 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBBOmix: A Tabular Benchmark for Hyperparameter Optimization of Unsupervised Biological Representation Learning
Jun 03, 2026The rapid advancement of high-throughput sequencing has led to large, high-dimensional omics datasets. Deep unsupervised learning architectures, particularly Autoencoders (AEs), are increasingly used for dimensionality reduction and representation learning in this domain. However, AEs are highly sensitive to architectural choices and hyperparameters, and unsupervised optimization typically relies on reconstruction loss, which may be a poor proxy for downstream utility. Exhaustive hyperparameter optimization (HPO) is computationally expensive, leading researchers to frequently rely on suboptimal default configurations. To democratize access to large-scale unsupervised HPO research, we introduce $\textbf{BBOmix}$, the first open-source tabular benchmark for unsupervised representation learning on real-world biological data. Our benchmark includes 105,000 evaluations across four AE architectures and seven multi-omics modalities from the TCGA and SCHC datasets. We quantify the correlation between reconstruction loss and downstream task performance and provide an extensive evaluation of state-of-the-art single-fidelity, multi-fidelity, and transfer learning HPO methods, establishing a rigorous baseline for future research in unsupervised biological representation learning.
An Open-Source Training Dataset for Foundation Models for Black-box Optimization
May 22, 2026Most black-box optimization methods require extensive hyperparameter tuning, often limiting their ability to generalize across different optimization domains. Foundation models for black-box optimization that learn optimization principles from a large collection of optimization trajectories offer a promising alternative, with the potential to outperform manually designed methods across diverse problem classes. However, prior work has either relied on non-public datasets or on purely synthetic data, limiting reproducibility and generalization to real-world problems. As a result, progress in this area has been constrained by the lack of large-scale, real-world, publicly available pre-training data. We introduce BBO-Pile, the first open-source dataset comprising over 500K optimization trajectories evaluated across 3095 different black-boxes for different optimizers, which represents by far the largest public dataset for this task. Using this dataset, we train a family of foundation models at multiple scales, ranging from 2M to 80M parameters and from 200M to 2B training tokens, and study their scaling behavior with respect to compute. Our results demonstrate that large-scale pre-training is a viable and effective approach to imitate black-box optimization methods, paving the way for future research in this direction.
When is Warmstarting Effective for Scaling Language Models?
May 13, 2026Model growth from a given checkpoint aims to accelerate training of a larger model, offering potential resource savings. Despite recent interest, warmstarting has seen limited practical adoption in large-scale training. We attribute this to two underexplored factors: (1) an overemphasis on preserving the smaller model's performance at initialization, which constrains operator design for new architectures, and (2) insufficient analysis of how growth interacts with hyperparameters and scaling behavior, compounded by inconsistent growth factors across the literature. We show that preserving the base model's initial post-growth performance is not necessary for strong final performance, and that simple, architecture-agnostic growth strategies can outperform more complex warmstarting operators. Crucially, we empirically identify an upper bound on the growth factor $g$ beyond which training from scratch is more efficient. We observe this across multiple ablation setups. Notably, this limit is also present, but unreported, in prior published results. Across our experiments on dense MLPs and dense language models, we find that a $2\times$ growth factor is the most reliable in yielding convergence speedups, with gains most pronounced under 20 tokens/parameter budgets and diminishing as budget increases. We fit scaling laws over these observations to provide predictive guidance for practitioners deciding when and how much to grow. Together, our analysis provides practical guidelines and empirical limits for model growth.
Where to Begin: Efficient Pretraining via Subnetwork Selection and Distillation
Oct 08, 2025Small Language models (SLMs) offer an efficient and accessible alternative to Large Language Models (LLMs), delivering strong performance while using far fewer resources. We introduce a simple and effective framework for pretraining SLMs that brings together three complementary ideas. First, we identify structurally sparse sub-network initializations that consistently outperform randomly initialized models of similar size under the same compute budget. Second, we use evolutionary search to automatically discover high-quality sub-network initializations, providing better starting points for pretraining. Third, we apply knowledge distillation from larger teacher models to speed up training and improve generalization. Together, these components make SLM pretraining substantially more efficient: our best model, discovered using evolutionary search and initialized with LLM weights, matches the validation perplexity of a comparable Pythia SLM while requiring 9.2x fewer pretraining tokens. We release all code and models at https://github.com/whittle-org/whittle/, offering a practical and reproducible path toward cost-efficient small language model development at scale.
Improving LLM-based Global Optimization with Search Space Partitioning
May 27, 2025



Large Language Models (LLMs) have recently emerged as effective surrogate models and candidate generators within global optimization frameworks for expensive blackbox functions. Despite promising results, LLM-based methods often struggle in high-dimensional search spaces or when lacking domain-specific priors, leading to sparse or uninformative suggestions. To overcome these limitations, we propose HOLLM, a novel global optimization algorithm that enhances LLM-driven sampling by partitioning the search space into promising subregions. Each subregion acts as a ``meta-arm'' selected via a bandit-inspired scoring mechanism that effectively balances exploration and exploitation. Within each selected subregion, an LLM then proposes high-quality candidate points, without any explicit domain knowledge. Empirical evaluation on standard optimization benchmarks shows that HOLLM consistently matches or surpasses leading Bayesian optimization and trust-region methods, while substantially outperforming global LLM-based sampling strategies.
Hyperband-based Bayesian Optimization for Black-box Prompt Selection
Dec 10, 2024



Optimal prompt selection is crucial for maximizing large language model (LLM) performance on downstream tasks. As the most powerful models are proprietary and can only be invoked via an API, users often manually refine prompts in a black-box setting by adjusting instructions and few-shot examples until they achieve good performance as measured on a validation set. Recent methods addressing static black-box prompt selection face significant limitations: They often fail to leverage the inherent structure of prompts, treating instructions and few-shot exemplars as a single block of text. Moreover, they often lack query-efficiency by evaluating prompts on all validation instances, or risk sub-optimal selection of a prompt by using random subsets of validation instances. We introduce HbBoPs, a novel Hyperband-based Bayesian optimization method for black-box prompt selection addressing these key limitations. Our approach combines a structural-aware deep kernel Gaussian Process to model prompt performance with Hyperband as a multi-fidelity scheduler to select the number of validation instances for prompt evaluations. The structural-aware modeling approach utilizes separate embeddings for instructions and few-shot exemplars, enhancing the surrogate model's ability to capture prompt performance and predict which prompt to evaluate next in a sample-efficient manner. Together with Hyperband as a multi-fidelity scheduler we further enable query-efficiency by adaptively allocating resources across different fidelity levels, keeping the total number of validation instances prompts are evaluated on low. Extensive evaluation across ten benchmarks and three LLMs demonstrate that HbBoPs outperforms state-of-the-art methods.
Warmstarting for Scaling Language Models
Nov 11, 2024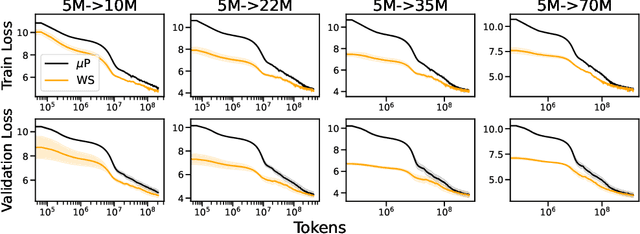
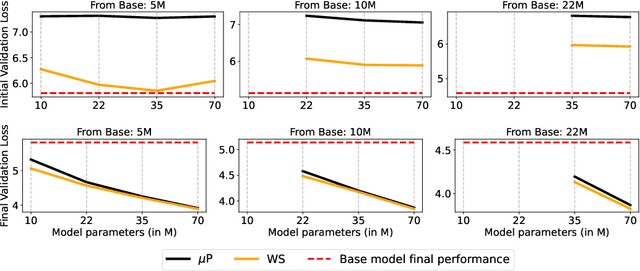
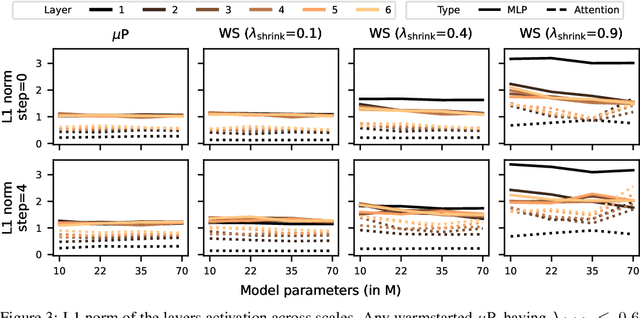
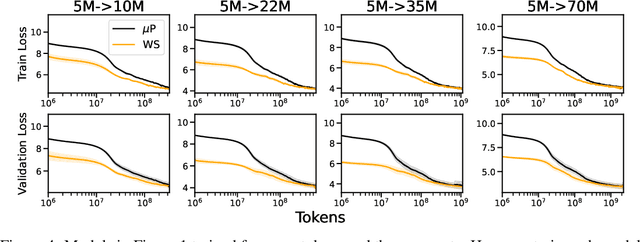
Scaling model sizes to scale performance has worked remarkably well for the current large language models paradigm. The research and empirical findings of various scaling studies led to novel scaling results and laws that guides subsequent research. High training costs for contemporary scales of data and models result in a lack of thorough understanding of how to tune and arrive at such training setups. One direction to ameliorate the cost of pretraining large models is to warmstart the large-scale training from smaller models that are cheaper to tune. In this work, we attempt to understand if the behavior of optimal hyperparameters can be retained under warmstarting for scaling. We explore simple operations that allow the application of theoretically motivated methods of zero-shot transfer of optimal hyperparameters using {\mu}Transfer. We investigate the aspects that contribute to the speedup in convergence and the preservation of stable training dynamics under warmstarting with {\mu}Transfer. We find that shrinking smaller model weights, zero-padding, and perturbing the resulting larger model with scaled initialization from {\mu}P enables effective warmstarting of $\mut{}$.
Hyperparameter Optimization in Machine Learning
Oct 30, 2024



Hyperparameters are configuration variables controlling the behavior of machine learning algorithms. They are ubiquitous in machine learning and artificial intelligence and the choice of their values determine the effectiveness of systems based on these technologies. Manual hyperparameter search is often unsatisfactory and becomes unfeasible when the number of hyperparameters is large. Automating the search is an important step towards automating machine learning, freeing researchers and practitioners alike from the burden of finding a good set of hyperparameters by trial and error. In this survey, we present a unified treatment of hyperparameter optimization, providing the reader with examples and insights into the state-of-the-art. We cover the main families of techniques to automate hyperparameter search, often referred to as hyperparameter optimization or tuning, including random and quasi-random search, bandit-, model- and gradient- based approaches. We further discuss extensions, including online, constrained, and multi-objective formulations, touch upon connections with other fields such as meta-learning and neural architecture search, and conclude with open questions and future research directions.
LLM Compression with Neural Architecture Search
Oct 09, 2024



Large language models (LLMs) exhibit remarkable reasoning abilities, allowing them to generalize across a wide range of downstream tasks, such as commonsense reasoning or instruction following. However, as LLMs scale, inference costs become increasingly prohibitive, accumulating significantly over their life cycle. This poses the question: Can we compress pre-trained LLMs to meet diverse size and latency requirements? We leverage Neural Architecture Search (NAS) to compress LLMs by pruning structural components, such as attention heads, neurons, and layers, aiming to achieve a Pareto-optimal balance between performance and efficiency. While NAS already achieved promising results on small language models in previous work, in this paper we propose various extensions that allow us to scale to LLMs. Compared to structural pruning baselines, we show that NAS improves performance up to 3.4% on MMLU with an on-device latency speedup.
Structural Pruning of Pre-trained Language Models via Neural Architecture Search
May 03, 2024



Pre-trained language models (PLM), for example BERT or RoBERTa, mark the state-of-the-art for natural language understanding task when fine-tuned on labeled data. However, their large size poses challenges in deploying them for inference in real-world applications, due to significant GPU memory requirements and high inference latency. This paper explores neural architecture search (NAS) for structural pruning to find sub-parts of the fine-tuned network that optimally trade-off efficiency, for example in terms of model size or latency, and generalization performance. We also show how we can utilize more recently developed two-stage weight-sharing NAS approaches in this setting to accelerate the search process. Unlike traditional pruning methods with fixed thresholds, we propose to adopt a multi-objective approach that identifies the Pareto optimal set of sub-networks, allowing for a more flexible and automated compression process.