 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePPDiff: Diffusing in Hybrid Sequence-Structure Space for Protein-Protein Complex Design
Jun 13, 2025Designing protein-binding proteins with high affinity is critical in biomedical research and biotechnology. Despite recent advancements targeting specific proteins, the ability to create high-affinity binders for arbitrary protein targets on demand, without extensive rounds of wet-lab testing, remains a significant challenge. Here, we introduce PPDiff, a diffusion model to jointly design the sequence and structure of binders for arbitrary protein targets in a non-autoregressive manner. PPDiffbuilds upon our developed Sequence Structure Interleaving Network with Causal attention layers (SSINC), which integrates interleaved self-attention layers to capture global amino acid correlations, k-nearest neighbor (kNN) equivariant graph layers to model local interactions in three-dimensional (3D) space, and causal attention layers to simplify the intricate interdependencies within the protein sequence. To assess PPDiff, we curate PPBench, a general protein-protein complex dataset comprising 706,360 complexes from the Protein Data Bank (PDB). The model is pretrained on PPBenchand finetuned on two real-world applications: target-protein mini-binder complex design and antigen-antibody complex design. PPDiffconsistently surpasses baseline methods, achieving success rates of 50.00%, 23.16%, and 16.89% for the pretraining task and the two downstream applications, respectively.
Natural Language Guided Ligand-Binding Protein Design
Jun 11, 2025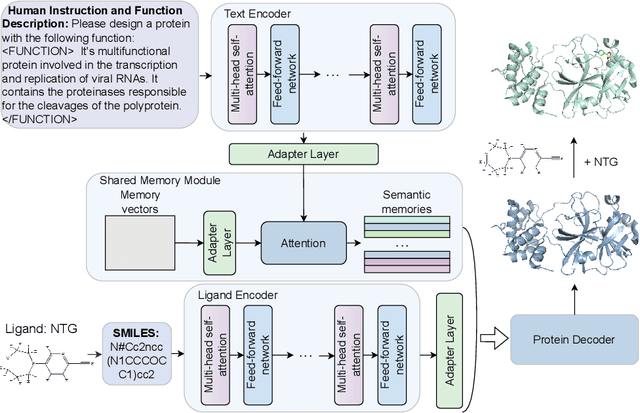

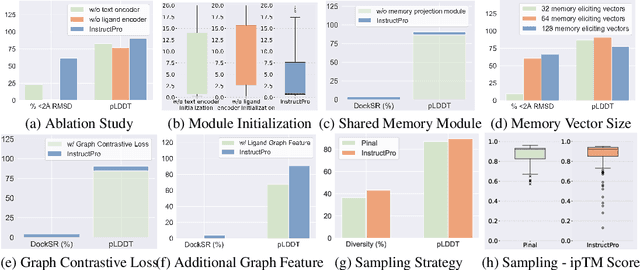
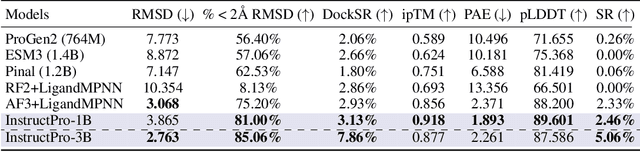
Can AI protein models follow human language instructions and design proteins with desired functions (e.g. binding to a ligand)? Designing proteins that bind to a given ligand is crucial in a wide range of applications in biology and chemistry. Most prior AI models are trained on protein-ligand complex data, which is scarce due to the high cost and time requirements of laboratory experiments. In contrast, there is a substantial body of human-curated text descriptions about protein-ligand interactions and ligand formula. In this paper, we propose InstructPro, a family of protein generative models that follow natural language instructions to design ligand-binding proteins. Given a textual description of the desired function and a ligand formula in SMILES, InstructPro generates protein sequences that are functionally consistent with the specified instructions. We develop the model architecture, training strategy, and a large-scale dataset, InstructProBench, to support both training and evaluation. InstructProBench consists of 9,592,829 triples of (function description, ligand formula, protein sequence). We train two model variants: InstructPro-1B (with 1 billion parameters) and InstructPro-3B~(with 3 billion parameters). Both variants consistently outperform strong baselines, including ProGen2, ESM3, and Pinal. Notably, InstructPro-1B achieves the highest docking success rate (81.52% at moderate confidence) and the lowest average root mean square deviation (RMSD) compared to ground truth structures (4.026{\AA}). InstructPro-3B further descreases the average RMSD to 2.527{\AA}, demonstrating InstructPro's ability to generate ligand-binding proteins that align with the functional specifications.
JanusDNA: A Powerful Bi-directional Hybrid DNA Foundation Model
May 22, 2025Large language models (LLMs) have revolutionized natural language processing and are increasingly applied to other sequential data types, including genetic sequences. However, adapting LLMs to genomics presents significant challenges. Capturing complex genomic interactions requires modeling long-range dependencies within DNA sequences, where interactions often span over 10,000 base pairs, even within a single gene, posing substantial computational burdens under conventional model architectures and training paradigms. Moreover, standard LLM training approaches are suboptimal for DNA: autoregressive training, while efficient, supports only unidirectional understanding. However, DNA is inherently bidirectional, e.g., bidirectional promoters regulate transcription in both directions and account for nearly 11% of human gene expression. Masked language models (MLMs) allow bidirectional understanding but are inefficient, as only masked tokens contribute to the loss per step. To address these limitations, we introduce JanusDNA, the first bidirectional DNA foundation model built upon a novel pretraining paradigm that combines the optimization efficiency of autoregressive modeling with the bidirectional comprehension of masked modeling. JanusDNA adopts a hybrid Mamba, Attention and Mixture of Experts (MoE) architecture, combining long-range modeling of Attention with efficient sequential learning of Mamba. MoE layers further scale model capacity via sparse activation while keeping computational cost low. Notably, JanusDNA processes up to 1 million base pairs at single nucleotide resolution on a single 80GB GPU. Extensive experiments and ablations show JanusDNA achieves new SOTA results on three genomic representation benchmarks, outperforming models with 250x more activated parameters. Code: https://github.com/Qihao-Duan/JanusDNA
Generative Enzyme Design Guided by Functionally Important Sites and Small-Molecule Substrates
May 13, 2024Enzymes are genetically encoded biocatalysts capable of accelerating chemical reactions. How can we automatically design functional enzymes? In this paper, we propose EnzyGen, an approach to learn a unified model to design enzymes across all functional families. Our key idea is to generate an enzyme's amino acid sequence and their three-dimensional (3D) coordinates based on functionally important sites and substrates corresponding to a desired catalytic function. These sites are automatically mined from enzyme databases. EnzyGen consists of a novel interleaving network of attention and neighborhood equivariant layers, which captures both long-range correlation in an entire protein sequence and local influence from nearest amino acids in 3D space. To learn the generative model, we devise a joint training objective, including a sequence generation loss, a position prediction loss and an enzyme-substrate interaction loss. We further construct EnzyBench, a dataset with 3157 enzyme families, covering all available enzymes within the protein data bank (PDB). Experimental results show that our EnzyGen consistently achieves the best performance across all 323 testing families, surpassing the best baseline by 10.79% in terms of substrate binding affinity. These findings demonstrate EnzyGen's superior capability in designing well-folded and effective enzymes binding to specific substrates with high affinities.
SurfPro: Functional Protein Design Based on Continuous Surface
May 07, 2024How can we design proteins with desired functions? We are motivated by a chemical intuition that both geometric structure and biochemical properties are critical to a protein's function. In this paper, we propose SurfPro, a new method to generate functional proteins given a desired surface and its associated biochemical properties. SurfPro comprises a hierarchical encoder that progressively models the geometric shape and biochemical features of a protein surface, and an autoregressive decoder to produce an amino acid sequence. We evaluate SurfPro on a standard inverse folding benchmark CATH 4.2 and two functional protein design tasks: protein binder design and enzyme design. Our SurfPro consistently surpasses previous state-of-the-art inverse folding methods, achieving a recovery rate of 57.78% on CATH 4.2 and higher success rates in terms of protein-protein binding and enzyme-substrate interaction scores.
Hire a Linguist!: Learning Endangered Languages with In-Context Linguistic Descriptions
Feb 28, 2024



How can large language models (LLMs) process and translate endangered languages? Many languages lack a large corpus to train a decent LLM; therefore existing LLMs rarely perform well in unseen, endangered languages. On the contrary, we observe that 2000 endangered languages, though without a large corpus, have a grammar book or a dictionary. We propose LINGOLLM, a training-free approach to enable an LLM to process unseen languages that hardly occur in its pre-training. Our key insight is to demonstrate linguistic knowledge of an unseen language in an LLM's prompt, including a dictionary, a grammar book, and morphologically analyzed input text. We implement LINGOLLM on top of two models, GPT-4 and Mixtral, and evaluate their performance on 5 tasks across 8 endangered or low-resource languages. Our results show that LINGOLLM elevates translation capability from GPT-4's 0 to 10.5 BLEU for 10 language directions. Our findings demonstrate the tremendous value of linguistic knowledge in the age of LLMs for endangered languages. Our data, code, and model generations can be found at https://github.com/LLiLab/llm4endangeredlang.
Functional Geometry Guided Protein Sequence and Backbone Structure Co-Design
Oct 09, 2023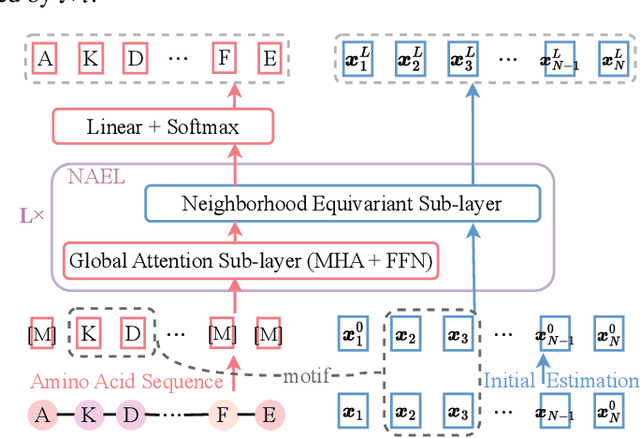
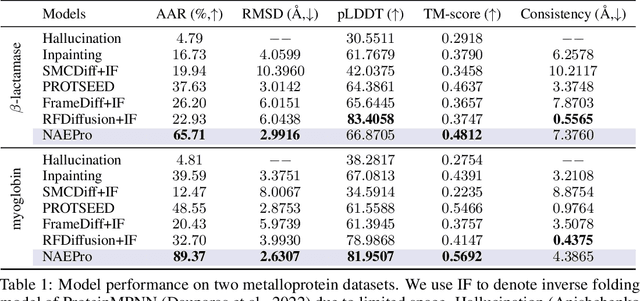
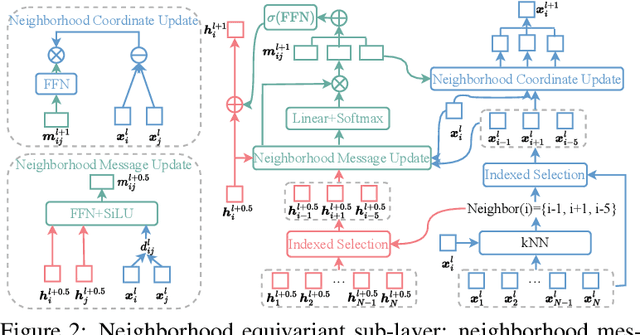
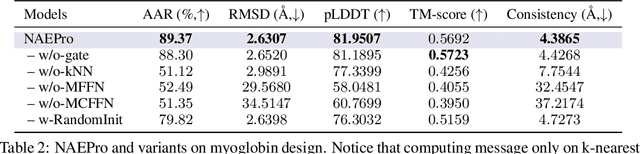
Proteins are macromolecules responsible for essential functions in almost all living organisms. Designing reasonable proteins with desired functions is crucial. A protein's sequence and structure are strongly correlated and they together determine its function. In this paper, we propose NAEPro, a model to jointly design Protein sequence and structure based on automatically detected functional sites. NAEPro is powered by an interleaving network of attention and equivariant layers, which can capture global correlation in a whole sequence and local influence from nearest amino acids in three dimensional (3D) space. Such an architecture facilitates effective yet economic message passing at two levels. We evaluate our model and several strong baselines on two protein datasets, $\beta$-lactamase and myoglobin. Experimental results show that our model consistently achieves the highest amino acid recovery rate, TM-score, and the lowest RMSD among all competitors. These findings prove the capability of our model to design protein sequences and structures that closely resemble their natural counterparts. Furthermore, in-depth analysis further confirms our model's ability to generate highly effective proteins capable of binding to their target metallocofactors. We provide code, data and models in Github.
Joint Design of Protein Sequence and Structure based on Motifs
Oct 04, 2023



Designing novel proteins with desired functions is crucial in biology and chemistry. However, most existing work focus on protein sequence design, leaving protein sequence and structure co-design underexplored. In this paper, we propose GeoPro, a method to design protein backbone structure and sequence jointly. Our motivation is that protein sequence and its backbone structure constrain each other, and thus joint design of both can not only avoid nonfolding and misfolding but also produce more diverse candidates with desired functions. To this end, GeoPro is powered by an equivariant encoder for three-dimensional (3D) backbone structure and a protein sequence decoder guided by 3D geometry. Experimental results on two biologically significant metalloprotein datasets, including $\beta$-lactamases and myoglobins, show that our proposed GeoPro outperforms several strong baselines on most metrics. Remarkably, our method discovers novel $\beta$-lactamases and myoglobins which are not present in protein data bank (PDB) and UniProt. These proteins exhibit stable folding and active site environments reminiscent of those of natural proteins, demonstrating their excellent potential to be biologically functional.
INSTRUCTSCORE: Towards Explainable Text Generation Evaluation with Automatic Feedback
May 23, 2023



The field of automatic evaluation of text generation made tremendous progress in the last few years. In particular, since the advent of neural metrics, like COMET, BLEURT, and SEScore2, the newest generation of metrics show a high correlation with human judgment. Unfortunately, quality scores generated with neural metrics are not interpretable, and it is unclear which part of the generation output is criticized by the metrics. To address this limitation, we present INSTRUCTSCORE, an open-source, explainable evaluation metric for text generation. By harnessing both explicit human instruction and the implicit knowledge of GPT4, we fine-tune a LLAMA model to create an evaluative metric that can produce a diagnostic report aligned with human judgment. We evaluate INSTRUCTSCORE on the WMT22 Zh-En translation task, where our 7B model surpasses other LLM-based baselines, including those based on 175B GPT3. Impressively, our INSTRUCTSCORE, even without direct supervision from human-rated data, achieves performance levels on par with state-of-the-art metrics like COMET22, which was fine-tuned on human ratings.
Importance Weighted Expectation-Maximization for Protein Sequence Design
Apr 30, 2023Designing protein sequences with desired biological function is crucial in biology and chemistry. Recent machine learning methods use a surrogate sequence-function model to replace the expensive wet-lab validation. How can we efficiently generate diverse and novel protein sequences with high fitness? In this paper, we propose IsEM-Pro, an approach to generate protein sequences towards a given fitness criterion. At its core, IsEM-Pro is a latent generative model, augmented by combinatorial structure features from a separately learned Markov random fields (MRFs). We develop an Monte Carlo Expectation-Maximization method (MCEM) to learn the model. During inference, sampling from its latent space enhances diversity while its MRFs features guide the exploration in high fitness regions. Experiments on eight protein sequence design tasks show that our IsEM-Pro outperforms the previous best methods by at least 55% on average fitness score and generates more diverse and novel protein sequences.