 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining Semantic Segmentation on Heterogeneous Datasets
Jan 18, 2023



We explore semantic segmentation beyond the conventional, single-dataset homogeneous training and bring forward the problem of Heterogeneous Training of Semantic Segmentation (HTSS). HTSS involves simultaneous training on multiple heterogeneous datasets, i.e. datasets with conflicting label spaces and different (weak) annotation types from the perspective of semantic segmentation. The HTSS formulation exposes deep networks to a larger and previously unexplored aggregation of information that can potentially enhance semantic segmentation in three directions: i) performance: increased segmentation metrics on seen datasets, ii) generalization: improved segmentation metrics on unseen datasets, and iii) knowledgeability: increased number of recognizable semantic concepts. To research these benefits of HTSS, we propose a unified framework, that incorporates heterogeneous datasets in a single-network training pipeline following the established FCN standard. Our framework first curates heterogeneous datasets to bring them into a common format and then trains a single-backbone FCN on all of them simultaneously. To achieve this, it transforms weak annotations, which are incompatible with semantic segmentation, to per-pixel labels, and hierarchizes their label spaces into a universal taxonomy. The trained HTSS models demonstrate performance and generalization gains over a wide range of datasets and extend the inference label space entailing hundreds of semantic classes.
Towards holistic scene understanding: Semantic segmentation and beyond
Jan 16, 2022This dissertation addresses visual scene understanding and enhances segmentation performance and generalization, training efficiency of networks, and holistic understanding. First, we investigate semantic segmentation in the context of street scenes and train semantic segmentation networks on combinations of various datasets. In Chapter 2 we design a framework of hierarchical classifiers over a single convolutional backbone, and train it end-to-end on a combination of pixel-labeled datasets, improving generalizability and the number of recognizable semantic concepts. Chapter 3 focuses on enriching semantic segmentation with weak supervision and proposes a weakly-supervised algorithm for training with bounding box-level and image-level supervision instead of only with per-pixel supervision. The memory and computational load challenges that arise from simultaneous training on multiple datasets are addressed in Chapter 4. We propose two methodologies for selecting informative and diverse samples from datasets with weak supervision to reduce our networks' ecological footprint without sacrificing performance. Motivated by memory and computation efficiency requirements, in Chapter 5, we rethink simultaneous training on heterogeneous datasets and propose a universal semantic segmentation framework. This framework achieves consistent increases in performance metrics and semantic knowledgeability by exploiting various scene understanding datasets. Chapter 6 introduces the novel task of part-aware panoptic segmentation, which extends our reasoning towards holistic scene understanding. This task combines scene and parts-level semantics with instance-level object detection. In conclusion, our contributions span over convolutional network architectures, weakly-supervised learning, part and panoptic segmentation, paving the way towards a holistic, rich, and sustainable visual scene understanding.
Deep Adaptive Multi-Intention Inverse Reinforcement Learning
Jul 14, 2021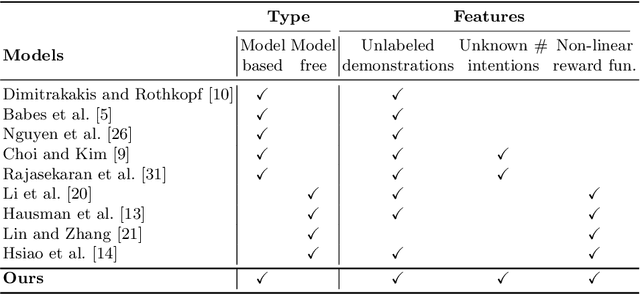
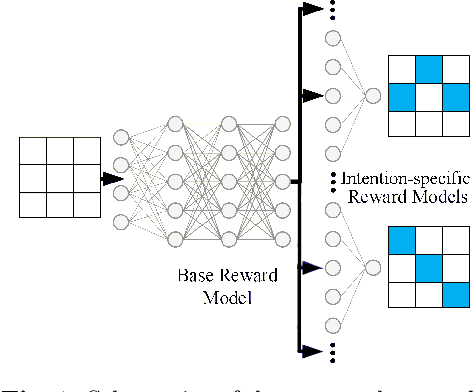
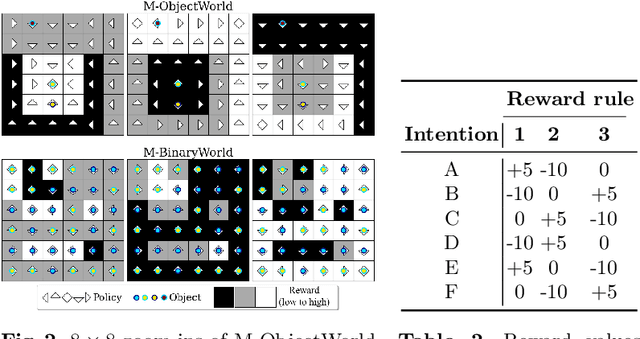

This paper presents a deep Inverse Reinforcement Learning (IRL) framework that can learn an a priori unknown number of nonlinear reward functions from unlabeled experts' demonstrations. For this purpose, we employ the tools from Dirichlet processes and propose an adaptive approach to simultaneously account for both complex and unknown number of reward functions. Using the conditional maximum entropy principle, we model the experts' multi-intention behaviors as a mixture of latent intention distributions and derive two algorithms to estimate the parameters of the deep reward network along with the number of experts' intentions from unlabeled demonstrations. The proposed algorithms are evaluated on three benchmarks, two of which have been specifically extended in this study for multi-intention IRL, and compared with well-known baselines. We demonstrate through several experiments the advantages of our algorithms over the existing approaches and the benefits of online inferring, rather than fixing beforehand, the number of expert's intentions.
Merging Tasks for Video Panoptic Segmentation
Jul 10, 2021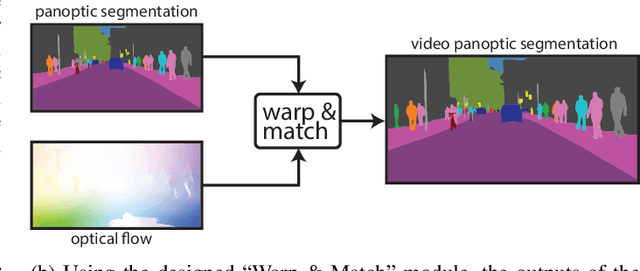
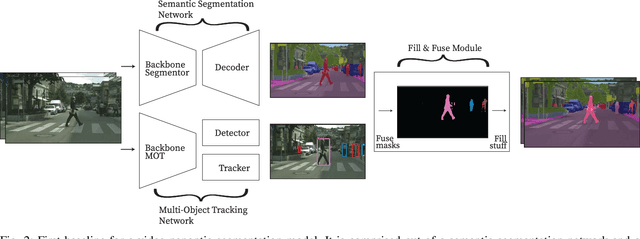


In this paper, the task of video panoptic segmentation is studied and two different methods to solve the task will be proposed. Video panoptic segmentation (VPS) is a recently introduced computer vision task that requires classifying and tracking every pixel in a given video. The nature of this task makes the cost of annotating datasets for it prohibiting. To understand video panoptic segmentation, first, earlier introduced constituent tasks that focus on semantics and tracking separately will be researched. Thereafter, two data-driven approaches which do not require training on a tailored VPS dataset will be selected to solve it. The first approach will show how a model for video panoptic segmentation can be built by heuristically fusing the outputs of a pre-trained semantic segmentation model and a pre-trained multi-object tracking model. This can be desired if one wants to easily extend the capabilities of either model. The second approach will counter some of the shortcomings of the first approach by building on top of a shared neural network backbone with task-specific heads. This network is designed for panoptic segmentation and will be extended by a mask propagation module to link instance masks across time, yielding the video panoptic segmentation format.
Part-aware Panoptic Segmentation
Jun 11, 2021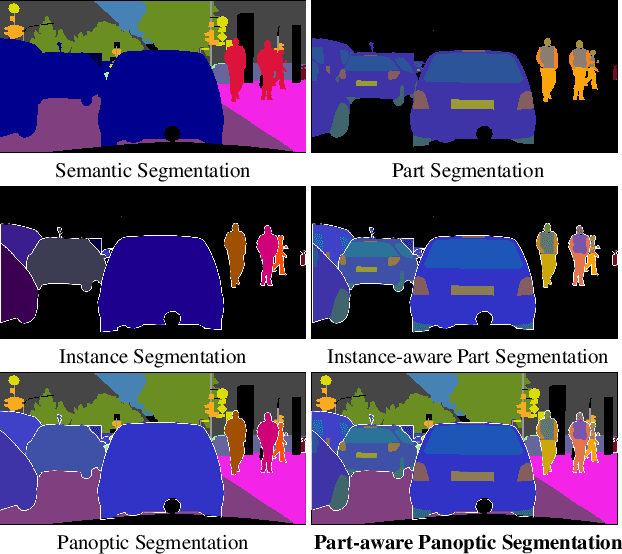
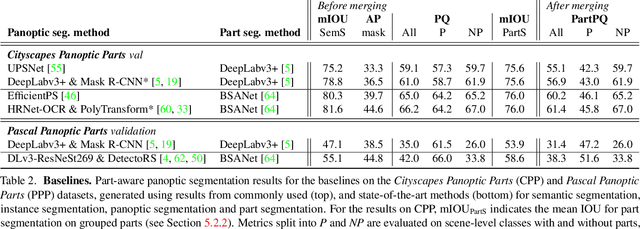
In this work, we introduce the new scene understanding task of Part-aware Panoptic Segmentation (PPS), which aims to understand a scene at multiple levels of abstraction, and unifies the tasks of scene parsing and part parsing. For this novel task, we provide consistent annotations on two commonly used datasets: Cityscapes and Pascal VOC. Moreover, we present a single metric to evaluate PPS, called Part-aware Panoptic Quality (PartPQ). For this new task, using the metric and annotations, we set multiple baselines by merging results of existing state-of-the-art methods for panoptic segmentation and part segmentation. Finally, we conduct several experiments that evaluate the importance of the different levels of abstraction in this single task.
Cityscapes-Panoptic-Parts and PASCAL-Panoptic-Parts datasets for Scene Understanding
Apr 16, 2020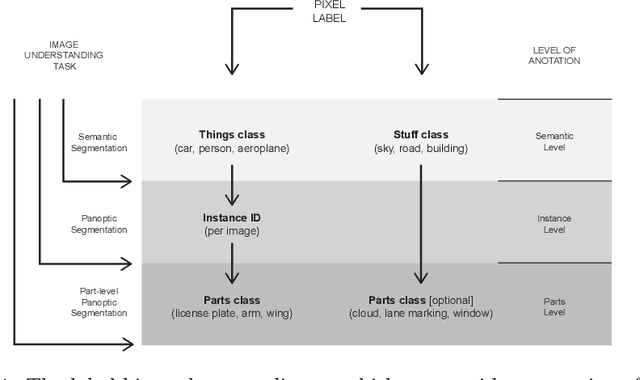
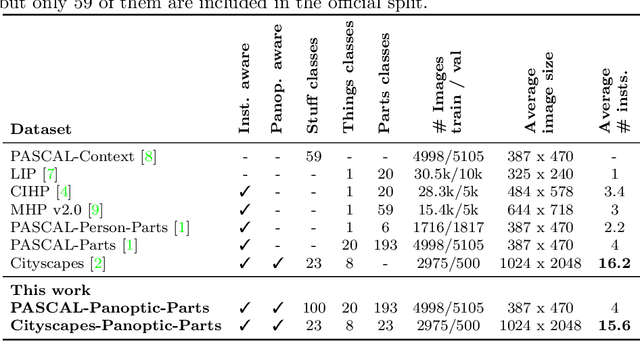

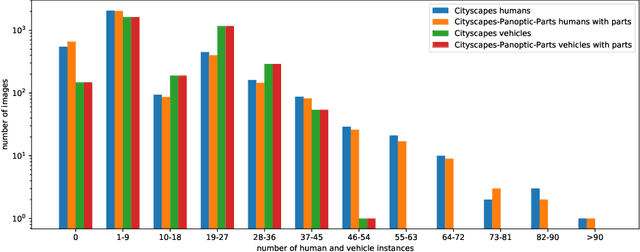
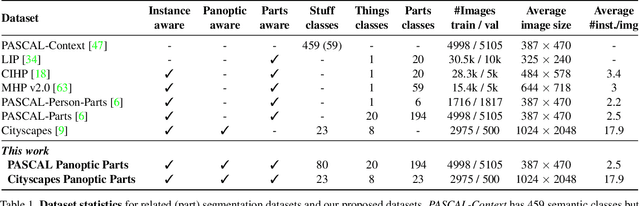
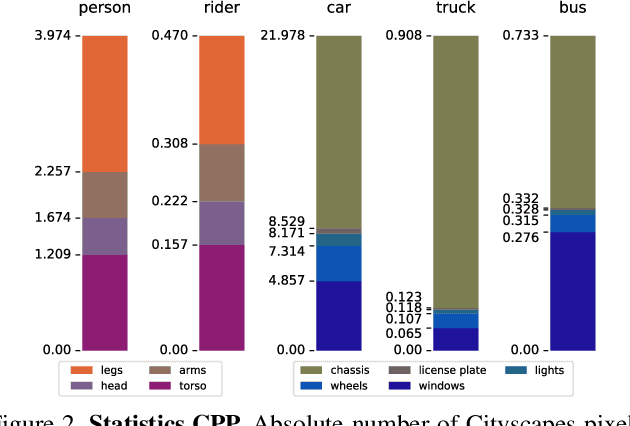
In this technical report, we present two novel datasets for image scene understanding. Both datasets have annotations compatible with panoptic segmentation and additionally they have part-level labels for selected semantic classes. This report describes the format of the two datasets, the annotation protocols, the merging strategies, and presents the datasets statistics. The datasets labels together with code for processing and visualization will be published at https://github.com/tue-mps/panoptic_parts.
Fast Panoptic Segmentation Network
Oct 09, 2019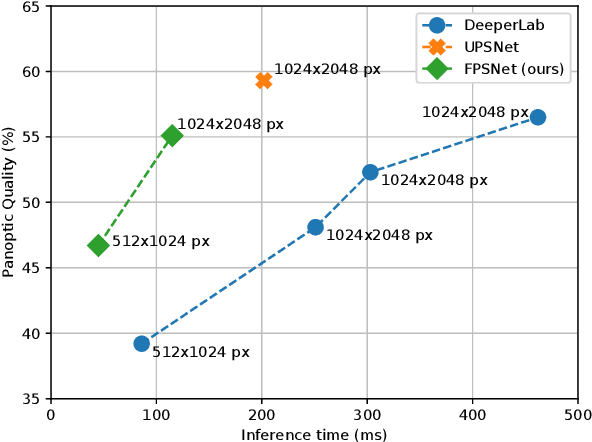
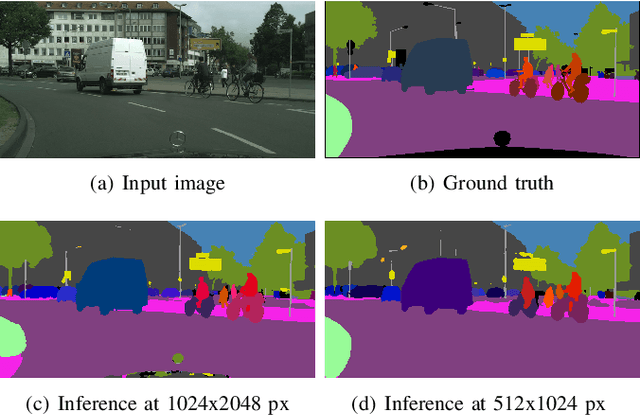
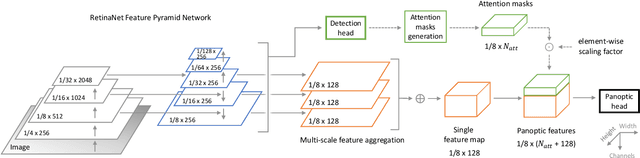
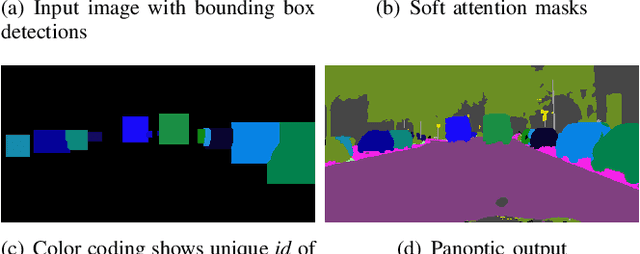
In this work, we present an end-to-end network for fast panoptic segmentation. This network, called Fast Panoptic Segmentation Network (FPSNet), does not require computationally costly instance mask predictions or merging heuristics. This is achieved by casting the panoptic task into a custom dense pixel-wise classification task, which assigns a class label or an instance id to each pixel. We evaluate FPSNet on the Cityscapes and Pascal VOC datasets, and find that FPSNet is faster than existing panoptic segmentation methods, while achieving better or similar panoptic segmentation performance. On the Cityscapes validation set, we achieve a Panoptic Quality score of 55.1%, at prediction times of 114 milliseconds for images with a resolution of 1024x2048 pixels. For lower resolutions of the Cityscapes dataset and for the Pascal VOC dataset, FPSNet runs at 22 and 35 frames per second, respectively.
Data Selection for training Semantic Segmentation CNNs with cross-dataset weak supervision
Jul 16, 2019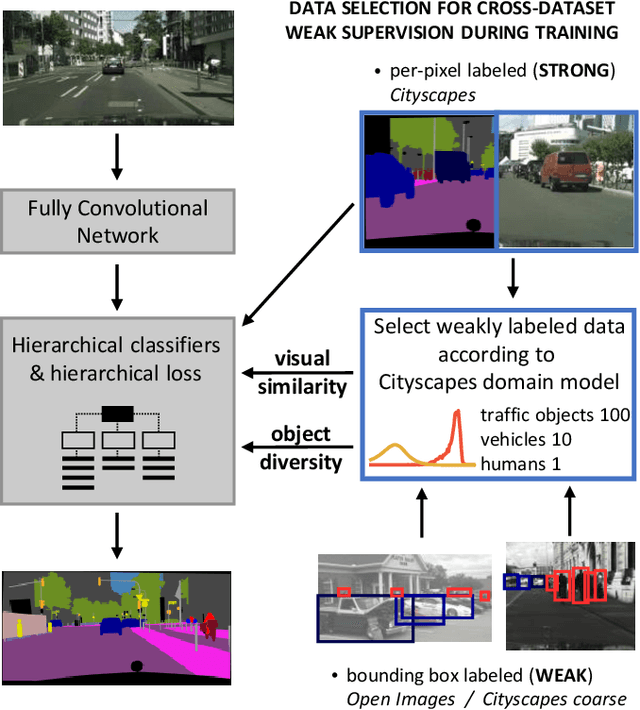

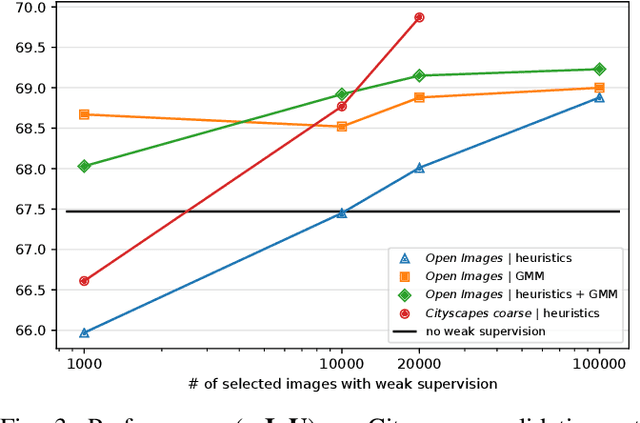
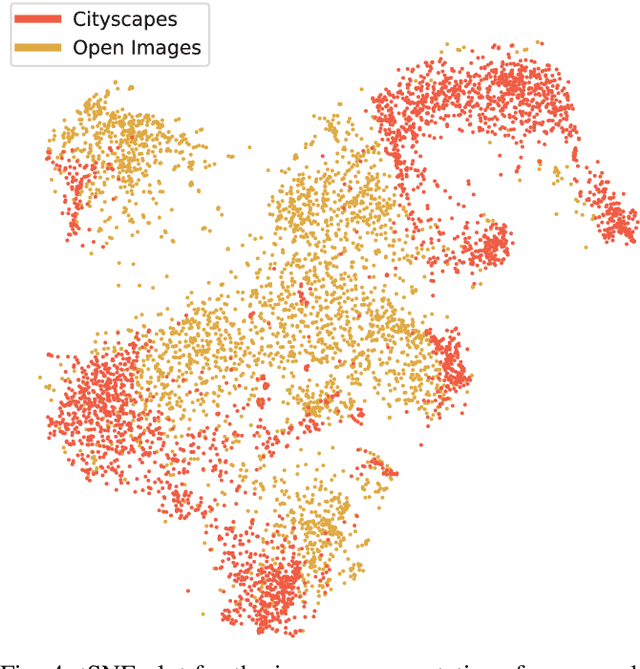
Training convolutional networks for semantic segmentation with strong (per-pixel) and weak (per-bounding-box) supervision requires a large amount of weakly labeled data. We propose two methods for selecting the most relevant data with weak supervision. The first method is designed for finding visually similar images without the need of labels and is based on modeling image representations with a Gaussian Mixture Model (GMM). As a byproduct of GMM modeling, we present useful insights on characterizing the data generating distribution. The second method aims at finding images with high object diversity and requires only the bounding box labels. Both methods are developed in the context of automated driving and experimentation is conducted on Cityscapes and Open Images datasets. We demonstrate performance gains by reducing the amount of employed weakly labeled images up to 100 times for Open Images and up to 20 times for Cityscapes.
On Boosting Semantic Street Scene Segmentation with Weak Supervision
Mar 08, 2019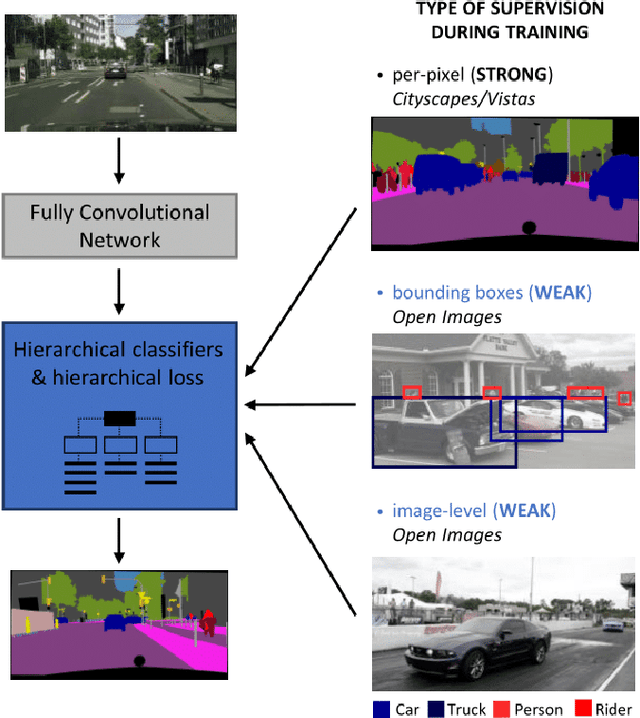
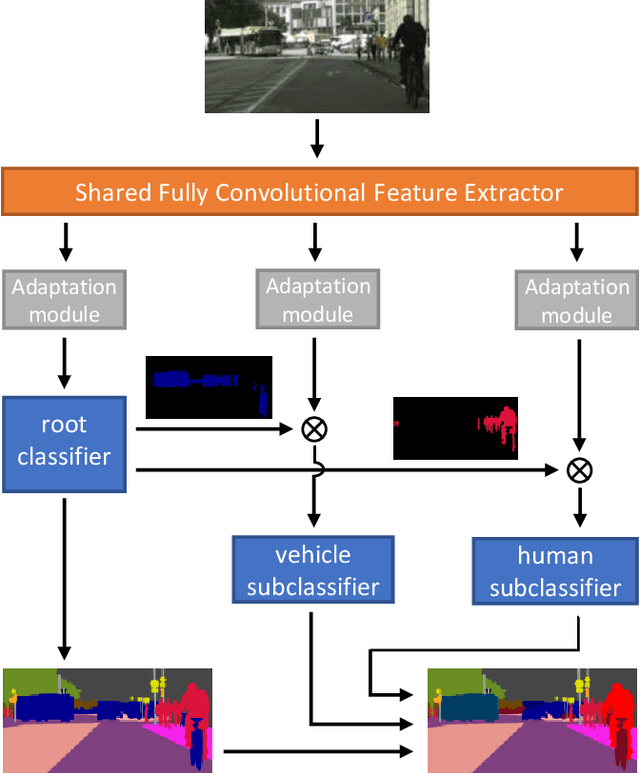

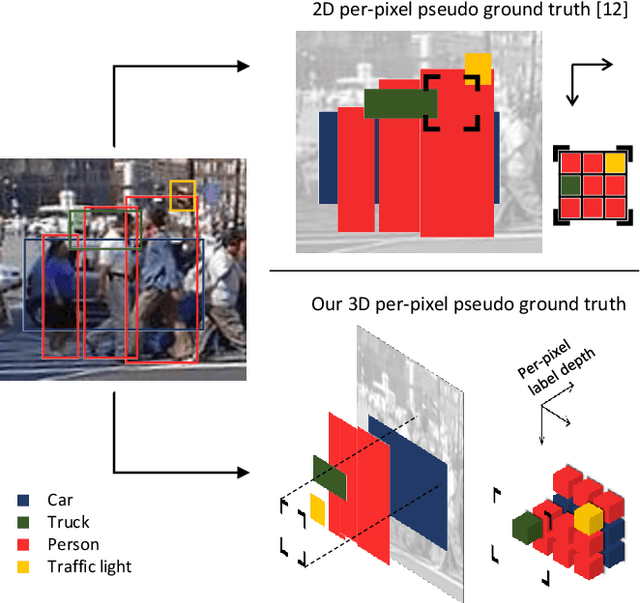
Training convolutional networks for semantic segmentation requires per-pixel ground truth labels, which are very time consuming and hence costly to obtain. Therefore, in this work, we research and develop a hierarchical deep network architecture and the corresponding loss for semantic segmentation that can be trained from weak supervision, such as bounding boxes or image level labels, as well as from strong per-pixel supervision. We demonstrate that the hierarchical structure and the simultaneous training on strong (per-pixel) and weak (bounding boxes) labels, even from separate datasets, constantly increases the performance against per-pixel only training. Moreover, we explore the more challenging case of adding weak image-level labels. We collect street scene images and weak labels from the immense Open Images dataset to generate the OpenScapes dataset, and we use this novel dataset to increase segmentation performance on two established per-pixel labeled datasets, Cityscapes and Vistas. We report performance gains up to +13.2% mIoU on crucial street scene classes, and inference speed of 20 fps on a Titan V GPU for Cityscapes at 512 x 1024 resolution. Our network and OpenScapes dataset are shared with the research community.
Single Network Panoptic Segmentation for Street Scene Understanding
Feb 07, 2019
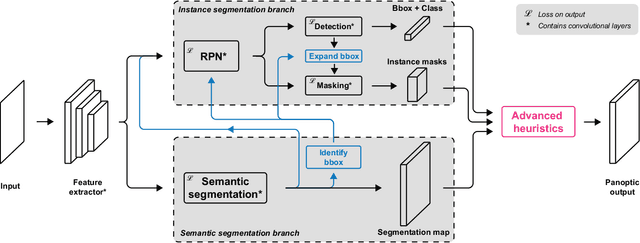
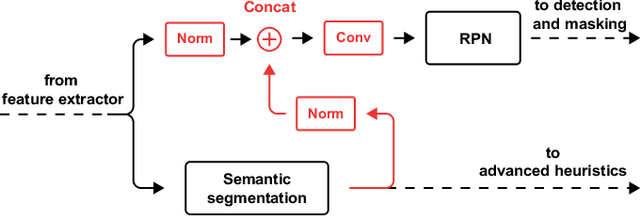
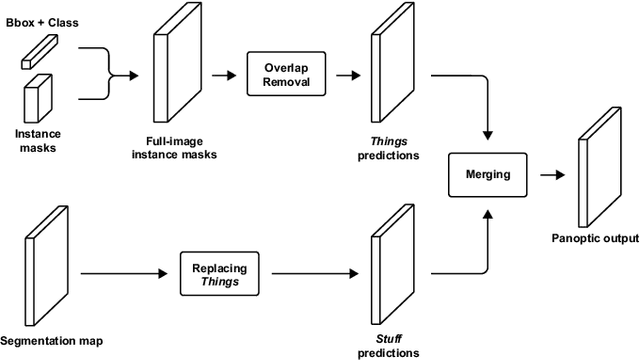
In this work, we propose a single deep neural network for panoptic segmentation, for which the goal is to provide each individual pixel of an input image with a class label, as in semantic segmentation, as well as a unique identifier for specific objects in an image, following instance segmentation. Our network makes joint semantic and instance segmentation predictions and combines these to form an output in the panoptic format. This has two main benefits: firstly, the entire panoptic prediction is made in one pass, reducing the required computation time and resources; secondly, by learning the tasks jointly, information is shared between the two tasks, thereby improving performance. Our network is evaluated on two street scene datasets: Cityscapes and Mapillary Vistas. By leveraging information exchange and improving the merging heuristics, we increase the performance of the single network, and achieve a score of 23.9 on the Panoptic Quality (PQ) metric on Mapillary Vistas validation, with an input resolution of 640 x 900 pixels. On Cityscapes validation, our method achieves a PQ score of 45.9 with an input resolution of 512 x 1024 pixels. Moreover, our method decreases the prediction time by a factor of 2 with respect to separate networks.