 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTeNet: Text-to-Network for Compact Policy Synthesis
Jan 22, 2026Robots that follow natural-language instructions often either plan at a high level using hand-designed interfaces or rely on large end-to-end models that are difficult to deploy for real-time control. We propose TeNet (Text-to-Network), a framework for instantiating compact, task-specific robot policies directly from natural language descriptions. TeNet conditions a hypernetwork on text embeddings produced by a pretrained large language model (LLM) to generate a fully executable policy, which then operates solely on low-dimensional state inputs at high control frequencies. By using the language only once at the policy instantiation time, TeNet inherits the general knowledge and paraphrasing robustness of pretrained LLMs while remaining lightweight and efficient at execution time. To improve generalization, we optionally ground language in behavior during training by aligning text embeddings with demonstrated actions, while requiring no demonstrations at inference time. Experiments on MuJoCo and Meta-World benchmarks show that TeNet produces policies that are orders of magnitude smaller than sequence-based baselines, while achieving strong performance in both multi-task and meta-learning settings and supporting high-frequency control. These results show that text-conditioned hypernetworks offer a practical way to build compact, language-driven controllers for ressource-constrained robot control tasks with real-time requirements.
Policy Space Response Oracles: A Survey
Mar 04, 2024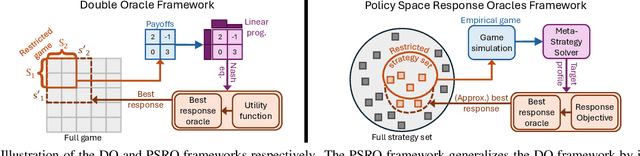

In game theory, a game refers to a model of interaction among rational decision-makers or players, making choices with the goal of achieving their individual objectives. Understanding their behavior in games is often referred to as game reasoning. This survey provides a comprehensive overview of a fast-developing game-reasoning framework for large games, known as Policy Space Response Oracles (PSRO). We first motivate PSRO, provide historical context, and position PSRO within game-reasoning approaches. We then focus on the strategy exploration issue for PSRO, the challenge of assembling an effective strategy portfolio for modeling the underlying game with minimum computational cost. We also survey current research directions for enhancing the efficiency of PSRO, and explore the applications of PSRO across various domains. We conclude by discussing open questions and future research.
Off-Policy Action Anticipation in Multi-Agent Reinforcement Learning
Apr 04, 2023



Learning anticipation in Multi-Agent Reinforcement Learning (MARL) is a reasoning paradigm where agents anticipate the learning steps of other agents to improve cooperation among themselves. As MARL uses gradient-based optimization, learning anticipation requires using Higher-Order Gradients (HOG), with so-called HOG methods. Existing HOG methods are based on policy parameter anticipation, i.e., agents anticipate the changes in policy parameters of other agents. Currently, however, these existing HOG methods have only been applied to differentiable games or games with small state spaces. In this work, we demonstrate that in the case of non-differentiable games with large state spaces, existing HOG methods do not perform well and are inefficient due to their inherent limitations related to policy parameter anticipation and multiple sampling stages. To overcome these problems, we propose Off-Policy Action Anticipation (OffPA2), a novel framework that approaches learning anticipation through action anticipation, i.e., agents anticipate the changes in actions of other agents, via off-policy sampling. We theoretically analyze our proposed OffPA2 and employ it to develop multiple HOG methods that are applicable to non-differentiable games with large state spaces. We conduct a large set of experiments and illustrate that our proposed HOG methods outperform the existing ones regarding efficiency and performance.
Deep Adaptive Multi-Intention Inverse Reinforcement Learning
Jul 14, 2021
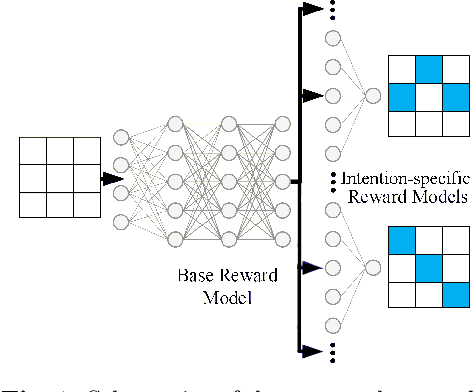
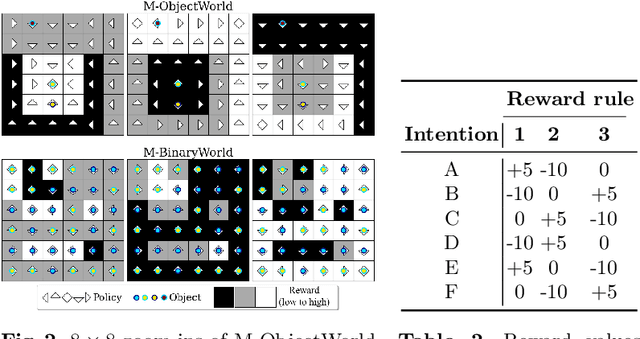

This paper presents a deep Inverse Reinforcement Learning (IRL) framework that can learn an a priori unknown number of nonlinear reward functions from unlabeled experts' demonstrations. For this purpose, we employ the tools from Dirichlet processes and propose an adaptive approach to simultaneously account for both complex and unknown number of reward functions. Using the conditional maximum entropy principle, we model the experts' multi-intention behaviors as a mixture of latent intention distributions and derive two algorithms to estimate the parameters of the deep reward network along with the number of experts' intentions from unlabeled demonstrations. The proposed algorithms are evaluated on three benchmarks, two of which have been specifically extended in this study for multi-intention IRL, and compared with well-known baselines. We demonstrate through several experiments the advantages of our algorithms over the existing approaches and the benefits of online inferring, rather than fixing beforehand, the number of expert's intentions.