 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Ability of Transformers to Verify Plans
Mar 20, 2026Transformers have shown inconsistent success in AI planning tasks, and theoretical understanding of when generalization should be expected has been limited. We take important steps towards addressing this gap by analyzing the ability of decoder-only models to verify whether a given plan correctly solves a given planning instance. To analyse the general setting where the number of objects -- and thus the effective input alphabet -- grows at test time, we introduce C*-RASP, an extension of C-RASP designed to establish length generalization guarantees for transformers under the simultaneous growth in sequence length and vocabulary size. Our results identify a large class of classical planning domains for which transformers can provably learn to verify long plans, and structural properties that significantly affects the learnability of length generalizable solutions. Empirical experiments corroborate our theory.
Burn After Reading: Do Multimodal Large Language Models Truly Capture Order of Events in Image Sequences?
Jun 12, 2025This paper introduces the TempVS benchmark, which focuses on temporal grounding and reasoning capabilities of Multimodal Large Language Models (MLLMs) in image sequences. TempVS consists of three main tests (i.e., event relation inference, sentence ordering and image ordering), each accompanied with a basic grounding test. TempVS requires MLLMs to rely on both visual and linguistic modalities to understand the temporal order of events. We evaluate 38 state-of-the-art MLLMs, demonstrating that models struggle to solve TempVS, with a substantial performance gap compared to human capabilities. We also provide fine-grained insights that suggest promising directions for future research. Our TempVS benchmark data and code are available at https://github.com/yjsong22/TempVS.
On Support Samples of Next Word Prediction
Jun 09, 2025Language models excel in various tasks by making complex decisions, yet understanding the rationale behind these decisions remains a challenge. This paper investigates \emph{data-centric interpretability} in language models, focusing on the next-word prediction task. Using representer theorem, we identify two types of \emph{support samples}-those that either promote or deter specific predictions. Our findings reveal that being a support sample is an intrinsic property, predictable even before training begins. Additionally, while non-support samples are less influential in direct predictions, they play a critical role in preventing overfitting and shaping generalization and representation learning. Notably, the importance of non-support samples increases in deeper layers, suggesting their significant role in intermediate representation formation. These insights shed light on the interplay between data and model decisions, offering a new dimension to understanding language model behavior and interpretability.
Grokking ExPLAIND: Unifying Model, Data, and Training Attribution to Study Model Behavior
May 26, 2025Post-hoc interpretability methods typically attribute a model's behavior to its components, data, or training trajectory in isolation. This leads to explanations that lack a unified view and may miss key interactions. While combining existing methods or applying them at different training stages offers broader insights, these approaches usually lack theoretical support. In this work, we present ExPLAIND, a unified framework that integrates all three perspectives. First, we generalize recent work on gradient path kernels, which reformulate models trained by gradient descent as a kernel machine, to more realistic training settings. Empirically, we find that both a CNN and a Transformer model are replicated accurately by this reformulation. Second, we derive novel parameter- and step-wise influence scores from the kernel feature maps. We show their effectiveness in parameter pruning that is comparable to existing methods, reinforcing their value for model component attribution. Finally, jointly interpreting model components and data over the training process, we leverage ExPLAIND to analyze a Transformer that exhibits Grokking. Among other things, our findings support previously proposed stages of Grokking, while refining the final phase as one of alignment of input embeddings and final layers around a representation pipeline learned after the memorization phase. Overall, ExPLAIND provides a theoretically grounded, unified framework to interpret model behavior and training dynamics.
Language models can learn implicit multi-hop reasoning, but only if they have lots of training data
May 23, 2025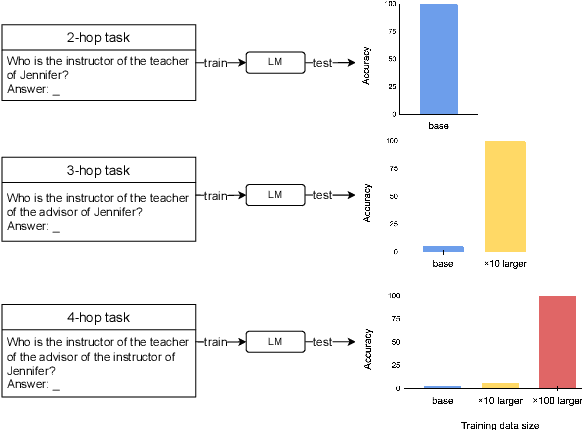
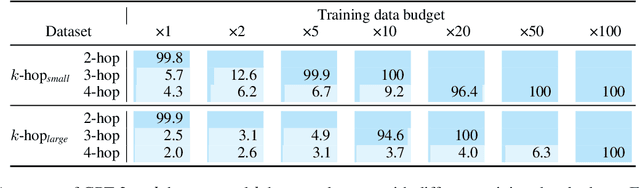
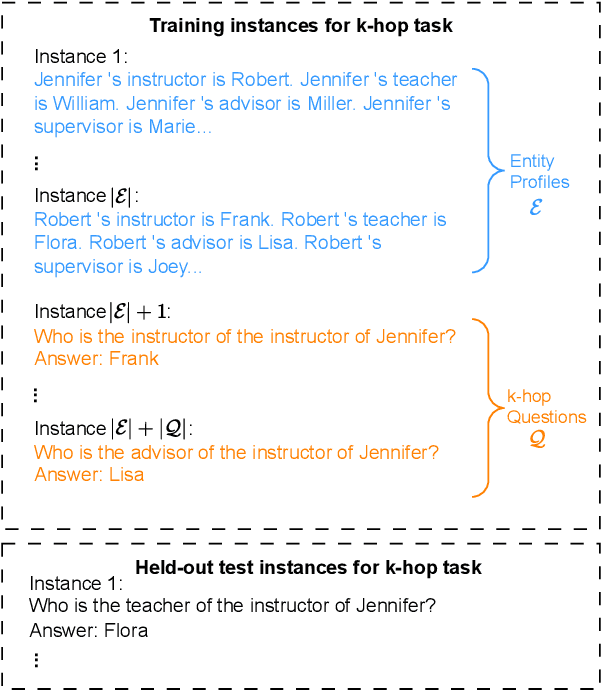
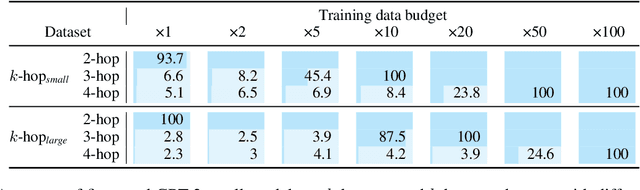
Implicit reasoning is the ability of a language model to solve multi-hop reasoning tasks in a single forward pass, without chain of thought. We investigate this capability using GPT2-style language models trained from scratch on controlled $k$-hop reasoning datasets ($k = 2, 3, 4$). We show that while such models can indeed learn implicit $k$-hop reasoning, the required training data grows exponentially in $k$, and the required number of transformer layers grows linearly in $k$. We offer a theoretical explanation for why this depth growth is necessary. We further find that the data requirement can be mitigated, but not eliminated, through curriculum learning.
Guiding Catalogue Enrichment with User Queries
Jun 11, 2024Techniques for knowledge graph (KGs) enrichment have been increasingly crucial for commercial applications that rely on evolving product catalogues. However, because of the huge search space of potential enrichment, predictions from KG completion (KGC) methods suffer from low precision, making them unreliable for real-world catalogues. Moreover, candidate facts for enrichment have varied relevance to users. While making correct predictions for incomplete triplets in KGs has been the main focus of KGC method, the relevance of when to apply such predictions has been neglected. Motivated by the product search use case, we address the angle of generating relevant completion for a catalogue using user search behaviour and the users property association with a product. In this paper, we present our intuition for identifying enrichable data points and use general-purpose KGs to show-case the performance benefits. In particular, we extract entity-predicate pairs from user queries, which are more likely to be correct and relevant, and use these pairs to guide the prediction of KGC methods. We assess our method on two popular encyclopedia KGs, DBPedia and YAGO 4. Our results from both automatic and human evaluations show that query guidance can significantly improve the correctness and relevance of prediction.
Transforming Dutch: Debiasing Dutch Coreference Resolution Systems for Non-binary Pronouns
Apr 30, 2024Gender-neutral pronouns are increasingly being introduced across Western languages. Recent evaluations have however demonstrated that English NLP systems are unable to correctly process gender-neutral pronouns, with the risk of erasing and misgendering non-binary individuals. This paper examines a Dutch coreference resolution system's performance on gender-neutral pronouns, specifically hen and die. In Dutch, these pronouns were only introduced in 2016, compared to the longstanding existence of singular they in English. We additionally compare two debiasing techniques for coreference resolution systems in non-binary contexts: Counterfactual Data Augmentation (CDA) and delexicalisation. Moreover, because pronoun performance can be hard to interpret from a general evaluation metric like LEA, we introduce an innovative evaluation metric, the pronoun score, which directly represents the portion of correctly processed pronouns. Our results reveal diminished performance on gender-neutral pronouns compared to gendered counterparts. Nevertheless, although delexicalisation fails to yield improvements, CDA substantially reduces the performance gap between gendered and gender-neutral pronouns. We further show that CDA remains effective in low-resource settings, in which a limited set of debiasing documents is used. This efficacy extends to previously unseen neopronouns, which are currently infrequently used but may gain popularity in the future, underscoring the viability of effective debiasing with minimal resources and low computational costs.
FTFT: efficient and robust Fine-Tuning by transFerring Training dynamics
Oct 10, 2023Despite the massive success of fine-tuning large Pre-trained Language Models (PLMs) on a wide range of Natural Language Processing (NLP) tasks, they remain susceptible to out-of-distribution (OOD) and adversarial inputs. Data map (DM) is a simple yet effective dual-model approach that enhances the robustness of fine-tuned PLMs, which involves fine-tuning a model on the original training set (i.e. reference model), selecting a specified fraction of important training examples according to the training dynamics of the reference model, and fine-tuning the same model on these selected examples (i.e. main model). However, it suffers from the drawback of requiring fine-tuning the same model twice, which is computationally expensive for large models. In this paper, we first show that 1) training dynamics are highly transferable across different model sizes and different pre-training methods, and that 2) main models fine-tuned using DM learn faster than when using conventional Empirical Risk Minimization (ERM). Building on these observations, we propose a novel fine-tuning approach based on the DM method: Fine-Tuning by transFerring Training dynamics (FTFT). Compared with DM, FTFT uses more efficient reference models and then fine-tunes more capable main models for fewer steps. Our experiments show that FTFT achieves better generalization robustness than ERM while spending less than half of the training cost.
CREATED: Generating Viable Counterfactual Sequences for Predictive Process Analytics
Mar 28, 2023Predictive process analytics focuses on predicting future states, such as the outcome of running process instances. These techniques often use machine learning models or deep learning models (such as LSTM) to make such predictions. However, these deep models are complex and difficult for users to understand. Counterfactuals answer ``what-if'' questions, which are used to understand the reasoning behind the predictions. For example, what if instead of emailing customers, customers are being called? Would this alternative lead to a different outcome? Current methods to generate counterfactual sequences either do not take the process behavior into account, leading to generating invalid or infeasible counterfactual process instances, or heavily rely on domain knowledge. In this work, we propose a general framework that uses evolutionary methods to generate counterfactual sequences. Our framework does not require domain knowledge. Instead, we propose to train a Markov model to compute the feasibility of generated counterfactual sequences and adapt three other measures (delta in outcome prediction, similarity, and sparsity) to ensure their overall viability. The evaluation shows that we generate viable counterfactual sequences, outperform baseline methods in viability, and yield similar results when compared to the state-of-the-art method that requires domain knowledge.
Measuring the Instability of Fine-Tuning
Feb 15, 2023Fine-tuning pre-trained language models on downstream tasks with varying random seeds has been shown to be unstable, especially on small datasets. Many previous studies have investigated this instability and proposed methods to mitigate it. However, most studies only used the standard deviation of performance scores (SD) as their measure, which is a narrow characterization of instability. In this paper, we analyze SD and six other measures quantifying instability at different levels of granularity. Moreover, we propose a systematic framework to evaluate the validity of these measures. Finally, we analyze the consistency and difference between different measures by reassessing existing instability mitigation methods. We hope our results will inform the development of better measurements of fine-tuning instability.