 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClustering Context in Off-Policy Evaluation
Feb 28, 2025Off-policy evaluation can leverage logged data to estimate the effectiveness of new policies in e-commerce, search engines, media streaming services, or automatic diagnostic tools in healthcare. However, the performance of baseline off-policy estimators like IPS deteriorates when the logging policy significantly differs from the evaluation policy. Recent work proposes sharing information across similar actions to mitigate this problem. In this work, we propose an alternative estimator that shares information across similar contexts using clustering. We study the theoretical properties of the proposed estimator, characterizing its bias and variance under different conditions. We also compare the performance of the proposed estimator and existing approaches in various synthetic problems, as well as a real-world recommendation dataset. Our experimental results confirm that clustering contexts improves estimation accuracy, especially in deficient information settings.
Hyperband-based Bayesian Optimization for Black-box Prompt Selection
Dec 10, 2024



Optimal prompt selection is crucial for maximizing large language model (LLM) performance on downstream tasks. As the most powerful models are proprietary and can only be invoked via an API, users often manually refine prompts in a black-box setting by adjusting instructions and few-shot examples until they achieve good performance as measured on a validation set. Recent methods addressing static black-box prompt selection face significant limitations: They often fail to leverage the inherent structure of prompts, treating instructions and few-shot exemplars as a single block of text. Moreover, they often lack query-efficiency by evaluating prompts on all validation instances, or risk sub-optimal selection of a prompt by using random subsets of validation instances. We introduce HbBoPs, a novel Hyperband-based Bayesian optimization method for black-box prompt selection addressing these key limitations. Our approach combines a structural-aware deep kernel Gaussian Process to model prompt performance with Hyperband as a multi-fidelity scheduler to select the number of validation instances for prompt evaluations. The structural-aware modeling approach utilizes separate embeddings for instructions and few-shot exemplars, enhancing the surrogate model's ability to capture prompt performance and predict which prompt to evaluate next in a sample-efficient manner. Together with Hyperband as a multi-fidelity scheduler we further enable query-efficiency by adaptively allocating resources across different fidelity levels, keeping the total number of validation instances prompts are evaluated on low. Extensive evaluation across ten benchmarks and three LLMs demonstrate that HbBoPs outperforms state-of-the-art methods.
Guiding Catalogue Enrichment with User Queries
Jun 11, 2024Techniques for knowledge graph (KGs) enrichment have been increasingly crucial for commercial applications that rely on evolving product catalogues. However, because of the huge search space of potential enrichment, predictions from KG completion (KGC) methods suffer from low precision, making them unreliable for real-world catalogues. Moreover, candidate facts for enrichment have varied relevance to users. While making correct predictions for incomplete triplets in KGs has been the main focus of KGC method, the relevance of when to apply such predictions has been neglected. Motivated by the product search use case, we address the angle of generating relevant completion for a catalogue using user search behaviour and the users property association with a product. In this paper, we present our intuition for identifying enrichable data points and use general-purpose KGs to show-case the performance benefits. In particular, we extract entity-predicate pairs from user queries, which are more likely to be correct and relevant, and use these pairs to guide the prediction of KGC methods. We assess our method on two popular encyclopedia KGs, DBPedia and YAGO 4. Our results from both automatic and human evaluations show that query guidance can significantly improve the correctness and relevance of prediction.
Structural Pruning of Pre-trained Language Models via Neural Architecture Search
May 03, 2024



Pre-trained language models (PLM), for example BERT or RoBERTa, mark the state-of-the-art for natural language understanding task when fine-tuned on labeled data. However, their large size poses challenges in deploying them for inference in real-world applications, due to significant GPU memory requirements and high inference latency. This paper explores neural architecture search (NAS) for structural pruning to find sub-parts of the fine-tuned network that optimally trade-off efficiency, for example in terms of model size or latency, and generalization performance. We also show how we can utilize more recently developed two-stage weight-sharing NAS approaches in this setting to accelerate the search process. Unlike traditional pruning methods with fixed thresholds, we propose to adopt a multi-objective approach that identifies the Pareto optimal set of sub-networks, allowing for a more flexible and automated compression process.
Geographical Erasure in Language Generation
Oct 23, 2023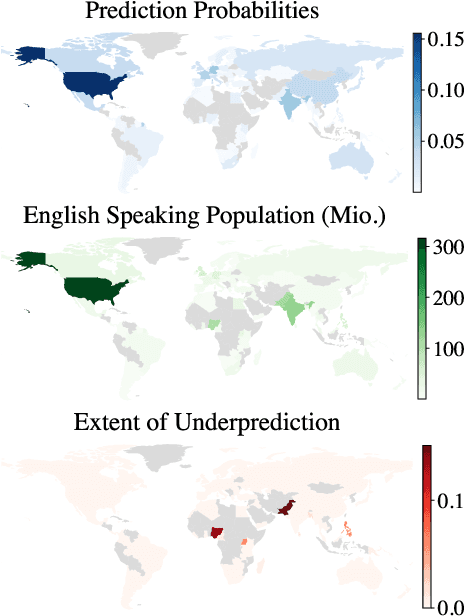

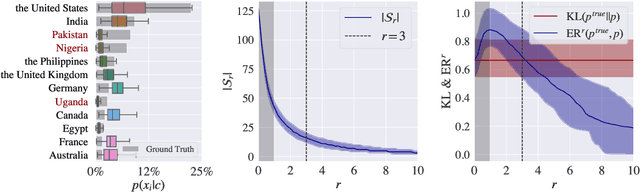
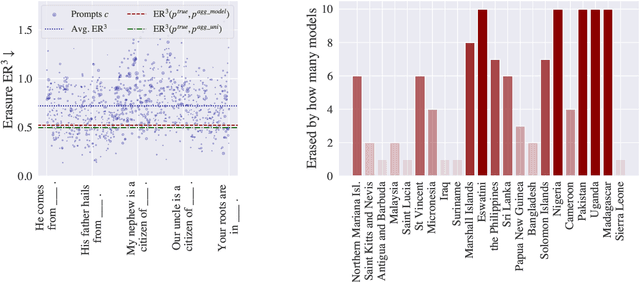
Large language models (LLMs) encode vast amounts of world knowledge. However, since these models are trained on large swaths of internet data, they are at risk of inordinately capturing information about dominant groups. This imbalance can propagate into generated language. In this work, we study and operationalise a form of geographical erasure, wherein language models underpredict certain countries. We demonstrate consistent instances of erasure across a range of LLMs. We discover that erasure strongly correlates with low frequencies of country mentions in the training corpus. Lastly, we mitigate erasure by finetuning using a custom objective.
Learning Action Embeddings for Off-Policy Evaluation
May 06, 2023Off-policy evaluation (OPE) methods allow us to compute the expected reward of a policy by using the logged data collected by a different policy. OPE is a viable alternative to running expensive online A/B tests: it can speed up the development of new policies, and reduces the risk of exposing customers to suboptimal treatments. However, when the number of actions is large, or certain actions are under-explored by the logging policy, existing estimators based on inverse-propensity scoring (IPS) can have a high or even infinite variance. Saito and Joachims (arXiv:2202.06317v2 [cs.LG]) propose marginalized IPS (MIPS) that uses action embeddings instead, which reduces the variance of IPS in large action spaces. MIPS assumes that good action embeddings can be defined by the practitioner, which is difficult to do in many real-world applications. In this work, we explore learning action embeddings from logged data. In particular, we use intermediate outputs of a trained reward model to define action embeddings for MIPS. This approach extends MIPS to more applications, and in our experiments improves upon MIPS with pre-defined embeddings, as well as standard baselines, both on synthetic and real-world data. Our method does not make assumptions about the reward model class, and supports using additional action information to further improve the estimates. The proposed approach presents an appealing alternative to DR for combining the low variance of DM with the low bias of IPS.
Optimizing Hyperparameters with Conformal Quantile Regression
May 05, 2023Many state-of-the-art hyperparameter optimization (HPO) algorithms rely on model-based optimizers that learn surrogate models of the target function to guide the search. Gaussian processes are the de facto surrogate model due to their ability to capture uncertainty but they make strong assumptions about the observation noise, which might not be warranted in practice. In this work, we propose to leverage conformalized quantile regression which makes minimal assumptions about the observation noise and, as a result, models the target function in a more realistic and robust fashion which translates to quicker HPO convergence on empirical benchmarks. To apply our method in a multi-fidelity setting, we propose a simple, yet effective, technique that aggregates observed results across different resource levels and outperforms conventional methods across many empirical tasks.
Meta-Calibration Regularized Neural Networks
Mar 27, 2023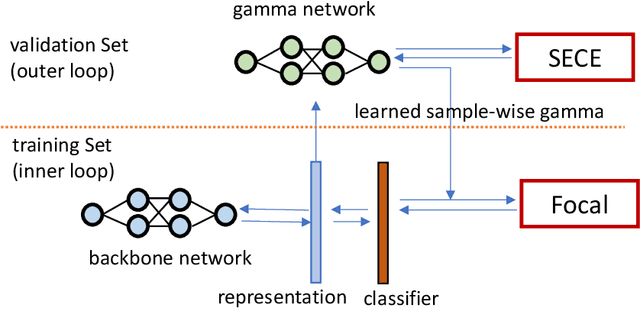
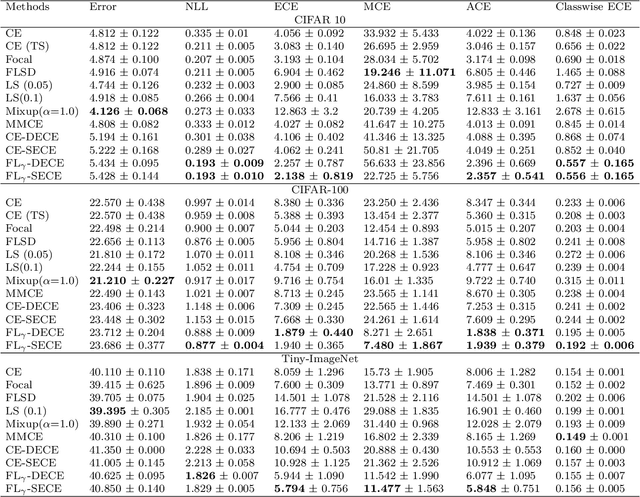
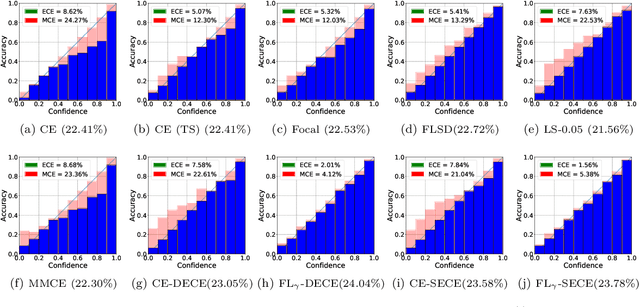

Miscalibration-the mismatch between predicted probability and the true correctness likelihood-has been frequently identified in modern deep neural networks. Recent work in the field aims to address this problem by training calibrated models directly by optimizing a proxy of the calibration error alongside the conventional objective. Recently, Meta-Calibration (MC) showed the effectiveness of using meta-learning for learning better calibrated models. In this work, we extend MC with two main components: (1) gamma network (gamma-net), a meta network to learn a sample-wise gamma at a continuous space for focal loss for optimizing backbone network; (2) smooth expected calibration error (SECE), a Gaussian-kernel based unbiased and differentiable ECE which aims to smoothly optimizing gamma-net. The proposed method regularizes neural network towards better calibration meanwhile retain predictive performance. Our experiments show that (a) learning sample-wise gamma at continuous space can effectively perform calibration; (b) SECE smoothly optimise gamma-net towards better robustness to binning schemes; (c) the combination of gamma-net and SECE achieve the best calibration performance across various calibration metrics and retain very competitive predictive performance as compared to multiple recently proposed methods on three datasets.