 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Boosting Semantic Street Scene Segmentation with Weak Supervision
Paper and Code
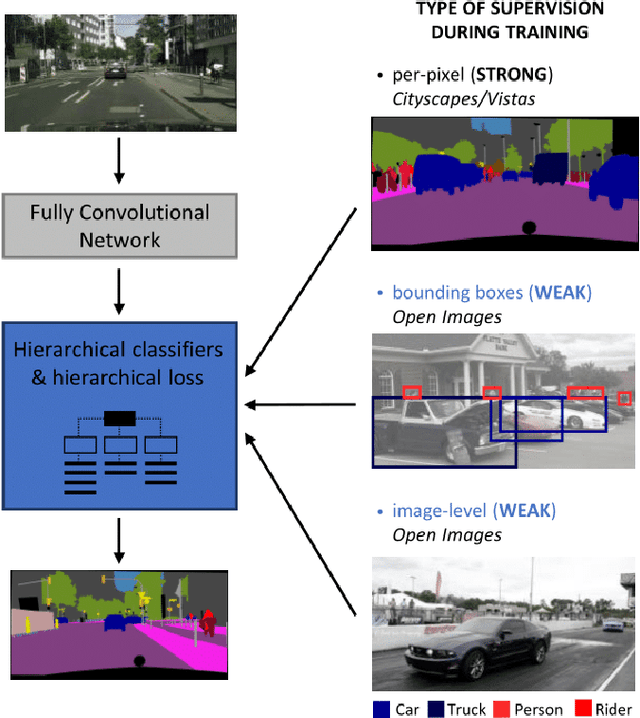
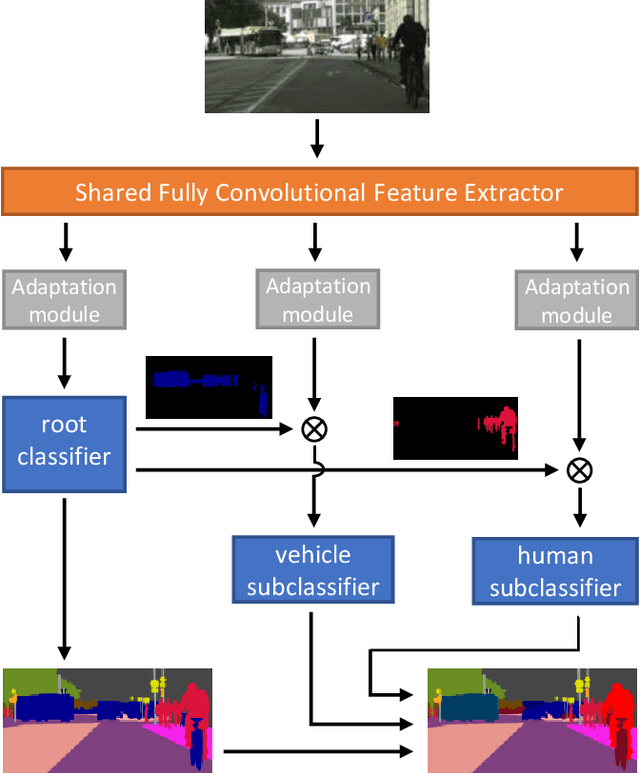

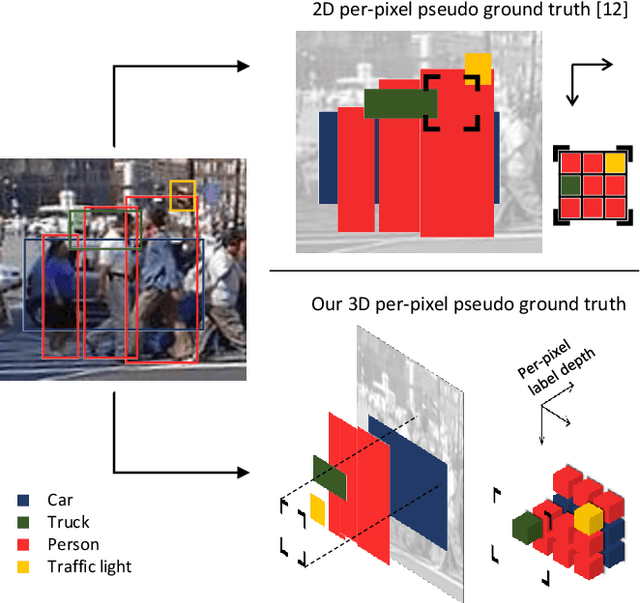
Training convolutional networks for semantic segmentation requires per-pixel ground truth labels, which are very time consuming and hence costly to obtain. Therefore, in this work, we research and develop a hierarchical deep network architecture and the corresponding loss for semantic segmentation that can be trained from weak supervision, such as bounding boxes or image level labels, as well as from strong per-pixel supervision. We demonstrate that the hierarchical structure and the simultaneous training on strong (per-pixel) and weak (bounding boxes) labels, even from separate datasets, constantly increases the performance against per-pixel only training. Moreover, we explore the more challenging case of adding weak image-level labels. We collect street scene images and weak labels from the immense Open Images dataset to generate the OpenScapes dataset, and we use this novel dataset to increase segmentation performance on two established per-pixel labeled datasets, Cityscapes and Vistas. We report performance gains up to +13.2% mIoU on crucial street scene classes, and inference speed of 20 fps on a Titan V GPU for Cityscapes at 512 x 1024 resolution. Our network and OpenScapes dataset are shared with the research community.