 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan LLMs Beat Classical Hyperparameter Optimization Algorithms? A Study on autoresearch
Mar 25, 2026The autoresearch repository enables an LLM agent to search for optimal hyperparameter configurations on an unconstrained search space by editing the training code directly. Given a fixed compute budget and constraints, we use \emph{autoresearch} as a testbed to compare classical hyperparameter optimization (HPO) algorithms against LLM-based methods on tuning the hyperparameters of a small language model. Within a fixed hyperparameter search space, classical HPO methods such as CMA-ES and TPE consistently outperform LLM-based agents. However, an LLM agent that directly edits training source code in an unconstrained search space narrows the gap to classical methods substantially despite using only a self-hosted open-weight 27B model. Methods that avoid out-of-memory failures outperform those with higher search diversity, suggesting that reliability matters more than exploration breadth. While small and mid-sized LLMs struggle to track optimization state across trials, classical methods lack domain knowledge. To bridge this gap, we introduce Centaur, a hybrid that shares CMA-ES's internal state, including mean vector, step-size, and covariance matrix, with an LLM. Centaur achieves the best result in our experiments, with its 0.8B variant outperforming the 27B variant, suggesting that a cheap LLM suffices when paired with a strong classical optimizer. The 0.8B model is insufficient for unconstrained code editing but sufficient for hybrid optimization, while scaling to 27B provides no advantage for fixed search space methods with the open-weight models tested. Code is available at https://github.com/ferreirafabio/autoresearch-automl.
Multi-Objective Hierarchical Optimization with Large Language Models
Jan 20, 2026Despite their widespread adoption in various domains, especially due to their powerful reasoning capabilities, Large Language Models (LLMs) are not the off-the-shelf choice to drive multi-objective optimization yet. Conventional strategies rank high in benchmarks due to their intrinsic capabilities to handle numerical inputs and careful modelling choices that balance exploration and Pareto-front exploitation, as well as handle multiple (conflicting) objectives. In this paper, we close this gap by leveraging LLMs as surrogate models and candidate samplers inside a structured hierarchical search strategy. By adaptively partitioning the input space into disjoint hyperrectangular regions and ranking them with a composite score function, we restrict the generative process of the LLM to specific, high-potential sub-spaces, hence making the problem easier to solve as the LLM doesn't have to reason about the global structure of the problem, but only locally instead. We show that under standard regularity assumptions, our algorithm generates candidate solutions that converge to the true Pareto set in Hausdorff distance. Empirically, it consistently outperforms the global LLM-based multi-objective optimizer and is on par with standard evolutionary and Bayesian optimization algorithm on synthetic and real-world benchmarks.
Improving LLM-based Global Optimization with Search Space Partitioning
May 27, 2025



Large Language Models (LLMs) have recently emerged as effective surrogate models and candidate generators within global optimization frameworks for expensive blackbox functions. Despite promising results, LLM-based methods often struggle in high-dimensional search spaces or when lacking domain-specific priors, leading to sparse or uninformative suggestions. To overcome these limitations, we propose HOLLM, a novel global optimization algorithm that enhances LLM-driven sampling by partitioning the search space into promising subregions. Each subregion acts as a ``meta-arm'' selected via a bandit-inspired scoring mechanism that effectively balances exploration and exploitation. Within each selected subregion, an LLM then proposes high-quality candidate points, without any explicit domain knowledge. Empirical evaluation on standard optimization benchmarks shows that HOLLM consistently matches or surpasses leading Bayesian optimization and trust-region methods, while substantially outperforming global LLM-based sampling strategies.
Unlocking State-Tracking in Linear RNNs Through Negative Eigenvalues
Nov 19, 2024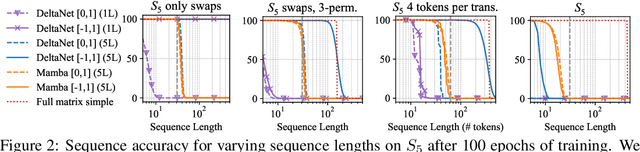
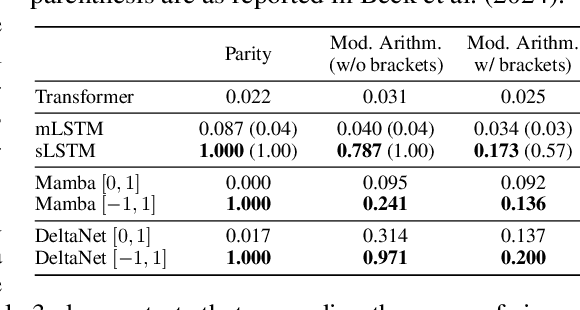
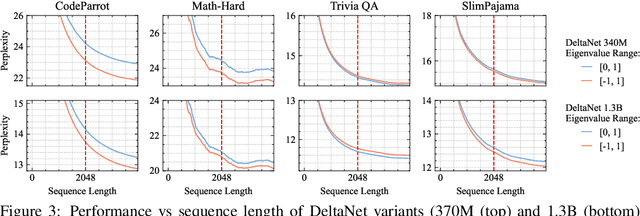
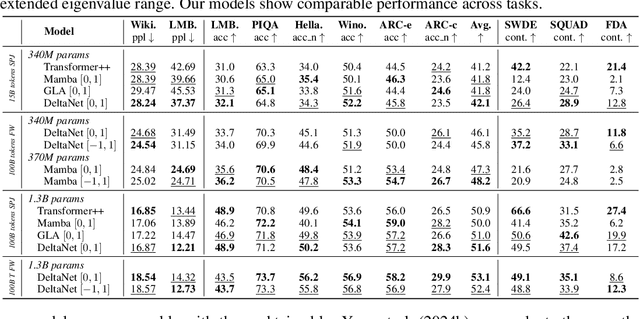
Linear Recurrent Neural Networks (LRNNs) such as Mamba, RWKV, GLA, mLSTM, and DeltaNet have emerged as efficient alternatives to Transformers in large language modeling, offering linear scaling with sequence length and improved training efficiency. However, LRNNs struggle to perform state-tracking which may impair performance in tasks such as code evaluation or tracking a chess game. Even parity, the simplest state-tracking task, which non-linear RNNs like LSTM handle effectively, cannot be solved by current LRNNs. Recently, Sarrof et al. (2024) demonstrated that the failure of LRNNs like Mamba to solve parity stems from restricting the value range of their diagonal state-transition matrices to $[0, 1]$ and that incorporating negative values can resolve this issue. We extend this result to non-diagonal LRNNs, which have recently shown promise in models such as DeltaNet. We prove that finite precision LRNNs with state-transition matrices having only positive eigenvalues cannot solve parity, while complex eigenvalues are needed to count modulo $3$. Notably, we also prove that LRNNs can learn any regular language when their state-transition matrices are products of identity minus vector outer product matrices, each with eigenvalues in the range $[-1, 1]$. Our empirical results confirm that extending the eigenvalue range of models like Mamba and DeltaNet to include negative values not only enables them to solve parity but consistently improves their performance on state-tracking tasks. Furthermore, pre-training LRNNs with an extended eigenvalue range for language modeling achieves comparable performance and stability while showing promise on code and math data. Our work enhances the expressivity of modern LRNNs, broadening their applicability without changing the cost of training or inference.
Ensembling Finetuned Language Models for Text Classification
Oct 25, 2024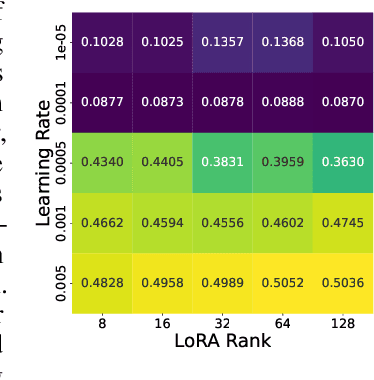

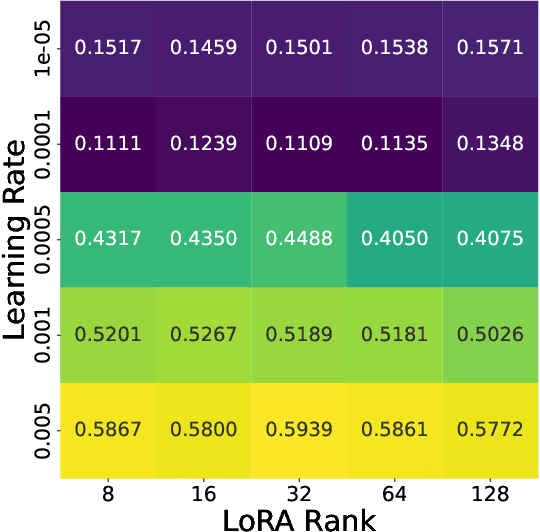
Finetuning is a common practice widespread across different communities to adapt pretrained models to particular tasks. Text classification is one of these tasks for which many pretrained models are available. On the other hand, ensembles of neural networks are typically used to boost performance and provide reliable uncertainty estimates. However, ensembling pretrained models for text classification is not a well-studied avenue. In this paper, we present a metadataset with predictions from five large finetuned models on six datasets, and report results of different ensembling strategies from these predictions. Our results shed light on how ensembling can improve the performance of finetuned text classifiers and incentivize future adoption of ensembles in such tasks.
GAMformer: In-Context Learning for Generalized Additive Models
Oct 06, 2024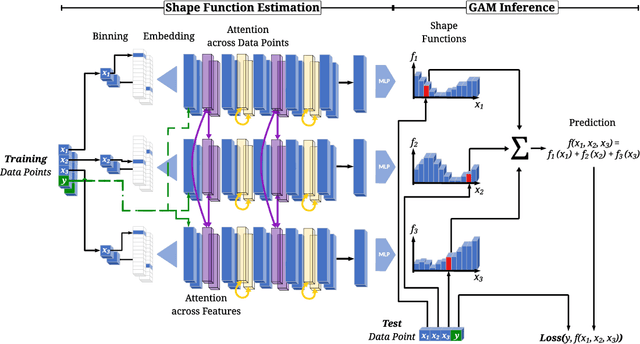
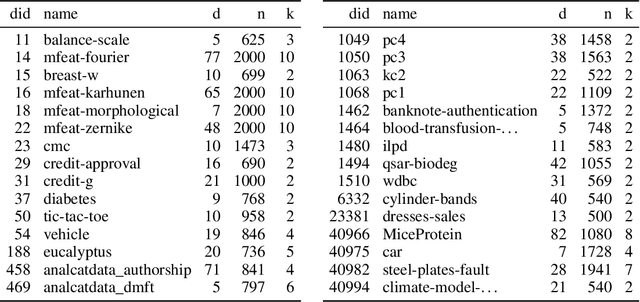
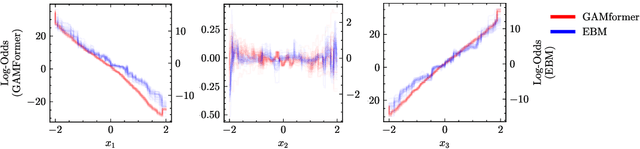

Generalized Additive Models (GAMs) are widely recognized for their ability to create fully interpretable machine learning models for tabular data. Traditionally, training GAMs involves iterative learning algorithms, such as splines, boosted trees, or neural networks, which refine the additive components through repeated error reduction. In this paper, we introduce GAMformer, the first method to leverage in-context learning to estimate shape functions of a GAM in a single forward pass, representing a significant departure from the conventional iterative approaches to GAM fitting. Building on previous research applying in-context learning to tabular data, we exclusively use complex, synthetic data to train GAMformer, yet find it extrapolates well to real-world data. Our experiments show that GAMformer performs on par with other leading GAMs across various classification benchmarks while generating highly interpretable shape functions.
Dynamic Post-Hoc Neural Ensemblers
Oct 06, 2024



Ensemble methods are known for enhancing the accuracy and robustness of machine learning models by combining multiple base learners. However, standard approaches like greedy or random ensembles often fall short, as they assume a constant weight across samples for the ensemble members. This can limit expressiveness and hinder performance when aggregating the ensemble predictions. In this study, we explore employing neural networks as ensemble methods, emphasizing the significance of dynamic ensembling to leverage diverse model predictions adaptively. Motivated by the risk of learning low-diversity ensembles, we propose regularizing the model by randomly dropping base model predictions during the training. We demonstrate this approach lower bounds the diversity within the ensemble, reducing overfitting and improving generalization capabilities. Our experiments showcase that the dynamic neural ensemblers yield competitive results compared to strong baselines in computer vision, natural language processing, and tabular data.
HW-GPT-Bench: Hardware-Aware Architecture Benchmark for Language Models
May 16, 2024The expanding size of language models has created the necessity for a comprehensive examination across various dimensions that reflect the desiderata with respect to the tradeoffs between various hardware metrics, such as latency, energy consumption, GPU memory usage, and performance. There is a growing interest in establishing Pareto frontiers for different language model configurations to identify optimal models with specified hardware constraints. Notably, architectures that excel in latency on one device may not perform optimally on another. However, exhaustive training and evaluation of numerous architectures across diverse hardware configurations is computationally prohibitive. To this end, we propose HW-GPT-Bench, a hardware-aware language model surrogate benchmark, where we leverage weight-sharing techniques from Neural Architecture Search (NAS) to efficiently train a supernet proxy, encompassing language models of varying scales in a single model. We conduct profiling of these models across 13 devices, considering 5 hardware metrics and 3 distinct model scales. Finally, we showcase the usability of HW-GPT-Bench using 8 different multi-objective NAS algorithms and evaluate the quality of the resultant Pareto fronts. Through this benchmark, our objective is to propel and expedite research in the advancement of multi-objective methods for NAS and structural pruning in large language models.
Multi-objective Differentiable Neural Architecture Search
Feb 28, 2024Pareto front profiling in multi-objective optimization (MOO), i.e. finding a diverse set of Pareto optimal solutions, is challenging, especially with expensive objectives like neural network training. Typically, in MOO neural architecture search (NAS), we aim to balance performance and hardware metrics across devices. Prior NAS approaches simplify this task by incorporating hardware constraints into the objective function, but profiling the Pareto front necessitates a search for each constraint. In this work, we propose a novel NAS algorithm that encodes user preferences for the trade-off between performance and hardware metrics, and yields representative and diverse architectures across multiple devices in just one search run. To this end, we parameterize the joint architectural distribution across devices and multiple objectives via a hypernetwork that can be conditioned on hardware features and preference vectors, enabling zero-shot transferability to new devices. Extensive experiments with up to 19 hardware devices and 3 objectives showcase the effectiveness and scalability of our method. Finally, we show that, without additional costs, our method outperforms existing MOO NAS methods across qualitatively different search spaces and datasets, including MobileNetV3 on ImageNet-1k and a Transformer space on machine translation.
Neural Architecture Search: Insights from 1000 Papers
Jan 25, 2023



In the past decade, advances in deep learning have resulted in breakthroughs in a variety of areas, including computer vision, natural language understanding, speech recognition, and reinforcement learning. Specialized, high-performing neural architectures are crucial to the success of deep learning in these areas. Neural architecture search (NAS), the process of automating the design of neural architectures for a given task, is an inevitable next step in automating machine learning and has already outpaced the best human-designed architectures on many tasks. In the past few years, research in NAS has been progressing rapidly, with over 1000 papers released since 2020 (Deng and Lindauer, 2021). In this survey, we provide an organized and comprehensive guide to neural architecture search. We give a taxonomy of search spaces, algorithms, and speedup techniques, and we discuss resources such as benchmarks, best practices, other surveys, and open-source libraries.