 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Transfer Learning: Co-finetuning for Action Localisation
Paper and Code
Jul 08, 2022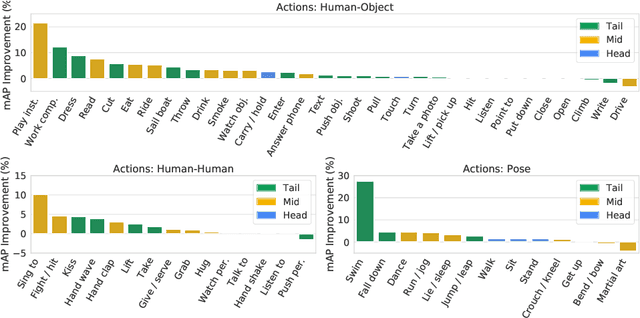
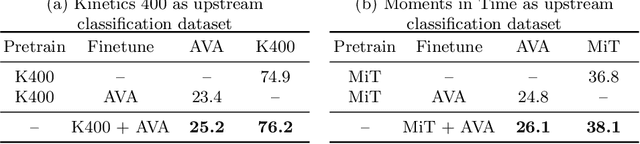
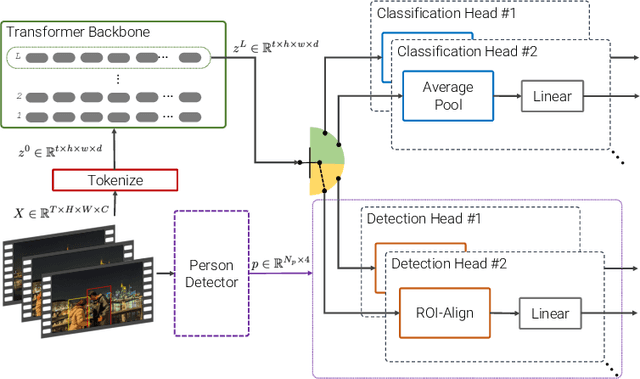

Transfer learning is the predominant paradigm for training deep networks on small target datasets. Models are typically pretrained on large ``upstream'' datasets for classification, as such labels are easy to collect, and then finetuned on ``downstream'' tasks such as action localisation, which are smaller due to their finer-grained annotations. In this paper, we question this approach, and propose co-finetuning -- simultaneously training a single model on multiple ``upstream'' and ``downstream'' tasks. We demonstrate that co-finetuning outperforms traditional transfer learning when using the same total amount of data, and also show how we can easily extend our approach to multiple ``upstream'' datasets to further improve performance. In particular, co-finetuning significantly improves the performance on rare classes in our downstream task, as it has a regularising effect, and enables the network to learn feature representations that transfer between different datasets. Finally, we observe how co-finetuning with public, video classification datasets, we are able to achieve state-of-the-art results for spatio-temporal action localisation on the challenging AVA and AVA-Kinetics datasets, outperforming recent works which develop intricate models.