challenging due to imbalanced anomaly pixels, varying region areas, and various types of anomalies. First, the region-weighted Average Precision (rwAP) metric is proposed as an alternative to existing metrics, which does not need to be limited to a specific maximum false positive rate. Second, the AutoPatch neural architecture search method is proposed, which enables efficient segmentation of visual anomalies without any training. By leveraging a pre-trained supernet, a black-box optimization algorithm can directly minimize computational complexity and maximize performance on a small validation set of anomalous examples. Finally, compelling results are presented on the widely studied MVTec dataset, demonstrating that AutoPatch outperforms the current state-of-the-art with lower computational complexity, using only one example per type of anomaly. The results highlight the potential of automated machine learning to optimize throughput in industrial quality control. The code for AutoPatch is available at: https://github.com/tommiekerssies/AutoPatch
Evaluating Continual Test-Time Adaptation for Contextual and Semantic Domain Shifts
Aug 18, 2022
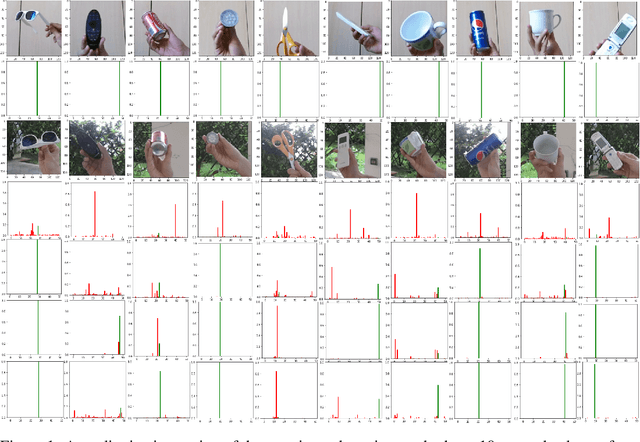

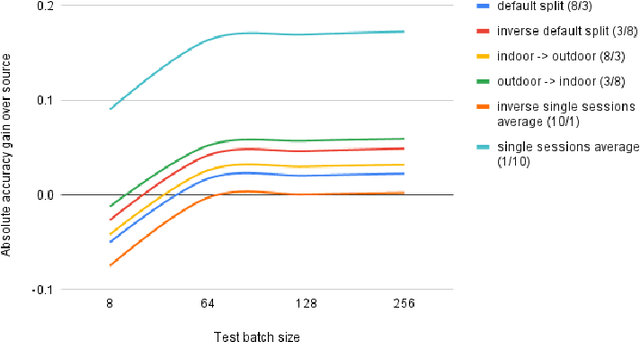
In this paper, our goal is to adapt a pre-trained Convolutional Neural Network to domain shifts at test time. We do so continually with the incoming stream of test batches, without labels. Existing literature mostly operates on artificial shifts obtained via adversarial perturbations of a test image. Motivated by this, we evaluate the state of the art on two realistic and challenging sources of domain shifts, namely contextual and semantic shifts. Contextual shifts correspond to the environment types, for example a model pre-trained on indoor context has to adapt to the outdoor context on CORe-50 [7]. Semantic shifts correspond to the capture types, for example a model pre-trained on natural images has to adapt to cliparts, sketches and paintings on DomainNet [10]. We include in our analysis recent techniques such as Prediction-Time Batch Normalization (BN) [8], Test Entropy Minimization (TENT) [16] and Continual Test-Time Adaptation (CoTTA) [17]. Our findings are three-fold: i) Test-time adaptation methods perform better and forget less on contextual shifts compared to semantic shifts, ii) TENT outperforms other methods on short-term adaptation, whereas CoTTA outpeforms other methods on long-term adaptation, iii) BN is most reliable and robust.