 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSystematic Generalization in Language Models Scales with Information Entropy
May 19, 2025Systematic generalization remains challenging for current language models, which are known to be both sensitive to semantically similar permutations of the input and to struggle with known concepts presented in novel contexts. Although benchmarks exist for assessing compositional behavior, it is unclear how to measure the difficulty of a systematic generalization problem. In this work, we show how one aspect of systematic generalization can be described by the entropy of the distribution of component parts in the training data. We formalize a framework for measuring entropy in a sequence-to-sequence task and find that the performance of popular model architectures scales with the entropy. Our work connects systematic generalization to information efficiency, and our results indicate that success at high entropy can be achieved even without built-in priors, and that success at low entropy can serve as a target for assessing progress towards robust systematic generalization.
Circuit Compositions: Exploring Modular Structures in Transformer-Based Language Models
Oct 02, 2024A fundamental question in interpretability research is to what extent neural networks, particularly language models, implement reusable functions via subnetworks that can be composed to perform more complex tasks. Recent developments in mechanistic interpretability have made progress in identifying subnetworks, often referred to as circuits, which represent the minimal computational subgraph responsible for a model's behavior on specific tasks. However, most studies focus on identifying circuits for individual tasks without investigating how functionally similar circuits relate to each other. To address this gap, we examine the modularity of neural networks by analyzing circuits for highly compositional subtasks within a transformer-based language model. Specifically, given a probabilistic context-free grammar, we identify and compare circuits responsible for ten modular string-edit operations. Our results indicate that functionally similar circuits exhibit both notable node overlap and cross-task faithfulness. Moreover, we demonstrate that the circuits identified can be reused and combined through subnetwork set operations to represent more complex functional capabilities of the model.
Compositional Generalization with Grounded Language Models
Jun 07, 2024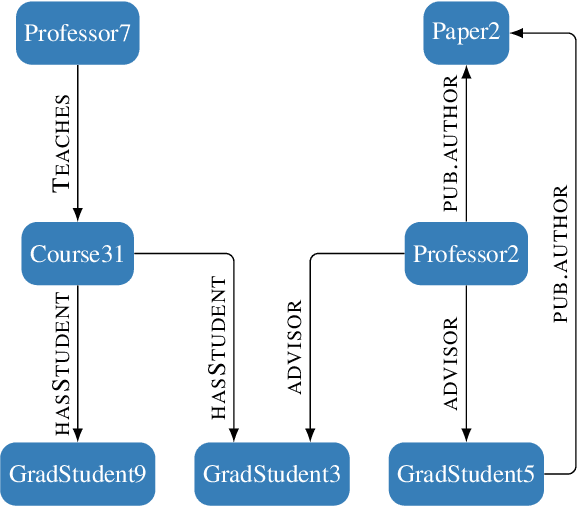

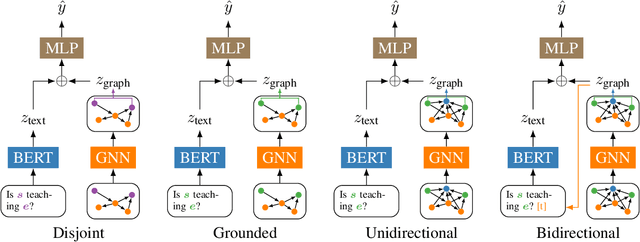
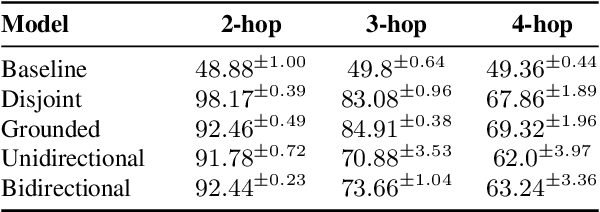
Grounded language models use external sources of information, such as knowledge graphs, to meet some of the general challenges associated with pre-training. By extending previous work on compositional generalization in semantic parsing, we allow for a controlled evaluation of the degree to which these models learn and generalize from patterns in knowledge graphs. We develop a procedure for generating natural language questions paired with knowledge graphs that targets different aspects of compositionality and further avoids grounding the language models in information already encoded implicitly in their weights. We evaluate existing methods for combining language models with knowledge graphs and find them to struggle with generalization to sequences of unseen lengths and to novel combinations of seen base components. While our experimental results provide some insight into the expressive power of these models, we hope our work and released datasets motivate future research on how to better combine language models with structured knowledge representations.
More Room for Language: Investigating the Effect of Retrieval on Language Models
Apr 16, 2024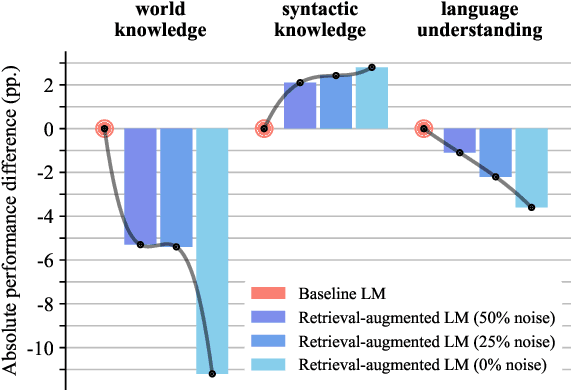
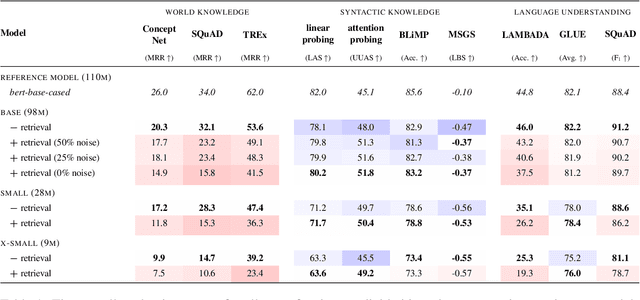
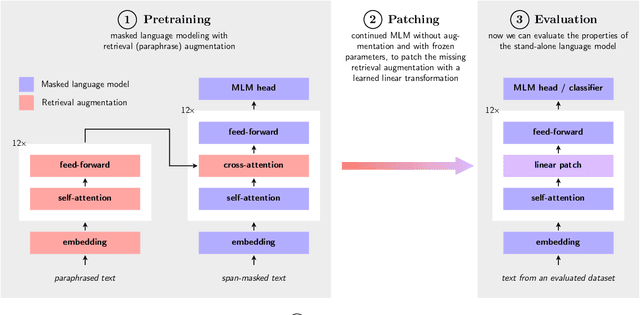
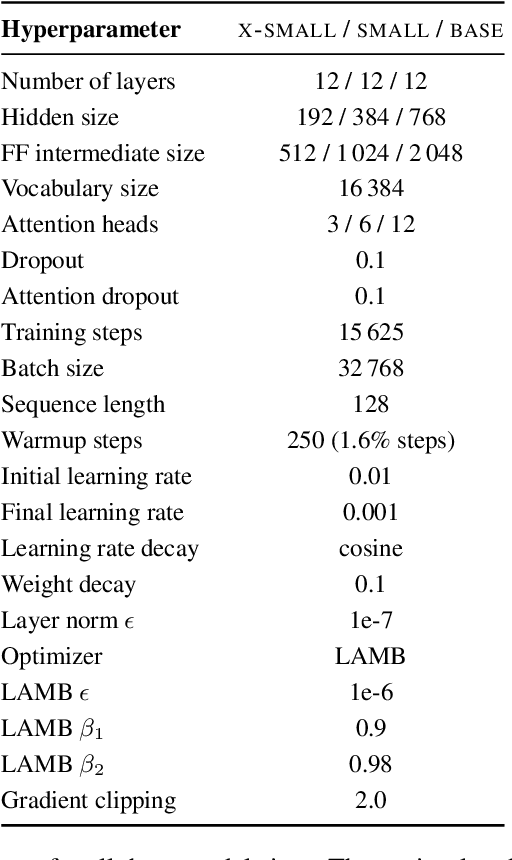
Retrieval-augmented language models pose a promising alternative to standard language modeling. During pretraining, these models search in a corpus of documents for contextually relevant information that could aid the language modeling objective. We introduce an 'ideal retrieval' methodology to study these models in a fully controllable setting. We conduct an extensive evaluation to examine how retrieval augmentation affects the behavior of the underlying language model. Among other things, we observe that these models: i) save substantially less world knowledge in their weights, ii) are better at understanding local context and inter-word dependencies, but iii) are worse at comprehending global context.
Estimating Lexical Complexity from Document-Level Distributions
Apr 01, 2024Existing methods for complexity estimation are typically developed for entire documents. This limitation in scope makes them inapplicable for shorter pieces of text, such as health assessment tools. These typically consist of lists of independent sentences, all of which are too short for existing methods to apply. The choice of wording in these assessment tools is crucial, as both the cognitive capacity and the linguistic competency of the intended patient groups could vary substantially. As a first step towards creating better tools for supporting health practitioners, we develop a two-step approach for estimating lexical complexity that does not rely on any pre-annotated data. We implement our approach for the Norwegian language and verify its effectiveness using statistical testing and a qualitative evaluation of samples from real assessment tools. We also investigate the relationship between our complexity measure and certain features typically associated with complexity in the literature, such as word length, frequency, and the number of syllables.
Text-To-KG Alignment: Comparing Current Methods on Classification Tasks
Jun 05, 2023

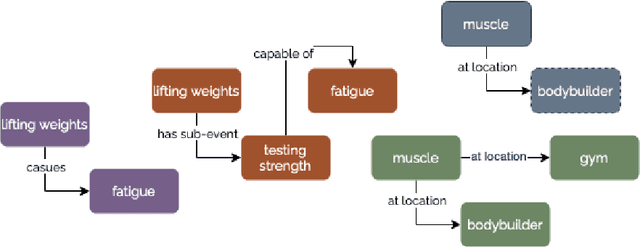

In contrast to large text corpora, knowledge graphs (KG) provide dense and structured representations of factual information. This makes them attractive for systems that supplement or ground the knowledge found in pre-trained language models with an external knowledge source. This has especially been the case for classification tasks, where recent work has focused on creating pipeline models that retrieve information from KGs like ConceptNet as additional context. Many of these models consist of multiple components, and although they differ in the number and nature of these parts, they all have in common that for some given text query, they attempt to identify and retrieve a relevant subgraph from the KG. Due to the noise and idiosyncrasies often found in KGs, it is not known how current methods compare to a scenario where the aligned subgraph is completely relevant to the query. In this work, we try to bridge this knowledge gap by reviewing current approaches to text-to-KG alignment and evaluating them on two datasets where manually created graphs are available, providing insights into the effectiveness of current methods.
NorQuAD: Norwegian Question Answering Dataset
May 03, 2023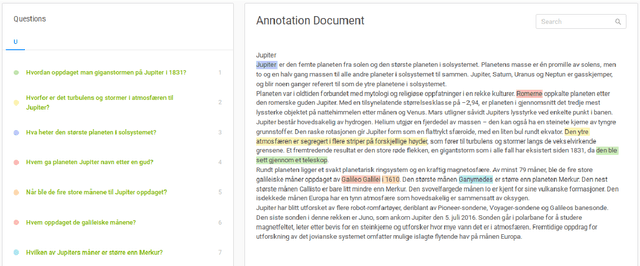



In this paper we present NorQuAD: the first Norwegian question answering dataset for machine reading comprehension. The dataset consists of 4,752 manually created question-answer pairs. We here detail the data collection procedure and present statistics of the dataset. We also benchmark several multilingual and Norwegian monolingual language models on the dataset and compare them against human performance. The dataset will be made freely available.
BRENT: Bidirectional Retrieval Enhanced Norwegian Transformer
Apr 19, 2023Retrieval-based language models are increasingly employed in question-answering tasks. These models search in a corpus of documents for relevant information instead of having all factual knowledge stored in its parameters, thereby enhancing efficiency, transparency, and adaptability. We develop the first Norwegian retrieval-based model by adapting the REALM framework and evaluating it on various tasks. After training, we also separate the language model, which we call the reader, from the retriever components, and show that this can be fine-tuned on a range of downstream tasks. Results show that retrieval augmented language modeling improves the reader's performance on extractive question-answering, suggesting that this type of training improves language models' general ability to use context and that this does not happen at the expense of other abilities such as part-of-speech tagging, dependency parsing, named entity recognition, and lemmatization. Code, trained models, and data are made publicly available.
The Effectiveness of Masked Language Modeling and Adapters for Factual Knowledge Injection
Oct 03, 2022This paper studies the problem of injecting factual knowledge into large pre-trained language models. We train adapter modules on parts of the ConceptNet knowledge graph using the masked language modeling objective and evaluate the success of the method by a series of probing experiments on the LAMA probe. Mean P@K curves for different configurations indicate that the technique is effective, increasing the performance on subsets of the LAMA probe for large values of k by adding as little as 2.1% additional parameters to the original models.