 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaiNLP at SemEval-2024 Task 1: Analyzing Source Language Selection in Cross-Lingual Textual Relatedness
Apr 03, 2024

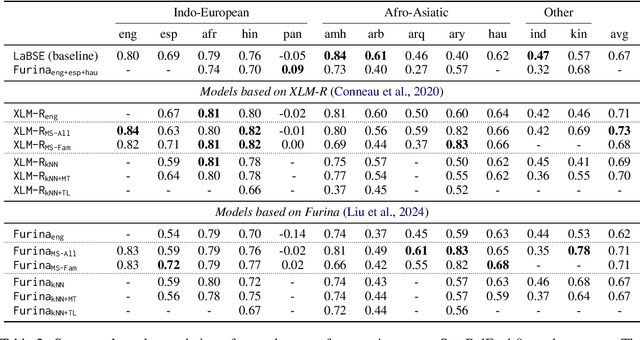
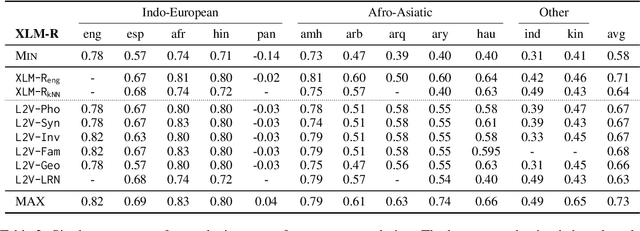
This paper presents our system developed for the SemEval-2024 Task 1: Semantic Textual Relatedness (STR), on Track C: Cross-lingual. The task aims to detect semantic relatedness of two sentences in a given target language without access to direct supervision (i.e. zero-shot cross-lingual transfer). To this end, we focus on different source language selection strategies on two different pre-trained languages models: XLM-R and Furina. We experiment with 1) single-source transfer and select source languages based on typological similarity, 2) augmenting English training data with the two nearest-neighbor source languages, and 3) multi-source transfer where we compare selecting on all training languages against languages from the same family. We further study machine translation-based data augmentation and the impact of script differences. Our submission achieved the first place in the C8 (Kinyarwanda) test set.
Sebastian, Basti, Wastl?! Recognizing Named Entities in Bavarian Dialectal Data
Mar 19, 2024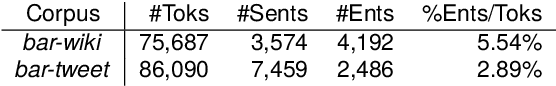



Named Entity Recognition (NER) is a fundamental task to extract key information from texts, but annotated resources are scarce for dialects. This paper introduces the first dialectal NER dataset for German, BarNER, with 161K tokens annotated on Bavarian Wikipedia articles (bar-wiki) and tweets (bar-tweet), using a schema adapted from German CoNLL 2006 and GermEval. The Bavarian dialect differs from standard German in lexical distribution, syntactic construction, and entity information. We conduct in-domain, cross-domain, sequential, and joint experiments on two Bavarian and three German corpora and present the first comprehensive NER results on Bavarian. Incorporating knowledge from the larger German NER (sub-)datasets notably improves on bar-wiki and moderately on bar-tweet. Inversely, training first on Bavarian contributes slightly to the seminal German CoNLL 2006 corpus. Moreover, with gold dialect labels on Bavarian tweets, we assess multi-task learning between five NER and two Bavarian-German dialect identification tasks and achieve NER SOTA on bar-wiki. We substantiate the necessity of our low-resource BarNER corpus and the importance of diversity in dialects, genres, and topics in enhancing model performance.