 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Architecture Search: Insights from 1000 Papers
Jan 25, 2023



In the past decade, advances in deep learning have resulted in breakthroughs in a variety of areas, including computer vision, natural language understanding, speech recognition, and reinforcement learning. Specialized, high-performing neural architectures are crucial to the success of deep learning in these areas. Neural architecture search (NAS), the process of automating the design of neural architectures for a given task, is an inevitable next step in automating machine learning and has already outpaced the best human-designed architectures on many tasks. In the past few years, research in NAS has been progressing rapidly, with over 1000 papers released since 2020 (Deng and Lindauer, 2021). In this survey, we provide an organized and comprehensive guide to neural architecture search. We give a taxonomy of search spaces, algorithms, and speedup techniques, and we discuss resources such as benchmarks, best practices, other surveys, and open-source libraries.
Towards Discovering Neural Architectures from Scratch
Nov 03, 2022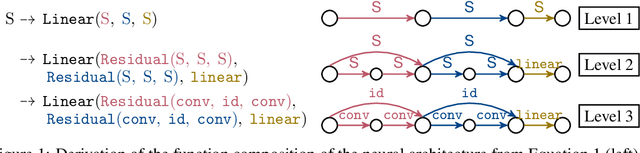
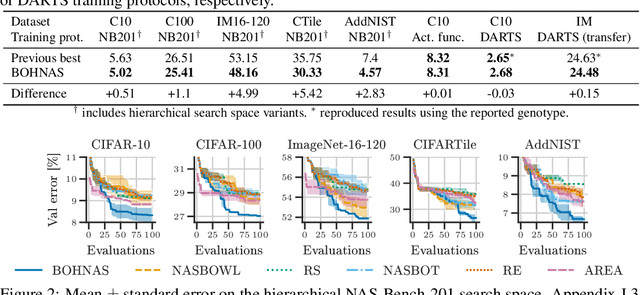
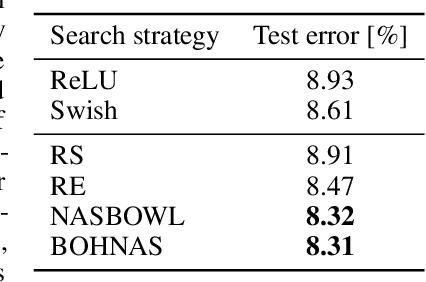
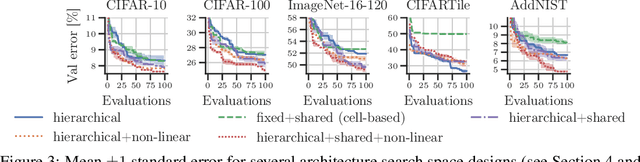
The discovery of neural architectures from scratch is the long-standing goal of Neural Architecture Search (NAS). Searching over a wide spectrum of neural architectures can facilitate the discovery of previously unconsidered but well-performing architectures. In this work, we take a large step towards discovering neural architectures from scratch by expressing architectures algebraically. This algebraic view leads to a more general method for designing search spaces, which allows us to compactly represent search spaces that are 100s of orders of magnitude larger than common spaces from the literature. Further, we propose a Bayesian Optimization strategy to efficiently search over such huge spaces, and demonstrate empirically that both our search space design and our search strategy can be superior to existing baselines. We open source our algebraic NAS approach and provide APIs for PyTorch and TensorFlow.
On the Importance of Architectures and Hyperparameters for Fairness in Face Recognition
Oct 18, 2022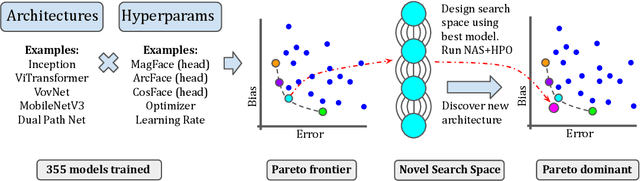

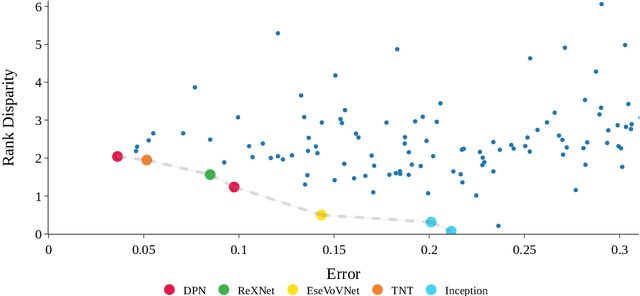

Face recognition systems are deployed across the world by government agencies and contractors for sensitive and impactful tasks, such as surveillance and database matching. Despite their widespread use, these systems are known to exhibit bias across a range of sociodemographic dimensions, such as gender and race. Nonetheless, an array of works proposing pre-processing, training, and post-processing methods have failed to close these gaps. Here, we take a very different approach to this problem, identifying that both architectures and hyperparameters of neural networks are instrumental in reducing bias. We first run a large-scale analysis of the impact of architectures and training hyperparameters on several common fairness metrics and show that the implicit convention of choosing high-accuracy architectures may be suboptimal for fairness. Motivated by our findings, we run the first neural architecture search for fairness, jointly with a search for hyperparameters. We output a suite of models which Pareto-dominate all other competitive architectures in terms of accuracy and fairness. Furthermore, we show that these models transfer well to other face recognition datasets with similar and distinct protected attributes. We release our code and raw result files so that researchers and practitioners can replace our fairness metrics with a bias measure of their choice.
Anaphora and Coreference Resolution: A Review
May 30, 2018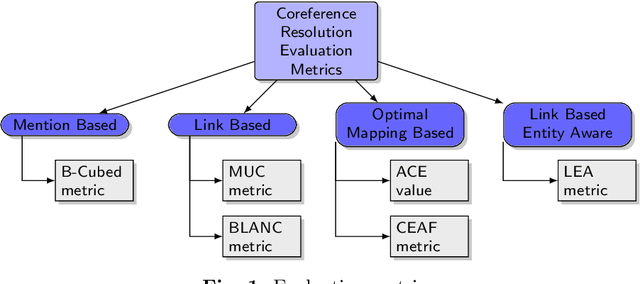
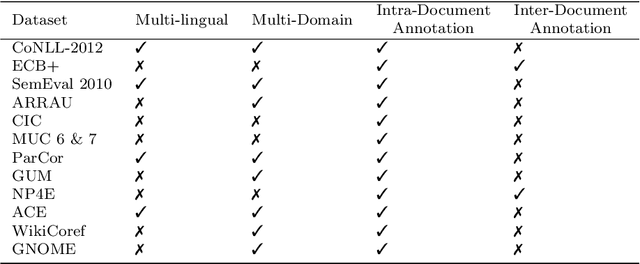
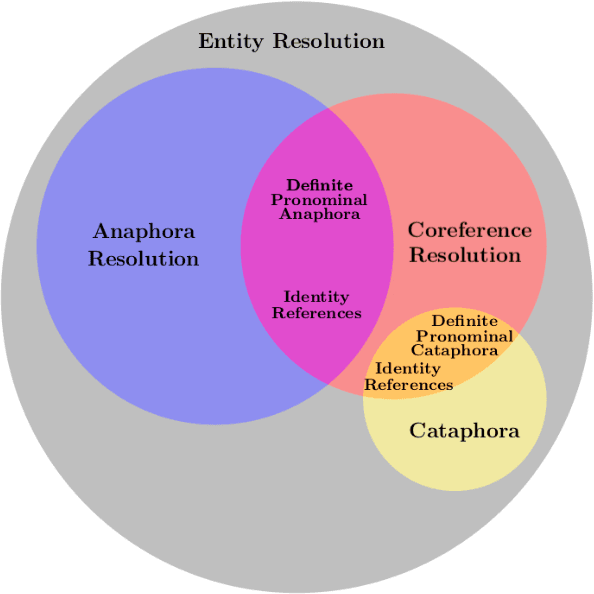

Entity resolution aims at resolving repeated references to an entity in a document and forms a core component of natural language processing (NLP) research. This field possesses immense potential to improve the performance of other NLP fields like machine translation, sentiment analysis, paraphrase detection, summarization, etc. The area of entity resolution in NLP has seen proliferation of research in two separate sub-areas namely: anaphora resolution and coreference resolution. Through this review article, we aim at clarifying the scope of these two tasks in entity resolution. We also carry out a detailed analysis of the datasets, evaluation metrics and research methods that have been adopted to tackle this NLP problem. This survey is motivated with the aim of providing the reader with a clear understanding of what constitutes this NLP problem and the issues that require attention.