 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNoCoLA: The Norwegian Corpus of Linguistic Acceptability
Jun 13, 2023While there has been a surge of large language models for Norwegian in recent years, we lack any tool to evaluate their understanding of grammaticality. We present two new Norwegian datasets for this task. NoCoLA_class is a supervised binary classification task where the goal is to discriminate between acceptable and non-acceptable sentences. On the other hand, NoCoLA_zero is a purely diagnostic task for evaluating the grammatical judgement of a language model in a completely zero-shot manner, i.e. without any further training. In this paper, we describe both datasets in detail, show how to use them for different flavors of language models, and conduct a comparative study of the existing Norwegian language models.
NorQuAD: Norwegian Question Answering Dataset
May 03, 2023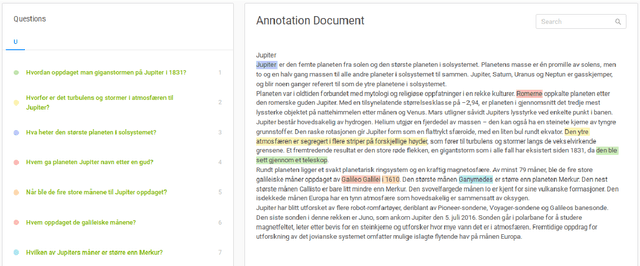



In this paper we present NorQuAD: the first Norwegian question answering dataset for machine reading comprehension. The dataset consists of 4,752 manually created question-answer pairs. We here detail the data collection procedure and present statistics of the dataset. We also benchmark several multilingual and Norwegian monolingual language models on the dataset and compare them against human performance. The dataset will be made freely available.