 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat Media Frames Reveal About Stance: A Dataset and Study about Memes in Climate Change Discourse
May 22, 2025Media framing refers to the emphasis on specific aspects of perceived reality to shape how an issue is defined and understood. Its primary purpose is to shape public perceptions often in alignment with the authors' opinions and stances. However, the interaction between stance and media frame remains largely unexplored. In this work, we apply an interdisciplinary approach to conceptualize and computationally explore this interaction with internet memes on climate change. We curate CLIMATEMEMES, the first dataset of climate-change memes annotated with both stance and media frames, inspired by research in communication science. CLIMATEMEMES includes 1,184 memes sourced from 47 subreddits, enabling analysis of frame prominence over time and communities, and sheds light on the framing preferences of different stance holders. We propose two meme understanding tasks: stance detection and media frame detection. We evaluate LLaVA-NeXT and Molmo in various setups, and report the corresponding results on their LLM backbone. Human captions consistently enhance performance. Synthetic captions and human-corrected OCR also help occasionally. Our findings highlight that VLMs perform well on stance, but struggle on frames, where LLMs outperform VLMs. Finally, we analyze VLMs' limitations in handling nuanced frames and stance expressions on climate change internet memes.
Enabling Systematic Generalization in Abstract Spatial Reasoning through Meta-Learning for Compositionality
Apr 02, 2025Systematic generalization refers to the capacity to understand and generate novel combinations from known components. Despite recent progress by large language models (LLMs) across various domains, these models often fail to extend their knowledge to novel compositional scenarios, revealing notable limitations in systematic generalization. There has been an ongoing debate about whether neural networks possess the capacity for systematic generalization, with recent studies suggesting that meta-learning approaches designed for compositionality can significantly enhance this ability. However, these insights have largely been confined to linguistic problems, leaving their applicability to other tasks an open question. In this study, we extend the approach of meta-learning for compositionality to the domain of abstract spatial reasoning. To this end, we introduce $\textit{SYGAR}$-a dataset designed to evaluate the capacity of models to systematically generalize from known geometric transformations (e.g., translation, rotation) of two-dimensional objects to novel combinations of these transformations (e.g., translation+rotation). Our results show that a transformer-based encoder-decoder model, trained via meta-learning for compositionality, can systematically generalize to previously unseen transformation compositions, significantly outperforming state-of-the-art LLMs, including o3-mini, GPT-4o, and Gemini 2.0 Flash, which fail to exhibit similar systematic behavior. Our findings highlight the effectiveness of meta-learning in promoting systematicity beyond linguistic tasks, suggesting a promising direction toward more robust and generalizable models.
Improving Automatic Fetal Biometry Measurement with Swoosh Activation Function
Dec 16, 2024The measurement of fetal thalamus diameter (FTD) and fetal head circumference (FHC) are crucial in identifying abnormal fetal thalamus development as it may lead to certain neuropsychiatric disorders in later life. However, manual measurements from 2D-US images are laborious, prone to high inter-observer variability, and complicated by the high signal-to-noise ratio nature of the images. Deep learning-based landmark detection approaches have shown promise in measuring biometrics from US images, but the current state-of-the-art (SOTA) algorithm, BiometryNet, is inadequate for FTD and FHC measurement due to its inability to account for the fuzzy edges of these structures and the complex shape of the FTD structure. To address these inadequacies, we propose a novel Swoosh Activation Function (SAF) designed to enhance the regularization of heatmaps produced by landmark detection algorithms. Our SAF serves as a regularization term to enforce an optimum mean squared error (MSE) level between predicted heatmaps, reducing the dispersiveness of hotspots in predicted heatmaps. Our experimental results demonstrate that SAF significantly improves the measurement performances of FTD and FHC with higher intraclass correlation coefficient scores in FTD and lower mean difference scores in FHC measurement than those of the current SOTA algorithm BiometryNet. Moreover, our proposed SAF is highly generalizable and architecture-agnostic. The SAF's coefficients can be configured for different tasks, making it highly customizable. Our study demonstrates that the SAF activation function is a novel method that can improve measurement accuracy in fetal biometry landmark detection. This improvement has the potential to contribute to better fetal monitoring and improved neonatal outcomes.
CLIMATELI: Evaluating Entity Linking on Climate Change Data
Jun 24, 2024



Climate Change (CC) is a pressing topic of global importance, attracting increasing attention across research fields, from social sciences to Natural Language Processing (NLP). CC is also discussed in various settings and communication platforms, from academic publications to social media forums. Understanding who and what is mentioned in such data is a first critical step to gaining new insights into CC. We present CLIMATELI (CLIMATe Entity LInking), the first manually annotated CC dataset that links 3,087 entity spans to Wikipedia. Using CLIMATELI (CLIMATe Entity LInking), we evaluate existing entity linking (EL) systems on the CC topic across various genres and propose automated filtering methods for CC entities. We find that the performance of EL models notably lags behind humans at both token and entity levels. Testing within the scope of retaining or excluding non-nominal and/or non-CC entities particularly impacts the models' performances.
MaiNLP at SemEval-2024 Task 1: Analyzing Source Language Selection in Cross-Lingual Textual Relatedness
Apr 03, 2024

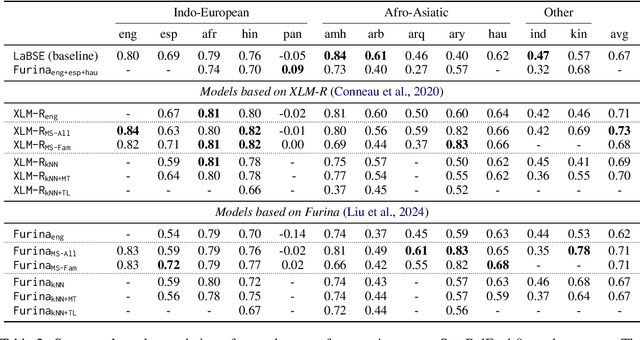
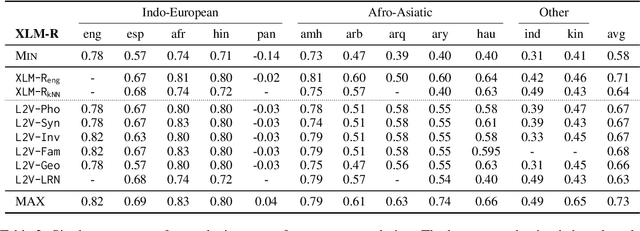
This paper presents our system developed for the SemEval-2024 Task 1: Semantic Textual Relatedness (STR), on Track C: Cross-lingual. The task aims to detect semantic relatedness of two sentences in a given target language without access to direct supervision (i.e. zero-shot cross-lingual transfer). To this end, we focus on different source language selection strategies on two different pre-trained languages models: XLM-R and Furina. We experiment with 1) single-source transfer and select source languages based on typological similarity, 2) augmenting English training data with the two nearest-neighbor source languages, and 3) multi-source transfer where we compare selecting on all training languages against languages from the same family. We further study machine translation-based data augmentation and the impact of script differences. Our submission achieved the first place in the C8 (Kinyarwanda) test set.
Constructions Are So Difficult That Even Large Language Models Get Them Right for the Wrong Reasons
Mar 26, 2024
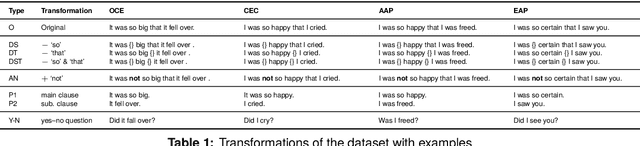
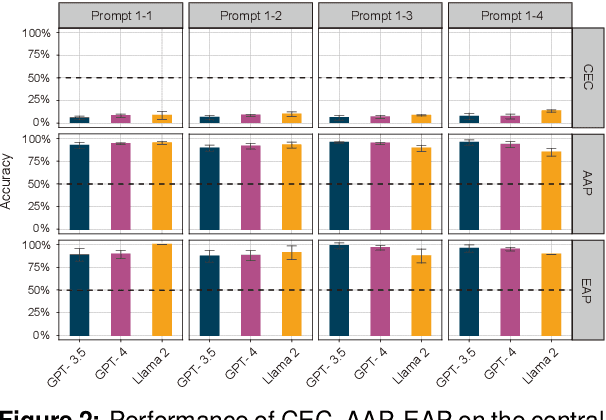
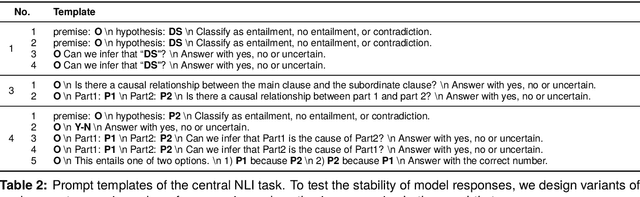
In this paper, we make a contribution that can be understood from two perspectives: from an NLP perspective, we introduce a small challenge dataset for NLI with large lexical overlap, which minimises the possibility of models discerning entailment solely based on token distinctions, and show that GPT-4 and Llama 2 fail it with strong bias. We then create further challenging sub-tasks in an effort to explain this failure. From a Computational Linguistics perspective, we identify a group of constructions with three classes of adjectives which cannot be distinguished by surface features. This enables us to probe for LLM's understanding of these constructions in various ways, and we find that they fail in a variety of ways to distinguish between them, suggesting that they don't adequately represent their meaning or capture the lexical properties of phrasal heads.