 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConstructions Are So Difficult That Even Large Language Models Get Them Right for the Wrong Reasons
Mar 26, 2024
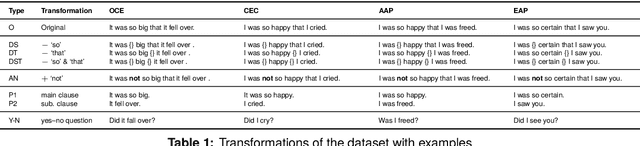
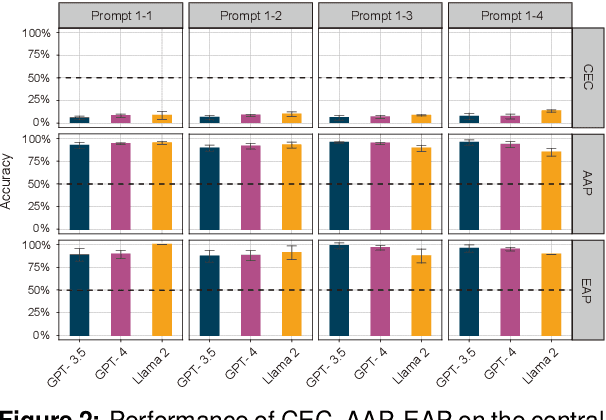
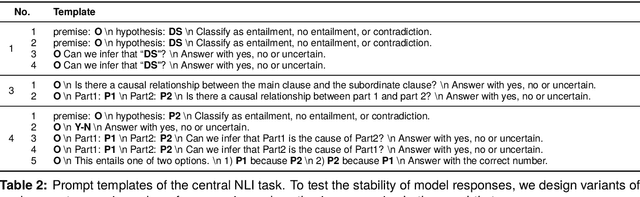
In this paper, we make a contribution that can be understood from two perspectives: from an NLP perspective, we introduce a small challenge dataset for NLI with large lexical overlap, which minimises the possibility of models discerning entailment solely based on token distinctions, and show that GPT-4 and Llama 2 fail it with strong bias. We then create further challenging sub-tasks in an effort to explain this failure. From a Computational Linguistics perspective, we identify a group of constructions with three classes of adjectives which cannot be distinguished by surface features. This enables us to probe for LLM's understanding of these constructions in various ways, and we find that they fail in a variety of ways to distinguish between them, suggesting that they don't adequately represent their meaning or capture the lexical properties of phrasal heads.
Wav2Gloss: Generating Interlinear Glossed Text from Speech
Mar 19, 2024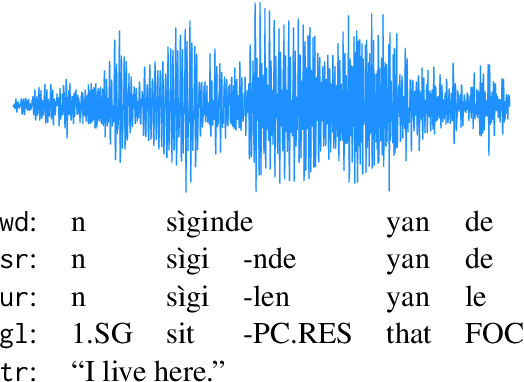
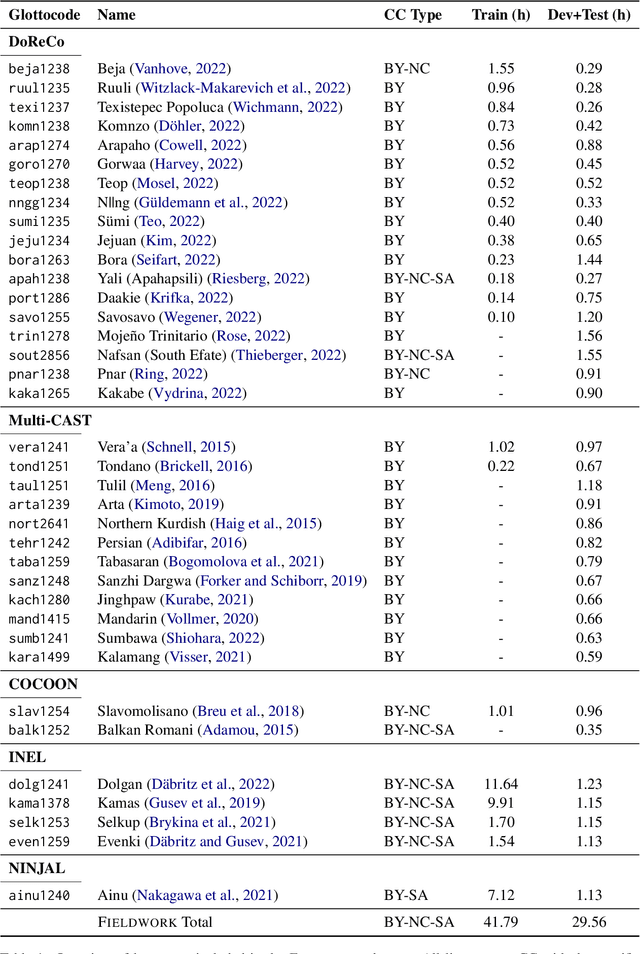
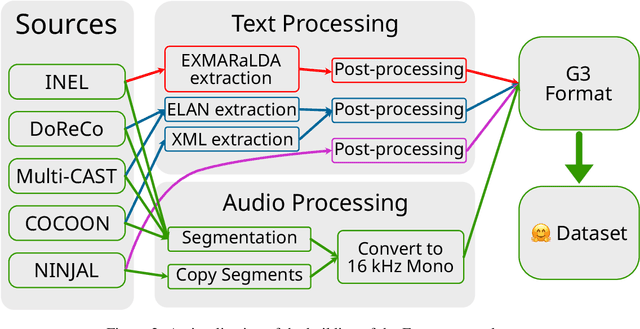
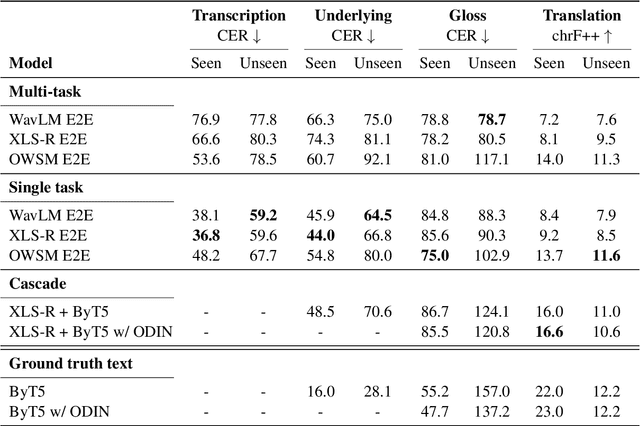
Thousands of the world's languages are in danger of extinction--a tremendous threat to cultural identities and human language diversity. Interlinear Glossed Text (IGT) is a form of linguistic annotation that can support documentation and resource creation for these languages' communities. IGT typically consists of (1) transcriptions, (2) morphological segmentation, (3) glosses, and (4) free translations to a majority language. We propose Wav2Gloss: a task to extract these four annotation components automatically from speech, and introduce the first dataset to this end, Fieldwork: a corpus of speech with all these annotations covering 37 languages with standard formatting and train/dev/test splits. We compare end-to-end and cascaded Wav2Gloss methods, with analysis suggesting that pre-trained decoders assist with translation and glossing, that multi-task and multilingual approaches are underperformant, and that end-to-end systems perform better than cascaded systems, despite the text-only systems' advantages. We provide benchmarks to lay the ground work for future research on IGT generation from speech.
GlossLM: Multilingual Pretraining for Low-Resource Interlinear Glossing
Mar 11, 2024



A key aspect of language documentation is the creation of annotated text in a format such as interlinear glossed text (IGT), which captures fine-grained morphosyntactic analyses in a morpheme-by-morpheme format. Prior work has explored methods to automatically generate IGT in order to reduce the time cost of language analysis. However, many languages (particularly those requiring preservation) lack sufficient IGT data to train effective models, and crosslingual transfer has been proposed as a method to overcome this limitation. We compile the largest existing corpus of IGT data from a variety of sources, covering over 450k examples across 1.8k languages, to enable research on crosslingual transfer and IGT generation. Then, we pretrain a large multilingual model on a portion of this corpus, and further finetune it to specific languages. Our model is competitive with state-of-the-art methods for segmented data and large monolingual datasets. Meanwhile, our model outperforms SOTA models on unsegmented text and small corpora by up to 6.6% morpheme accuracy, demonstrating the effectiveness of crosslingual transfer for low-resource languages.
Hire a Linguist!: Learning Endangered Languages with In-Context Linguistic Descriptions
Feb 28, 2024



How can large language models (LLMs) process and translate endangered languages? Many languages lack a large corpus to train a decent LLM; therefore existing LLMs rarely perform well in unseen, endangered languages. On the contrary, we observe that 2000 endangered languages, though without a large corpus, have a grammar book or a dictionary. We propose LINGOLLM, a training-free approach to enable an LLM to process unseen languages that hardly occur in its pre-training. Our key insight is to demonstrate linguistic knowledge of an unseen language in an LLM's prompt, including a dictionary, a grammar book, and morphologically analyzed input text. We implement LINGOLLM on top of two models, GPT-4 and Mixtral, and evaluate their performance on 5 tasks across 8 endangered or low-resource languages. Our results show that LINGOLLM elevates translation capability from GPT-4's 0 to 10.5 BLEU for 10 language directions. Our findings demonstrate the tremendous value of linguistic knowledge in the age of LLMs for endangered languages. Our data, code, and model generations can be found at https://github.com/LLiLab/llm4endangeredlang.
Construction Grammar Provides Unique Insight into Neural Language Models
Feb 04, 2023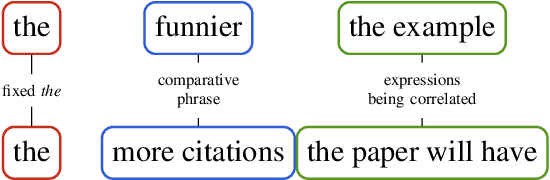



Construction Grammar (CxG) has recently been used as the basis for probing studies that have investigated the performance of large pretrained language models (PLMs) with respect to the structure and meaning of constructions. In this position paper, we make suggestions for the continuation and augmentation of this line of research. We look at probing methodology that was not designed with CxG in mind, as well as probing methodology that was designed for specific constructions. We analyse selected previous work in detail, and provide our view of the most important challenges and research questions that this promising new field faces.
Language Embeddings for Typology and Cross-lingual Transfer Learning
Jun 03, 2021
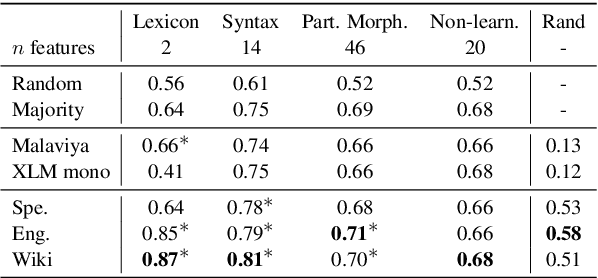
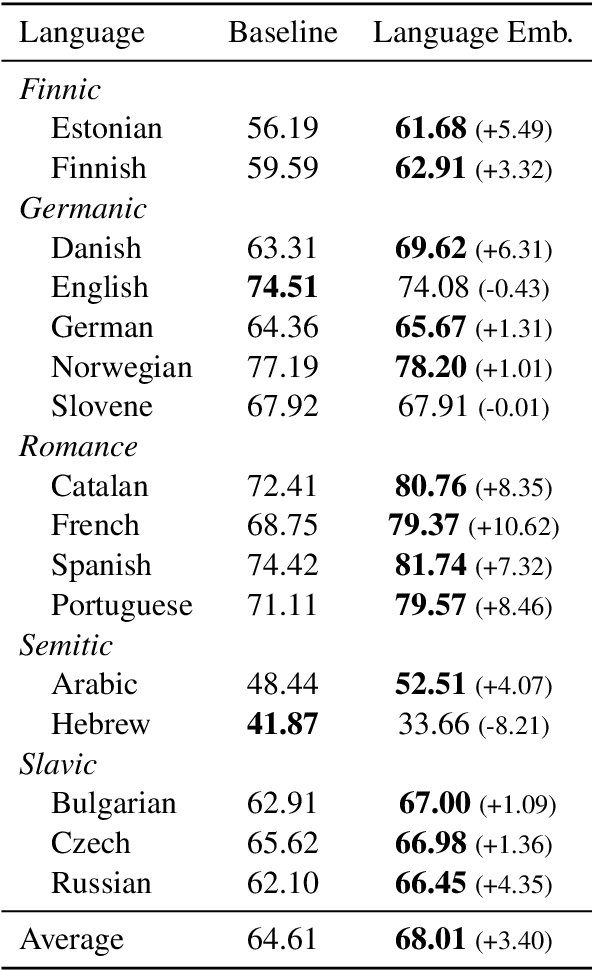
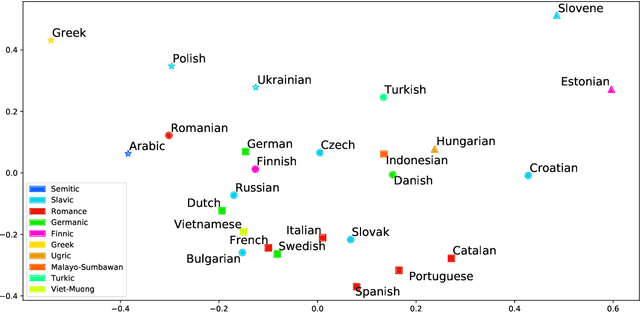
Cross-lingual language tasks typically require a substantial amount of annotated data or parallel translation data. We explore whether language representations that capture relationships among languages can be learned and subsequently leveraged in cross-lingual tasks without the use of parallel data. We generate dense embeddings for 29 languages using a denoising autoencoder, and evaluate the embeddings using the World Atlas of Language Structures (WALS) and two extrinsic tasks in a zero-shot setting: cross-lingual dependency parsing and cross-lingual natural language inference.