 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrivate PoEtry: Private In-Context Learning via Product of Experts
Feb 04, 2026In-context learning (ICL) enables Large Language Models (LLMs) to adapt to new tasks with only a small set of examples at inference time, thereby avoiding task-specific fine-tuning. However, in-context examples may contain privacy-sensitive information that should not be revealed through model outputs. Existing differential privacy (DP) approaches to ICL are either computationally expensive or rely on heuristics with limited effectiveness, including context oversampling, synthetic data generation, or unnecessary thresholding. We reformulate private ICL through the lens of a Product-of-Experts model. This gives a theoretically grounded framework, and the algorithm can be trivially parallelized. We evaluate our method across five datasets in text classification, math, and vision-language. We find that our method improves accuracy by more than 30 percentage points on average compared to prior DP-ICL methods, while maintaining strong privacy guarantees.
NoEsis: Differentially Private Knowledge Transfer in Modular LLM Adaptation
Apr 25, 2025Large Language Models (LLM) are typically trained on vast amounts of data from various sources. Even when designed modularly (e.g., Mixture-of-Experts), LLMs can leak privacy on their sources. Conversely, training such models in isolation arguably prohibits generalization. To this end, we propose a framework, NoEsis, which builds upon the desired properties of modularity, privacy, and knowledge transfer. NoEsis integrates differential privacy with a hybrid two-staged parameter-efficient fine-tuning that combines domain-specific low-rank adapters, acting as experts, with common prompt tokens, acting as a knowledge-sharing backbone. Results from our evaluation on CodeXGLUE showcase that NoEsis can achieve provable privacy guarantees with tangible knowledge transfer across domains, and empirically show protection against Membership Inference Attacks. Finally, on code completion tasks, NoEsis bridges at least 77% of the accuracy gap between the non-shared and the non-private baseline.
* ICLR 2025 MCDC workshop
DNA: Differentially private Neural Augmentation for contact tracing
Apr 20, 2024The COVID19 pandemic had enormous economic and societal consequences. Contact tracing is an effective way to reduce infection rates by detecting potential virus carriers early. However, this was not generally adopted in the recent pandemic, and privacy concerns are cited as the most important reason. We substantially improve the privacy guarantees of the current state of the art in decentralized contact tracing. Whereas previous work was based on statistical inference only, we augment the inference with a learned neural network and ensure that this neural augmentation satisfies differential privacy. In a simulator for COVID19, even at epsilon=1 per message, this can significantly improve the detection of potentially infected individuals and, as a result of targeted testing, reduce infection rates. This work marks an important first step in integrating deep learning into contact tracing while maintaining essential privacy guarantees.
Protect Your Score: Contact Tracing With Differential Privacy Guarantees
Dec 18, 2023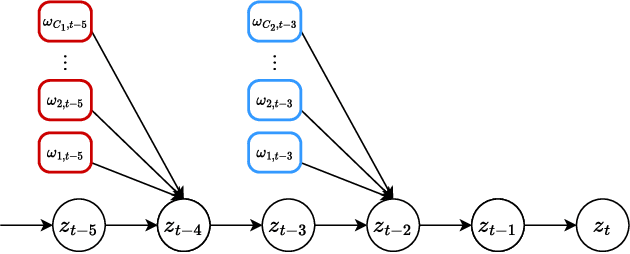
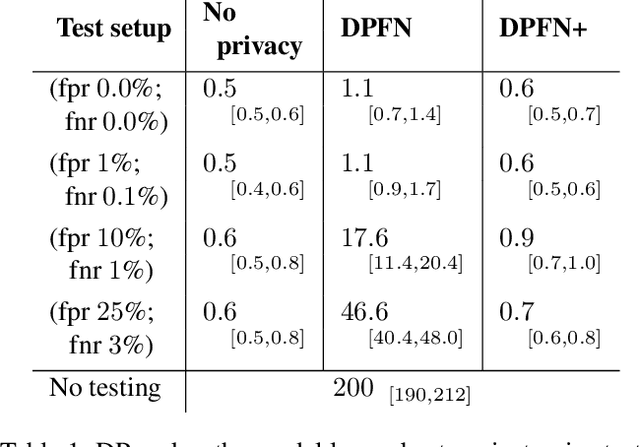
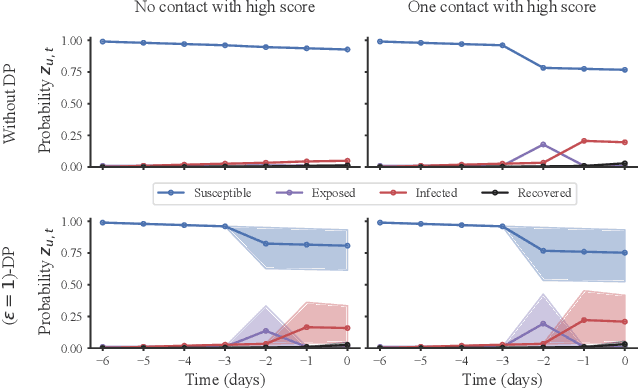

The pandemic in 2020 and 2021 had enormous economic and societal consequences, and studies show that contact tracing algorithms can be key in the early containment of the virus. While large strides have been made towards more effective contact tracing algorithms, we argue that privacy concerns currently hold deployment back. The essence of a contact tracing algorithm constitutes the communication of a risk score. Yet, it is precisely the communication and release of this score to a user that an adversary can leverage to gauge the private health status of an individual. We pinpoint a realistic attack scenario and propose a contact tracing algorithm with differential privacy guarantees against this attack. The algorithm is tested on the two most widely used agent-based COVID19 simulators and demonstrates superior performance in a wide range of settings. Especially for realistic test scenarios and while releasing each risk score with epsilon=1 differential privacy, we achieve a two to ten-fold reduction in the infection rate of the virus. To the best of our knowledge, this presents the first contact tracing algorithm with differential privacy guarantees when revealing risk scores for COVID19.
Beyond Transfer Learning: Co-finetuning for Action Localisation
Jul 08, 2022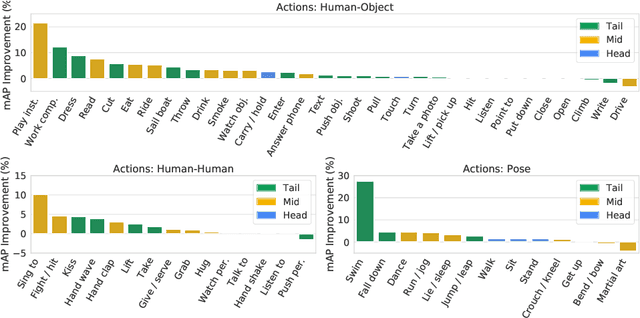
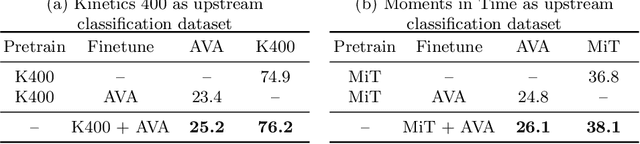
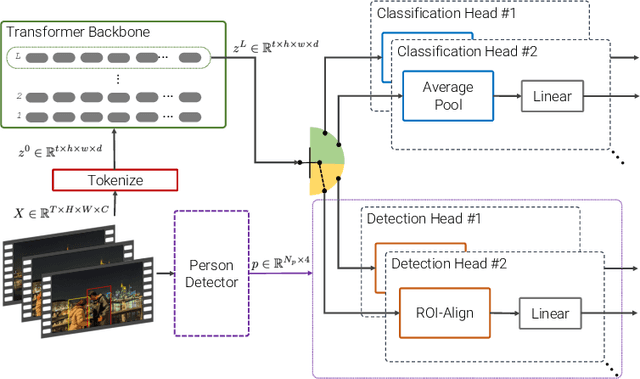

Transfer learning is the predominant paradigm for training deep networks on small target datasets. Models are typically pretrained on large ``upstream'' datasets for classification, as such labels are easy to collect, and then finetuned on ``downstream'' tasks such as action localisation, which are smaller due to their finer-grained annotations. In this paper, we question this approach, and propose co-finetuning -- simultaneously training a single model on multiple ``upstream'' and ``downstream'' tasks. We demonstrate that co-finetuning outperforms traditional transfer learning when using the same total amount of data, and also show how we can easily extend our approach to multiple ``upstream'' datasets to further improve performance. In particular, co-finetuning significantly improves the performance on rare classes in our downstream task, as it has a regularising effect, and enables the network to learn feature representations that transfer between different datasets. Finally, we observe how co-finetuning with public, video classification datasets, we are able to achieve state-of-the-art results for spatio-temporal action localisation on the challenging AVA and AVA-Kinetics datasets, outperforming recent works which develop intricate models.
Impact of Aliasing on Generalization in Deep Convolutional Networks
Aug 07, 2021

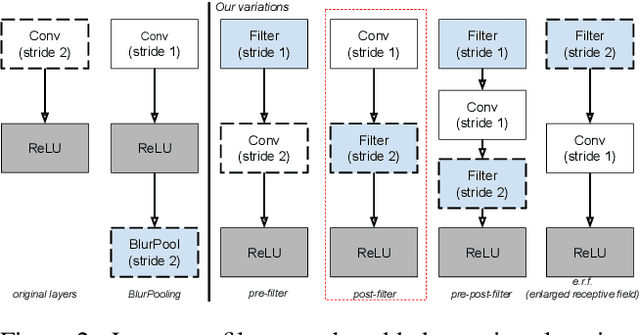
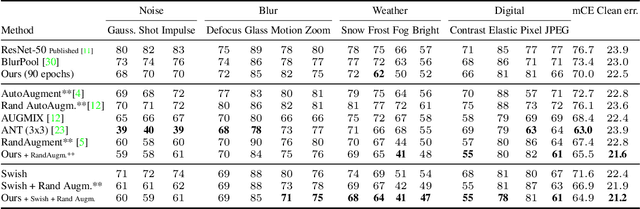
We investigate the impact of aliasing on generalization in Deep Convolutional Networks and show that data augmentation schemes alone are unable to prevent it due to structural limitations in widely used architectures. Drawing insights from frequency analysis theory, we take a closer look at ResNet and EfficientNet architectures and review the trade-off between aliasing and information loss in each of their major components. We show how to mitigate aliasing by inserting non-trainable low-pass filters at key locations, particularly where networks lack the capacity to learn them. These simple architectural changes lead to substantial improvements in generalization on i.i.d. and even more on out-of-distribution conditions, such as image classification under natural corruptions on ImageNet-C [11] and few-shot learning on Meta-Dataset [26]. State-of-the art results are achieved on both datasets without introducing additional trainable parameters and using the default hyper-parameters of open source codebases.
Revisiting the Calibration of Modern Neural Networks
Jun 15, 2021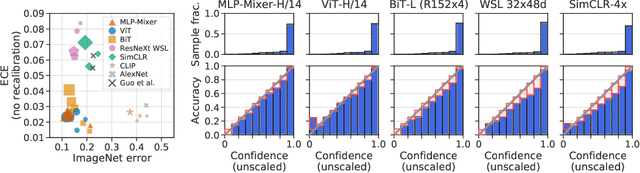

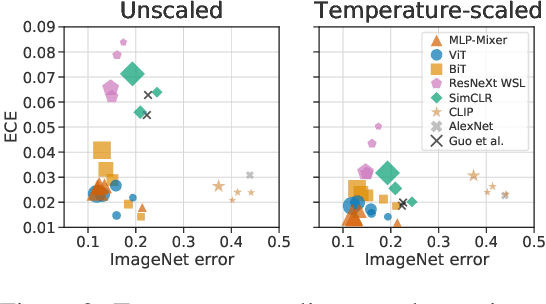
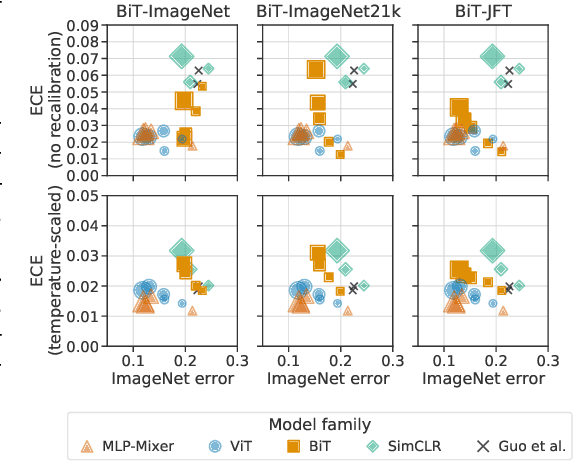
Accurate estimation of predictive uncertainty (model calibration) is essential for the safe application of neural networks. Many instances of miscalibration in modern neural networks have been reported, suggesting a trend that newer, more accurate models produce poorly calibrated predictions. Here, we revisit this question for recent state-of-the-art image classification models. We systematically relate model calibration and accuracy, and find that the most recent models, notably those not using convolutions, are among the best calibrated. Trends observed in prior model generations, such as decay of calibration with distribution shift or model size, are less pronounced in recent architectures. We also show that model size and amount of pretraining do not fully explain these differences, suggesting that architecture is a major determinant of calibration properties.
SI-Score: An image dataset for fine-grained analysis of robustness to object location, rotation and size
Apr 09, 2021

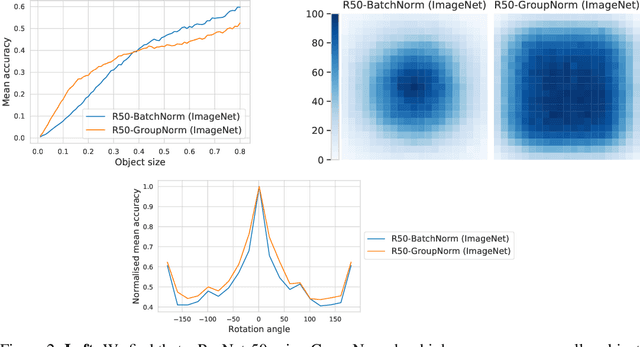

Before deploying machine learning models it is critical to assess their robustness. In the context of deep neural networks for image understanding, changing the object location, rotation and size may affect the predictions in non-trivial ways. In this work we perform a fine-grained analysis of robustness with respect to these factors of variation using SI-Score, a synthetic dataset. In particular, we investigate ResNets, Vision Transformers and CLIP, and identify interesting qualitative differences between these.
Representation learning from videos in-the-wild: An object-centric approach
Oct 06, 2020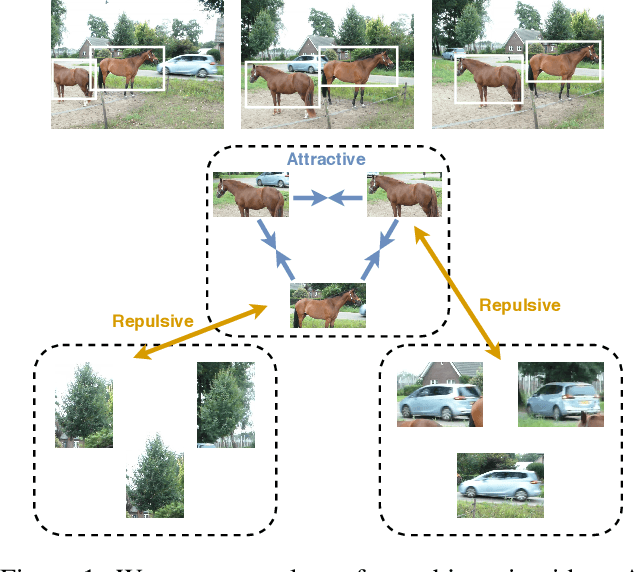
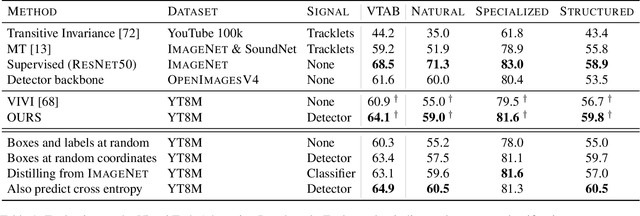

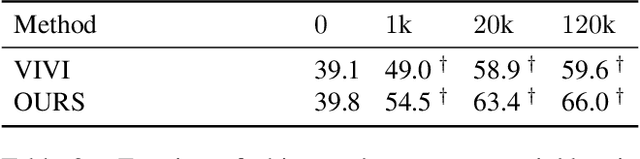
We propose a method to learn image representations from uncurated videos. We combine a supervised loss from off-the-shelf object detectors and self-supervised losses which naturally arise from the video-shot-frame-object hierarchy present in each video. We report competitive results on 19 transfer learning tasks of the Visual Task Adaptation Benchmark (VTAB), and on 8 out-of-distribution-generalization tasks, and discuss the benefits and shortcomings of the proposed approach. In particular, it improves over the baseline on all 18/19 few-shot learning tasks and 8/8 out-of-distribution generalization tasks. Finally, we perform several ablation studies and analyze the impact of the pretrained object detector on the performance across this suite of tasks.
On Robustness and Transferability of Convolutional Neural Networks
Jul 16, 2020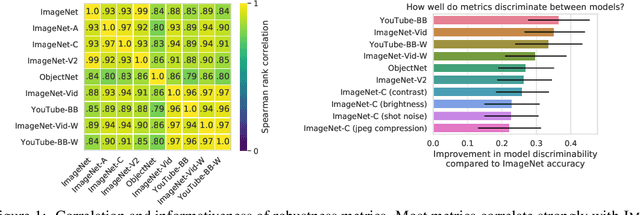

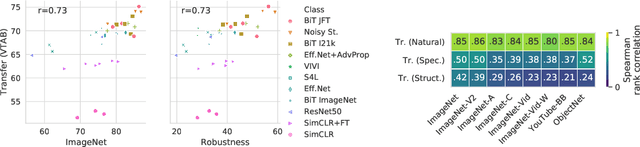
Modern deep convolutional networks (CNNs) are often criticized for not generalizing under distributional shifts. However, several recent breakthroughs in transfer learning suggest that these networks can cope with severe distribution shifts and successfully adapt to new tasks from a few training examples. In this work we revisit the out-of-distribution and transfer performance of modern image classification CNNs and investigate the impact of the pre-training data size, the model scale, and the data preprocessing pipeline. We find that increasing both the training set and model sizes significantly improve the distributional shift robustness. Furthermore, we show that, perhaps surprisingly, simple changes in the preprocessing such as modifying the image resolution can significantly mitigate robustness issues in some cases. Finally, we outline the shortcomings of existing robustness evaluation datasets and introduce a synthetic dataset we use for a systematic analysis across common factors of variation. \end{abstract}