 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReasoning that Travels: Dissecting How Chain-of-Thought Transfers Across Models
May 27, 2026Large reasoning models (LRMs) often generate extensive chain-of-thought (CoT) traces before producing a final answer. As explicit textual artifacts, these traces can be passed to other models to solve the same task, enabling cross-model reasoning transfer. Yet successful transfer alone does not reveal how the provided CoT contributes to another model's answer. We study this question with a controlled provider--receiver framework, where a provider generates a reasoning trace and a receiver solves the same problem from increasingly longer trace prefixes. We compare force-answer, where the receiver answers directly from the prefix, with free-generation, where it may continue reasoning before answering. Across models and benchmarks, full traces often transfer successfully, but prefix trajectories reveal distinct mechanisms. In force-answer mode, AIME transfer is largely driven by explicit answer availability. MMLU-Pro instead reflects a larger role for receiver competence, while ZebraLogic depends on partial structured-answer information rather than complete-answer leakage alone. In free-generation mode, partial CoTs improve performance across benchmarks, indicating that prefixes can guide continued reasoning. Finally, answer agreement among receivers provides a gold-free signal for stopping provider reasoning early. Overall, cross-model CoT transfer is not a single phenomenon: it can reflect answer extraction, reasoning scaffolding, or receiver-dependent competence.
LogicSkills: A Structured Benchmark for Formal Reasoning in Large Language Models
Feb 06, 2026Large language models have demonstrated notable performance across various logical reasoning benchmarks. However, it remains unclear which core logical skills they truly master. To address this, we introduce LogicSkills, a unified benchmark designed to isolate three fundamental skills in formal reasoning: (i) $\textit{formal symbolization}\unicode{x2014}$translating premises into first-order logic; (ii) $\textit{countermodel construction}\unicode{x2014}$formulating a finite structure in which all premises are true while the conclusion is false; and (iii) $\textit{validity assessment}\unicode{x2014}$deciding whether a conclusion follows from a given set of premises. Items are drawn from the two-variable fragment of first-order logic (without identity) and are presented in both natural English and a Carroll-style language with nonce words. All examples are verified for correctness and non-triviality using the SMT solver Z3. Across leading models, performance is high on validity but substantially lower on symbolization and countermodel construction, suggesting reliance on surface-level patterns rather than genuine symbolic or rule-based reasoning.
Unravelling the Mechanisms of Manipulating Numbers in Language Models
Oct 30, 2025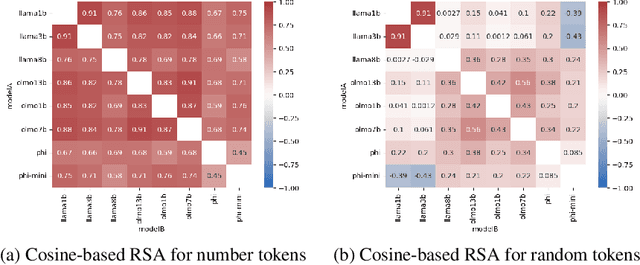

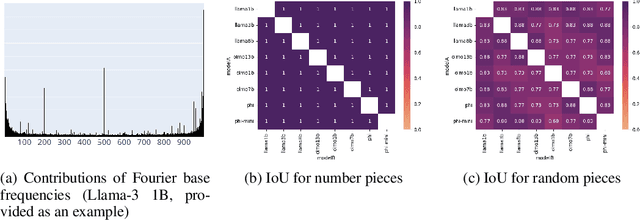
Recent work has shown that different large language models (LLMs) converge to similar and accurate input embedding representations for numbers. These findings conflict with the documented propensity of LLMs to produce erroneous outputs when dealing with numeric information. In this work, we aim to explain this conflict by exploring how language models manipulate numbers and quantify the lower bounds of accuracy of these mechanisms. We find that despite surfacing errors, different language models learn interchangeable representations of numbers that are systematic, highly accurate and universal across their hidden states and the types of input contexts. This allows us to create universal probes for each LLM and to trace information -- including the causes of output errors -- to specific layers. Our results lay a fundamental understanding of how pre-trained LLMs manipulate numbers and outline the potential of more accurate probing techniques in addressed refinements of LLMs' architectures.
Grokking ExPLAIND: Unifying Model, Data, and Training Attribution to Study Model Behavior
May 26, 2025Post-hoc interpretability methods typically attribute a model's behavior to its components, data, or training trajectory in isolation. This leads to explanations that lack a unified view and may miss key interactions. While combining existing methods or applying them at different training stages offers broader insights, these approaches usually lack theoretical support. In this work, we present ExPLAIND, a unified framework that integrates all three perspectives. First, we generalize recent work on gradient path kernels, which reformulate models trained by gradient descent as a kernel machine, to more realistic training settings. Empirically, we find that both a CNN and a Transformer model are replicated accurately by this reformulation. Second, we derive novel parameter- and step-wise influence scores from the kernel feature maps. We show their effectiveness in parameter pruning that is comparable to existing methods, reinforcing their value for model component attribution. Finally, jointly interpreting model components and data over the training process, we leverage ExPLAIND to analyze a Transformer that exhibits Grokking. Among other things, our findings support previously proposed stages of Grokking, while refining the final phase as one of alignment of input embeddings and final layers around a representation pipeline learned after the memorization phase. Overall, ExPLAIND provides a theoretically grounded, unified framework to interpret model behavior and training dynamics.
Enabling Systematic Generalization in Abstract Spatial Reasoning through Meta-Learning for Compositionality
Apr 02, 2025Systematic generalization refers to the capacity to understand and generate novel combinations from known components. Despite recent progress by large language models (LLMs) across various domains, these models often fail to extend their knowledge to novel compositional scenarios, revealing notable limitations in systematic generalization. There has been an ongoing debate about whether neural networks possess the capacity for systematic generalization, with recent studies suggesting that meta-learning approaches designed for compositionality can significantly enhance this ability. However, these insights have largely been confined to linguistic problems, leaving their applicability to other tasks an open question. In this study, we extend the approach of meta-learning for compositionality to the domain of abstract spatial reasoning. To this end, we introduce $\textit{SYGAR}$-a dataset designed to evaluate the capacity of models to systematically generalize from known geometric transformations (e.g., translation, rotation) of two-dimensional objects to novel combinations of these transformations (e.g., translation+rotation). Our results show that a transformer-based encoder-decoder model, trained via meta-learning for compositionality, can systematically generalize to previously unseen transformation compositions, significantly outperforming state-of-the-art LLMs, including o3-mini, GPT-4o, and Gemini 2.0 Flash, which fail to exhibit similar systematic behavior. Our findings highlight the effectiveness of meta-learning in promoting systematicity beyond linguistic tasks, suggesting a promising direction toward more robust and generalizable models.
The Validation Gap: A Mechanistic Analysis of How Language Models Compute Arithmetic but Fail to Validate It
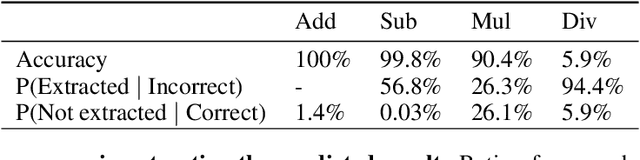
Feb 17, 2025The ability of large language models (LLMs) to validate their output and identify potential errors is crucial for ensuring robustness and reliability. However, current research indicates that LLMs struggle with self-correction, encountering significant challenges in detecting errors. While studies have explored methods to enhance self-correction in LLMs, relatively little attention has been given to understanding the models' internal mechanisms underlying error detection. In this paper, we present a mechanistic analysis of error detection in LLMs, focusing on simple arithmetic problems. Through circuit analysis, we identify the computational subgraphs responsible for detecting arithmetic errors across four smaller-sized LLMs. Our findings reveal that all models heavily rely on $\textit{consistency heads}$--attention heads that assess surface-level alignment of numerical values in arithmetic solutions. Moreover, we observe that the models' internal arithmetic computation primarily occurs in higher layers, whereas validation takes place in middle layers, before the final arithmetic results are fully encoded. This structural dissociation between arithmetic computation and validation seems to explain why current LLMs struggle to detect even simple arithmetic errors.
Understanding When Tree of Thoughts Succeeds: Larger Models Excel in Generation, Not Discrimination
Oct 24, 2024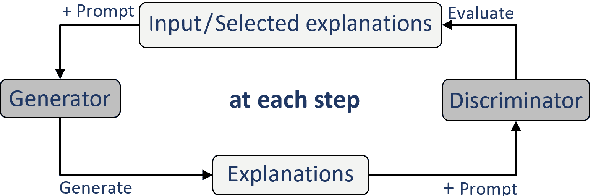
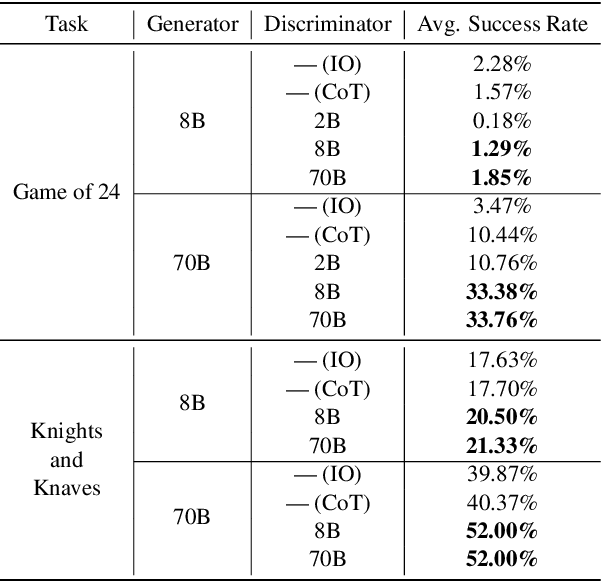

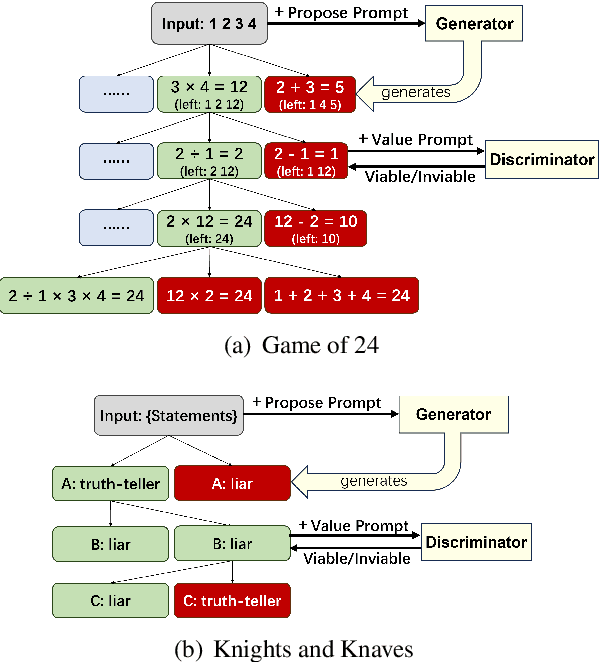
Tree of Thoughts (ToT) is a reasoning strategy for Large Language Models (LLMs) that employs a generator to suggest reasoning steps and a discriminator to decide which steps to implement. ToT demonstrates strong performance on reasoning tasks, often surpassing simple methods such as Input-Output (IO) prompting and Chain-of-Thought (CoT) reasoning. However, ToT does not consistently outperform such simpler methods across all models, leaving large knowledge gaps on the conditions under which ToT is most beneficial. In this paper, we analyze the roles of the generator and discriminator separately to better understand the conditions when ToT is beneficial. We find that the generator plays a more critical role than the discriminator in driving the success of ToT. Scaling the generator leads to notable improvements in ToT performance, even when using a smaller model as the discriminator, whereas scaling the discriminator with a fixed generator yields only marginal gains. Our results show that models across different scales exhibit comparable discrimination capabilities, yet differ significantly in their generative performance for ToT.
Circuit Compositions: Exploring Modular Structures in Transformer-Based Language Models
Oct 02, 2024



A fundamental question in interpretability research is to what extent neural networks, particularly language models, implement reusable functions via subnetworks that can be composed to perform more complex tasks. Recent developments in mechanistic interpretability have made progress in identifying subnetworks, often referred to as circuits, which represent the minimal computational subgraph responsible for a model's behavior on specific tasks. However, most studies focus on identifying circuits for individual tasks without investigating how functionally similar circuits relate to each other. To address this gap, we examine the modularity of neural networks by analyzing circuits for highly compositional subtasks within a transformer-based language model. Specifically, given a probabilistic context-free grammar, we identify and compare circuits responsible for ten modular string-edit operations. Our results indicate that functionally similar circuits exhibit both notable node overlap and cross-task faithfulness. Moreover, we demonstrate that the circuits identified can be reused and combined through subnetwork set operations to represent more complex functional capabilities of the model.
LLMs instead of Human Judges? A Large Scale Empirical Study across 20 NLP Evaluation Tasks
Jun 26, 2024
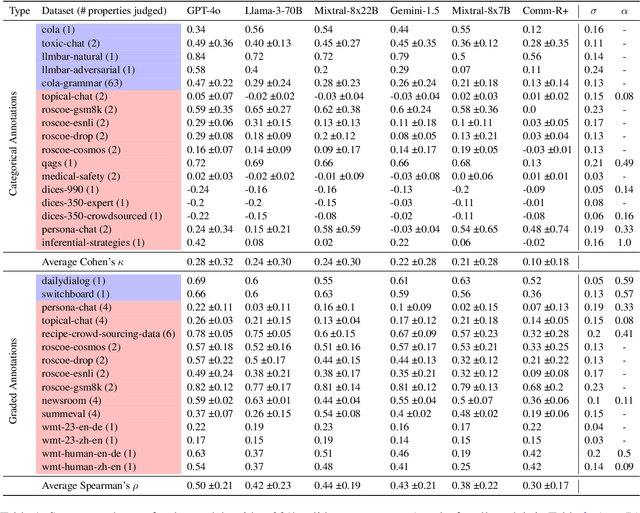
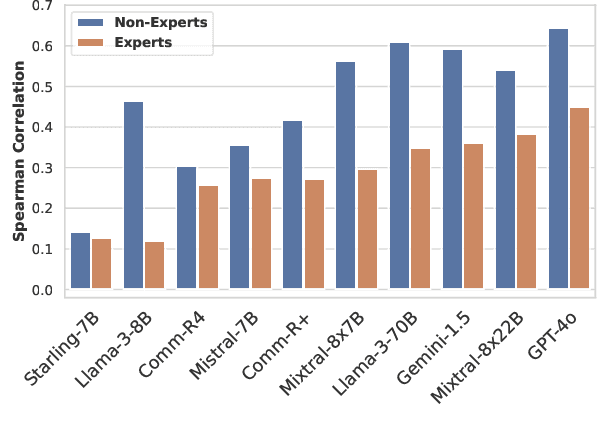
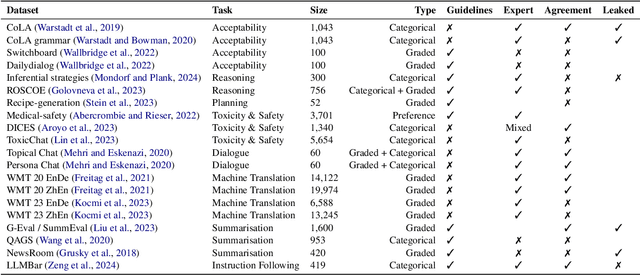
There is an increasing trend towards evaluating NLP models with LLM-generated judgments instead of human judgments. In the absence of a comparison against human data, this raises concerns about the validity of these evaluations; in case they are conducted with proprietary models, this also raises concerns over reproducibility. We provide JUDGE-BENCH, a collection of 20 NLP datasets with human annotations, and comprehensively evaluate 11 current LLMs, covering both open-weight and proprietary models, for their ability to replicate the annotations. Our evaluations show that each LLM exhibits a large variance across datasets in its correlation to human judgments. We conclude that LLMs are not yet ready to systematically replace human judges in NLP.
Liar, Liar, Logical Mire: A Benchmark for Suppositional Reasoning in Large Language Models
Jun 18, 2024Knights and knaves problems represent a classic genre of logical puzzles where characters either tell the truth or lie. The objective is to logically deduce each character's identity based on their statements. The challenge arises from the truth-telling or lying behavior, which influences the logical implications of each statement. Solving these puzzles requires not only direct deductions from individual statements, but the ability to assess the truthfulness of statements by reasoning through various hypothetical scenarios. As such, knights and knaves puzzles serve as compelling examples of suppositional reasoning. In this paper, we introduce $\textit{TruthQuest}$, a benchmark for suppositional reasoning based on the principles of knights and knaves puzzles. Our benchmark presents problems of varying complexity, considering both the number of characters and the types of logical statements involved. Evaluations on $\textit{TruthQuest}$ show that large language models like Llama 3 and Mixtral-8x7B exhibit significant difficulties solving these tasks. A detailed error analysis of the models' output reveals that lower-performing models exhibit a diverse range of reasoning errors, frequently failing to grasp the concept of truth and lies. In comparison, more proficient models primarily struggle with accurately inferring the logical implications of potentially false statements.