Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMore Room for Language: Investigating the Effect of Retrieval on Language Models
Paper and Code
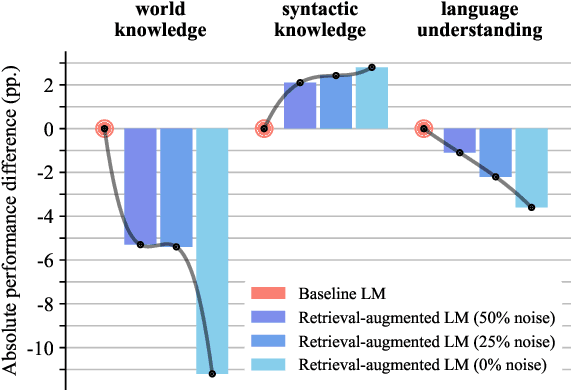
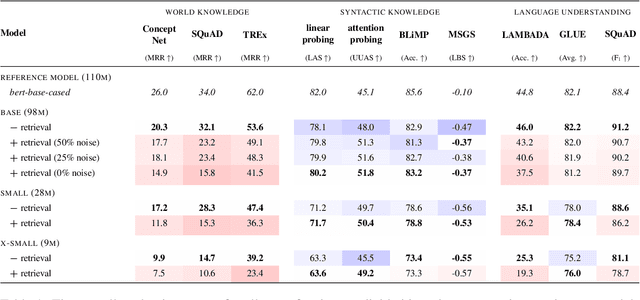
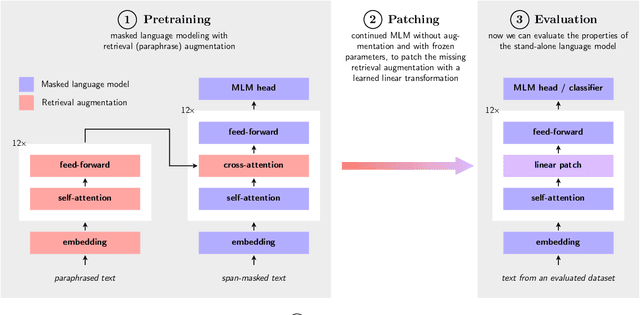
Retrieval-augmented language models pose a promising alternative to standard language modeling. During pretraining, these models search in a corpus of documents for contextually relevant information that could aid the language modeling objective. We introduce an 'ideal retrieval' methodology to study these models in a fully controllable setting. We conduct an extensive evaluation to examine how retrieval augmentation affects the behavior of the underlying language model. Among other things, we observe that these models: i) save substantially less world knowledge in their weights, ii) are better at understanding local context and inter-word dependencies, but iii) are worse at comprehending global context.
* NAACL 2024
View paper on