Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNorQuAD: Norwegian Question Answering Dataset
May 03, 2023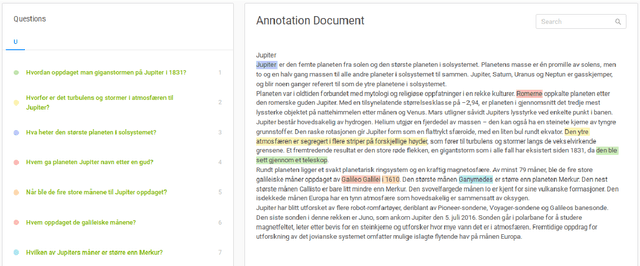



In this paper we present NorQuAD: the first Norwegian question answering dataset for machine reading comprehension. The dataset consists of 4,752 manually created question-answer pairs. We here detail the data collection procedure and present statistics of the dataset. We also benchmark several multilingual and Norwegian monolingual language models on the dataset and compare them against human performance. The dataset will be made freely available.
* Accepted to NoDaLiDa 2023
Via