 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDual Language Models: Balancing Training Efficiency and Overfitting Resilience
Dec 16, 2025This paper combines autoregressive and masked-diffusion training objectives without any architectural modifications, resulting in flexible language models that outperform single-objective models. Autoregressive modeling has been a popular approach, partly because of its training efficiency; however, that comes at the cost of sensitivity to overfitting. On the other hand, masked-diffusion models are less efficient to train while being more resilient to overfitting. In this work, we demonstrate that dual-objective training achieves the best of both worlds. To derive the optimal ratio between both objectives, we train and evaluate 50 language models under varying levels of data repetition. We show that it is optimal to combine both objectives under all evaluated settings and that the optimal ratio is similar whether targeting autoregressive or masked-diffusion downstream performance.
Re-identification of De-identified Documents with Autoregressive Infilling
May 19, 2025Documents revealing sensitive information about individuals must typically be de-identified. This de-identification is often done by masking all mentions of personally identifiable information (PII), thereby making it more difficult to uncover the identity of the person(s) in question. To investigate the robustness of de-identification methods, we present a novel, RAG-inspired approach that attempts the reverse process of re-identification based on a database of documents representing background knowledge. Given a text in which personal identifiers have been masked, the re-identification proceeds in two steps. A retriever first selects from the background knowledge passages deemed relevant for the re-identification. Those passages are then provided to an infilling model which seeks to infer the original content of each text span. This process is repeated until all masked spans are replaced. We evaluate the re-identification on three datasets (Wikipedia biographies, court rulings and clinical notes). Results show that (1) as many as 80% of de-identified text spans can be successfully recovered and (2) the re-identification accuracy increases along with the level of background knowledge.
Systematic Generalization in Language Models Scales with Information Entropy
May 19, 2025Systematic generalization remains challenging for current language models, which are known to be both sensitive to semantically similar permutations of the input and to struggle with known concepts presented in novel contexts. Although benchmarks exist for assessing compositional behavior, it is unclear how to measure the difficulty of a systematic generalization problem. In this work, we show how one aspect of systematic generalization can be described by the entropy of the distribution of component parts in the training data. We formalize a framework for measuring entropy in a sequence-to-sequence task and find that the performance of popular model architectures scales with the entropy. Our work connects systematic generalization to information efficiency, and our results indicate that success at high entropy can be achieved even without built-in priors, and that success at low entropy can serve as a target for assessing progress towards robust systematic generalization.
Small Languages, Big Models: A Study of Continual Training on Languages of Norway
Dec 09, 2024



Training large language models requires vast amounts of data, posing a challenge for less widely spoken languages like Norwegian and even more so for truly low-resource languages like S\'ami. To address this issue, we present a novel three-stage continual training approach. We also experiment with combining causal and masked language modeling to get more flexible models. Based on our findings, we train, evaluate, and openly release a new large generative language model for Norwegian Bokm\r{a}l, Nynorsk, and Northern S\'ami with 11.4 billion parameters: NorMistral-11B.
GPT or BERT: why not both?
Oct 31, 2024



We present a simple way to merge masked language modeling with causal language modeling. This hybrid training objective results in a model that combines the strengths of both modeling paradigms within a single transformer stack: GPT-BERT can be transparently used like any standard causal or masked language model. We test the pretraining process that enables this flexible behavior on the BabyLM Challenge 2024. The results show that the hybrid pretraining outperforms masked-only or causal-only models. We openly release the models, training corpora and code.
Compositional Generalization with Grounded Language Models
Jun 07, 2024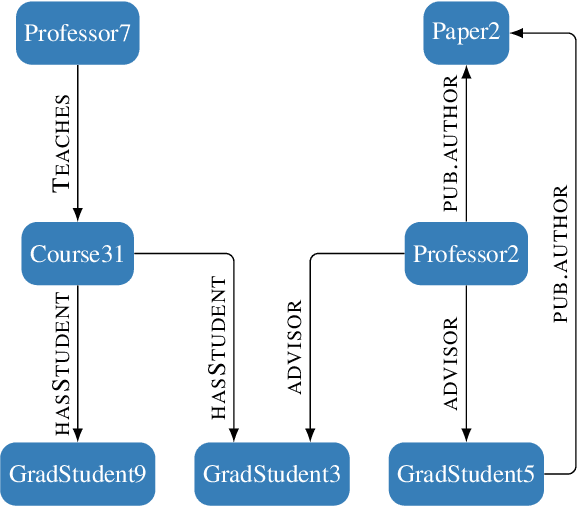

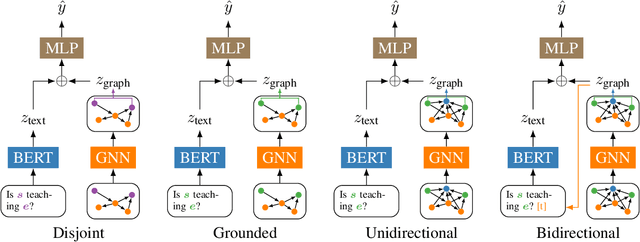
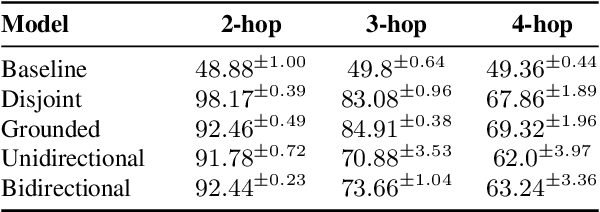
Grounded language models use external sources of information, such as knowledge graphs, to meet some of the general challenges associated with pre-training. By extending previous work on compositional generalization in semantic parsing, we allow for a controlled evaluation of the degree to which these models learn and generalize from patterns in knowledge graphs. We develop a procedure for generating natural language questions paired with knowledge graphs that targets different aspects of compositionality and further avoids grounding the language models in information already encoded implicitly in their weights. We evaluate existing methods for combining language models with knowledge graphs and find them to struggle with generalization to sequences of unseen lengths and to novel combinations of seen base components. While our experimental results provide some insight into the expressive power of these models, we hope our work and released datasets motivate future research on how to better combine language models with structured knowledge representations.
More Room for Language: Investigating the Effect of Retrieval on Language Models
Apr 16, 2024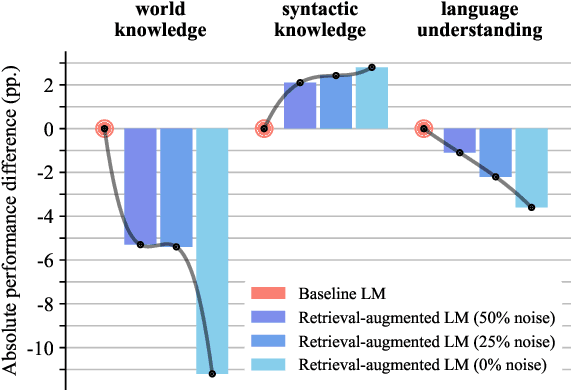
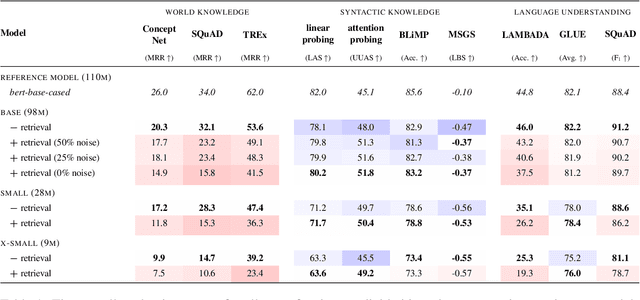
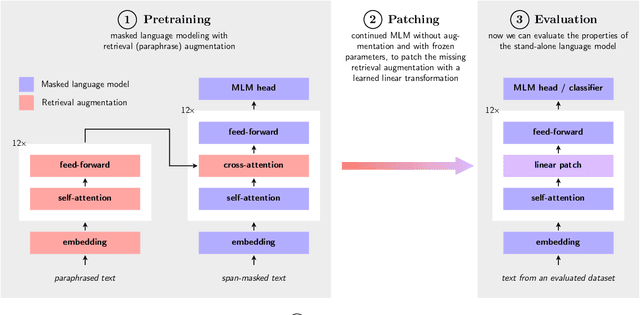
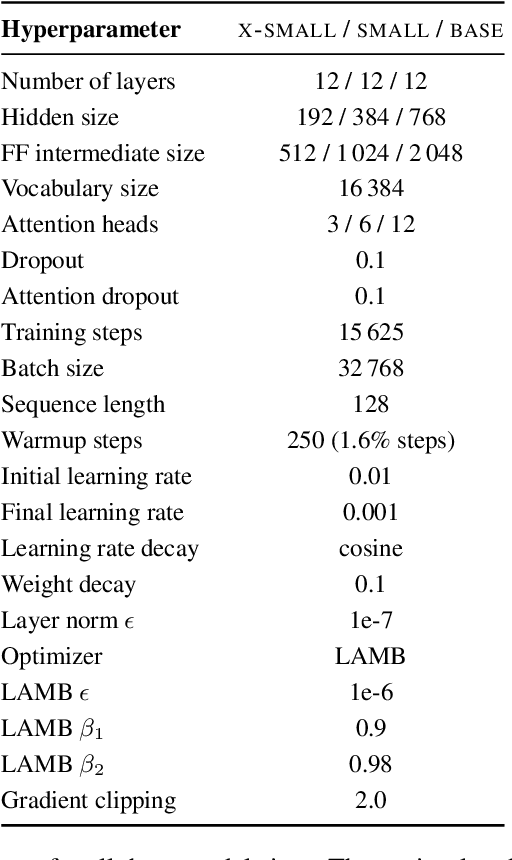
Retrieval-augmented language models pose a promising alternative to standard language modeling. During pretraining, these models search in a corpus of documents for contextually relevant information that could aid the language modeling objective. We introduce an 'ideal retrieval' methodology to study these models in a fully controllable setting. We conduct an extensive evaluation to examine how retrieval augmentation affects the behavior of the underlying language model. Among other things, we observe that these models: i) save substantially less world knowledge in their weights, ii) are better at understanding local context and inter-word dependencies, but iii) are worse at comprehending global context.
Not all layers are equally as important: Every Layer Counts BERT
Nov 07, 2023



This paper introduces a novel modification of the transformer architecture, tailored for the data-efficient pretraining of language models. This aspect is evaluated by participating in the BabyLM challenge, where our solution won both the strict and strict-small tracks. Our approach allows each transformer layer to select which outputs of previous layers to process. The empirical results verify the potential of this simple modification and show that not all layers are equally as important.
BRENT: Bidirectional Retrieval Enhanced Norwegian Transformer
Apr 19, 2023Retrieval-based language models are increasingly employed in question-answering tasks. These models search in a corpus of documents for relevant information instead of having all factual knowledge stored in its parameters, thereby enhancing efficiency, transparency, and adaptability. We develop the first Norwegian retrieval-based model by adapting the REALM framework and evaluating it on various tasks. After training, we also separate the language model, which we call the reader, from the retriever components, and show that this can be fine-tuned on a range of downstream tasks. Results show that retrieval augmented language modeling improves the reader's performance on extractive question-answering, suggesting that this type of training improves language models' general ability to use context and that this does not happen at the expense of other abilities such as part-of-speech tagging, dependency parsing, named entity recognition, and lemmatization. Code, trained models, and data are made publicly available.