 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Expanded Massive Multilingual Dataset for High-Performance Language Technologies
Mar 13, 2025Training state-of-the-art large language models requires vast amounts of clean and diverse textual data. However, building suitable multilingual datasets remains a challenge. In this work, we present HPLT v2, a collection of high-quality multilingual monolingual and parallel corpora. The monolingual portion of the data contains 8T tokens covering 193 languages, while the parallel data contains 380M sentence pairs covering 51 languages. We document the entire data pipeline and release the code to reproduce it. We provide extensive analysis of the quality and characteristics of our data. Finally, we evaluate the performance of language models and machine translation systems trained on HPLT v2, demonstrating its value.
Multi-label Scandinavian Language Identification (SLIDE)
Feb 10, 2025



Identifying closely related languages at sentence level is difficult, in particular because it is often impossible to assign a sentence to a single language. In this paper, we focus on multi-label sentence-level Scandinavian language identification (LID) for Danish, Norwegian Bokm\r{a}l, Norwegian Nynorsk, and Swedish. We present the Scandinavian Language Identification and Evaluation, SLIDE, a manually curated multi-label evaluation dataset and a suite of LID models with varying speed-accuracy tradeoffs. We demonstrate that the ability to identify multiple languages simultaneously is necessary for any accurate LID method, and present a novel approach to training such multi-label LID models.
Mixed Feelings: Cross-Domain Sentiment Classification of Patient Feedback
Jan 31, 2025Sentiment analysis of patient feedback from the public health domain can aid decision makers in evaluating the provided services. The current paper focuses on free-text comments in patient surveys about general practitioners and psychiatric healthcare, annotated with four sentence-level polarity classes -- positive, negative, mixed and neutral -- while also attempting to alleviate data scarcity by leveraging general-domain sources in the form of reviews. For several different architectures, we compare in-domain and out-of-domain effects, as well as the effects of training joint multi-domain models.
A Collection of Question Answering Datasets for Norwegian
Jan 19, 2025This paper introduces a new suite of question answering datasets for Norwegian; NorOpenBookQA, NorCommonSenseQA, NorTruthfulQA, and NRK-Quiz-QA. The data covers a wide range of skills and knowledge domains, including world knowledge, commonsense reasoning, truthfulness, and knowledge about Norway. Covering both of the written standards of Norwegian - Bokm{\aa}l and Nynorsk - our datasets comprise over 10k question-answer pairs, created by native speakers. We detail our dataset creation approach and present the results of evaluating 11 language models (LMs) in zero- and few-shot regimes. Most LMs perform better in Bokm{\aa}l than Nynorsk, struggle most with commonsense reasoning, and are often untruthful in generating answers to questions. All our datasets and annotation materials are publicly available.
The Impact of Copyrighted Material on Large Language Models: A Norwegian Perspective
Dec 12, 2024



The use of copyrighted materials in training generative language models raises critical legal and ethical questions. This paper presents a framework for and the results of empirically assessing the impact of copyrighted materials on the performance of large language models (LLMs) for Norwegian. We found that both books and newspapers contribute positively when the models are evaluated on a diverse set of Norwegian benchmarks, while fiction works possibly lead to decreased performance. Our experiments could inform the creation of a compensation scheme for authors whose works contribute to AI development.
It's Difficult to be Neutral -- Human and LLM-based Sentiment Annotation of Patient Comments
Apr 29, 2024Sentiment analysis is an important tool for aggregating patient voices, in order to provide targeted improvements in healthcare services. A prerequisite for this is the availability of in-domain data annotated for sentiment. This article documents an effort to add sentiment annotations to free-text comments in patient surveys collected by the Norwegian Institute of Public Health (NIPH). However, annotation can be a time-consuming and resource-intensive process, particularly when it requires domain expertise. We therefore also evaluate a possible alternative to human annotation, using large language models (LLMs) as annotators. We perform an extensive evaluation of the approach for two openly available pretrained LLMs for Norwegian, experimenting with different configurations of prompts and in-context learning, comparing their performance to human annotators. We find that even for zero-shot runs, models perform well above the baseline for binary sentiment, but still cannot compete with human annotators on the full dataset.
Estimating Lexical Complexity from Document-Level Distributions
Apr 01, 2024Existing methods for complexity estimation are typically developed for entire documents. This limitation in scope makes them inapplicable for shorter pieces of text, such as health assessment tools. These typically consist of lists of independent sentences, all of which are too short for existing methods to apply. The choice of wording in these assessment tools is crucial, as both the cognitive capacity and the linguistic competency of the intended patient groups could vary substantially. As a first step towards creating better tools for supporting health practitioners, we develop a two-step approach for estimating lexical complexity that does not rely on any pre-annotated data. We implement our approach for the Norwegian language and verify its effectiveness using statistical testing and a qualitative evaluation of samples from real assessment tools. We also investigate the relationship between our complexity measure and certain features typically associated with complexity in the literature, such as word length, frequency, and the number of syllables.
Annotating Norwegian Language Varieties on Twitter for Part-of-Speech
Oct 12, 2022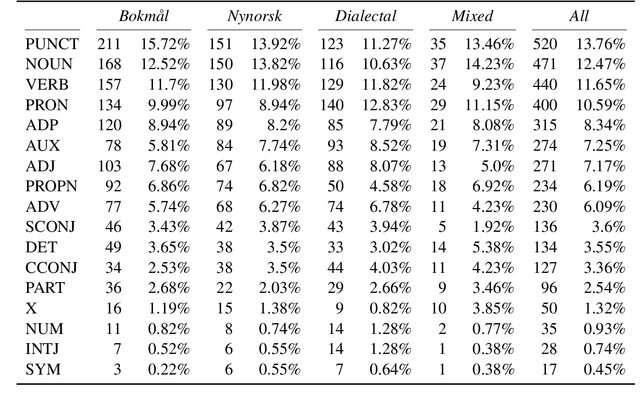
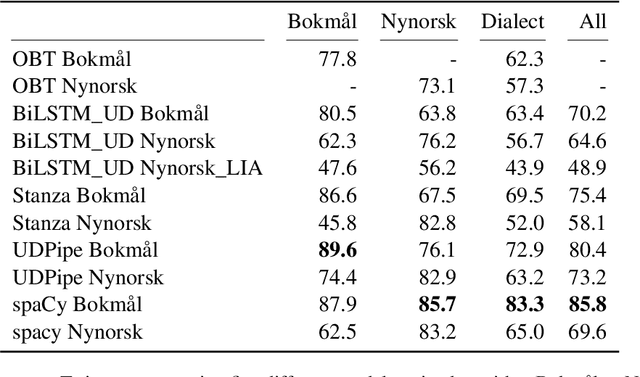
Norwegian Twitter data poses an interesting challenge for Natural Language Processing (NLP) tasks. These texts are difficult for models trained on standardized text in one of the two Norwegian written forms (Bokm{\aa}l and Nynorsk), as they contain both the typical variation of social media text, as well as a large amount of dialectal variety. In this paper we present a novel Norwegian Twitter dataset annotated with POS-tags. We show that models trained on Universal Dependency (UD) data perform worse when evaluated against this dataset, and that models trained on Bokm{\aa}l generally perform better than those trained on Nynorsk. We also see that performance on dialectal tweets is comparable to the written standards for some models. Finally we perform a detailed analysis of the errors that models commonly make on this data.
NorDiaChange: Diachronic Semantic Change Dataset for Norwegian
Jan 13, 2022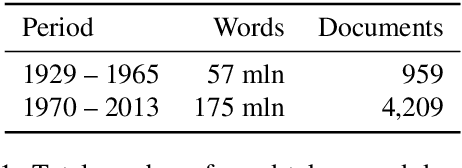
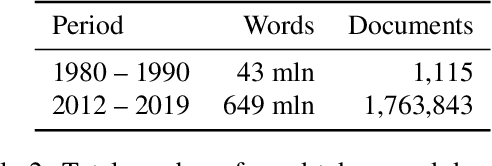
We describe NorDiaChange: the first diachronic semantic change dataset for Norwegian. NorDiaChange comprises two novel subsets, covering about 80 Norwegian nouns manually annotated with graded semantic change over time. Both datasets follow the same annotation procedure and can be used interchangeably as train and test splits for each other. NorDiaChange covers the time periods related to pre- and post-war events, oil and gas discovery in Norway, and technological developments. The annotation was done using the DURel framework and two large historical Norwegian corpora. NorDiaChange is published in full under a permissive license, complete with raw annotation data and inferred diachronic word usage graphs (DWUGs).
NorDial: A Preliminary Corpus of Written Norwegian Dialect Use
Apr 11, 2021
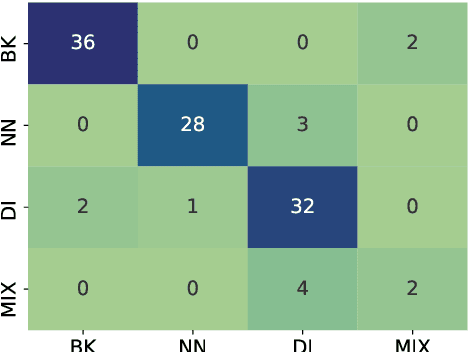
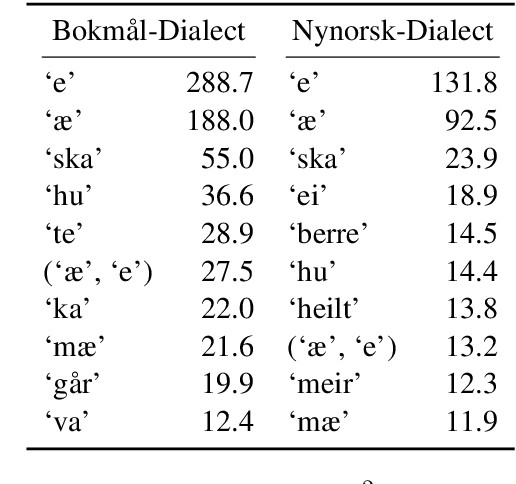
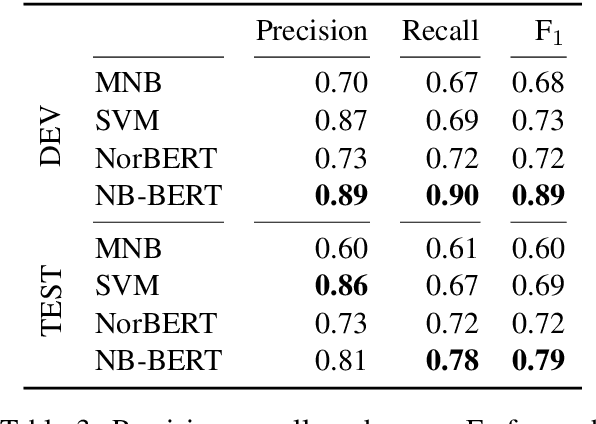
Norway has a large amount of dialectal variation, as well as a general tolerance to its use in the public sphere. There are, however, few available resources to study this variation and its change over time and in more informal areas, \eg on social media. In this paper, we propose a first step to creating a corpus of dialectal variation of written Norwegian. We collect a small corpus of tweets and manually annotate them as Bokm{\aa}l, Nynorsk, any dialect, or a mix. We further perform preliminary experiments with state-of-the-art models, as well as an analysis of the data to expand this corpus in the future. Finally, we make the annotations and models available for future work.