 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFusion or Confusion? Multimodal Complexity Is Not All You Need
Dec 28, 2025Deep learning architectures for multimodal learning have increased in complexity, driven by the assumption that multimodal-specific methods improve performance. We challenge this assumption through a large-scale empirical study reimplementing 19 high-impact methods under standardized conditions, evaluating them across nine diverse datasets with up to 23 modalities, and testing their generalizability to new tasks beyond their original scope, including settings with missing modalities. We propose a Simple Baseline for Multimodal Learning (SimBaMM), a straightforward late-fusion Transformer architecture, and demonstrate that under standardized experimental conditions with rigorous hyperparameter tuning of all methods, more complex architectures do not reliably outperform SimBaMM. Statistical analysis indicates that more complex methods perform comparably to SimBaMM and frequently do not reliably outperform well-tuned unimodal baselines, especially in the small-data regime considered in many original studies. To support our findings, we include a case study of a recent multimodal learning method highlighting the methodological shortcomings in the literature. In addition, we provide a pragmatic reliability checklist to promote comparable, robust, and trustworthy future evaluations. In summary, we argue for a shift in focus: away from the pursuit of architectural novelty and toward methodological rigor.
Cohort-Based Active Modality Acquisition
May 22, 2025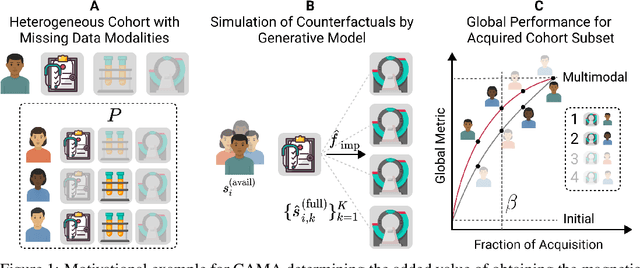
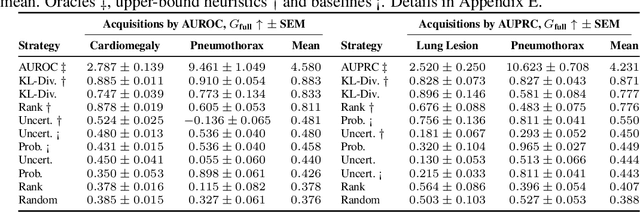
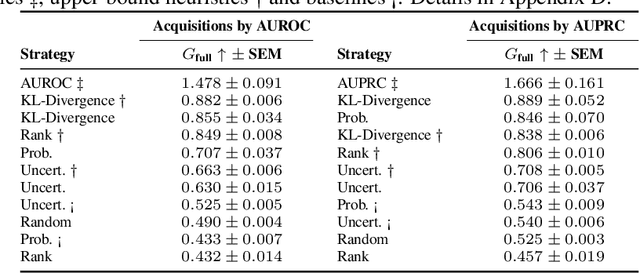
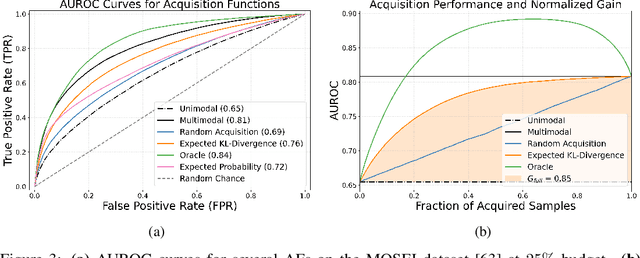
Real-world machine learning applications often involve data from multiple modalities that must be integrated effectively to make robust predictions. However, in many practical settings, not all modalities are available for every sample, and acquiring additional modalities can be costly. This raises the question: which samples should be prioritized for additional modality acquisition when resources are limited? While prior work has explored individual-level acquisition strategies and training-time active learning paradigms, test-time and cohort-based acquisition remain underexplored despite their importance in many real-world settings. We introduce Cohort-based Active Modality Acquisition (CAMA), a novel test-time setting to formalize the challenge of selecting which samples should receive additional modalities. We derive acquisition strategies that leverage a combination of generative imputation and discriminative modeling to estimate the expected benefit of acquiring missing modalities based on common evaluation metrics. We also introduce upper-bound heuristics that provide performance ceilings to benchmark acquisition strategies. Experiments on common multimodal datasets demonstrate that our proposed imputation-based strategies can more effectively guide the acquisition of new samples in comparison to those relying solely on unimodal information, entropy guidance, and random selections. Our work provides an effective solution for optimizing modality acquisition at the cohort level, enabling better utilization of resources in constrained settings.
JanusDNA: A Powerful Bi-directional Hybrid DNA Foundation Model
May 22, 2025Large language models (LLMs) have revolutionized natural language processing and are increasingly applied to other sequential data types, including genetic sequences. However, adapting LLMs to genomics presents significant challenges. Capturing complex genomic interactions requires modeling long-range dependencies within DNA sequences, where interactions often span over 10,000 base pairs, even within a single gene, posing substantial computational burdens under conventional model architectures and training paradigms. Moreover, standard LLM training approaches are suboptimal for DNA: autoregressive training, while efficient, supports only unidirectional understanding. However, DNA is inherently bidirectional, e.g., bidirectional promoters regulate transcription in both directions and account for nearly 11% of human gene expression. Masked language models (MLMs) allow bidirectional understanding but are inefficient, as only masked tokens contribute to the loss per step. To address these limitations, we introduce JanusDNA, the first bidirectional DNA foundation model built upon a novel pretraining paradigm that combines the optimization efficiency of autoregressive modeling with the bidirectional comprehension of masked modeling. JanusDNA adopts a hybrid Mamba, Attention and Mixture of Experts (MoE) architecture, combining long-range modeling of Attention with efficient sequential learning of Mamba. MoE layers further scale model capacity via sparse activation while keeping computational cost low. Notably, JanusDNA processes up to 1 million base pairs at single nucleotide resolution on a single 80GB GPU. Extensive experiments and ablations show JanusDNA achieves new SOTA results on three genomic representation benchmarks, outperforming models with 250x more activated parameters. Code: https://github.com/Qihao-Duan/JanusDNA
Large Language Models are Powerful EHR Encoders
Feb 24, 2025Electronic Health Records (EHRs) offer rich potential for clinical prediction, yet their inherent complexity and heterogeneity pose significant challenges for traditional machine learning approaches. Domain-specific EHR foundation models trained on large collections of unlabeled EHR data have demonstrated promising improvements in predictive accuracy and generalization; however, their training is constrained by limited access to diverse, high-quality datasets and inconsistencies in coding standards and healthcare practices. In this study, we explore the possibility of using general-purpose Large Language Models (LLMs) based embedding methods as EHR encoders. By serializing patient records into structured Markdown text, transforming codes into human-readable descriptors, we leverage the extensive generalization capabilities of LLMs pretrained on vast public corpora, thereby bypassing the need for proprietary medical datasets. We systematically evaluate two state-of-the-art LLM-embedding models, GTE-Qwen2-7B-Instruct and LLM2Vec-Llama3.1-8B-Instruct, across 15 diverse clinical prediction tasks from the EHRSHOT benchmark, comparing their performance to an EHRspecific foundation model, CLIMBR-T-Base, and traditional machine learning baselines. Our results demonstrate that LLM-based embeddings frequently match or exceed the performance of specialized models, even in few-shot settings, and that their effectiveness scales with the size of the underlying LLM and the available context window. Overall, our findings demonstrate that repurposing LLMs for EHR encoding offers a scalable and effective approach for clinical prediction, capable of overcoming the limitations of traditional EHR modeling and facilitating more interoperable and generalizable healthcare applications.
Diffsurv: Differentiable sorting for censored time-to-event data
Apr 26, 2023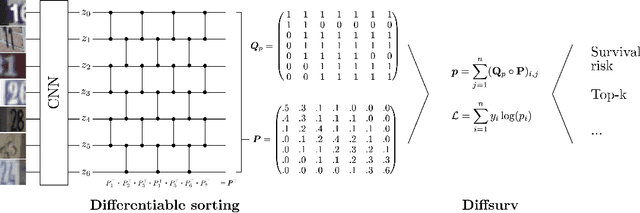

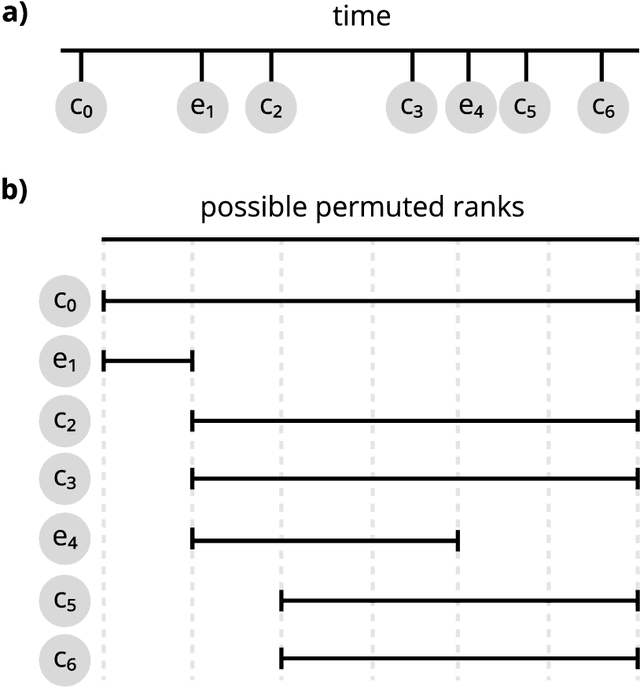
Survival analysis is a crucial semi-supervised task in machine learning with numerous real-world applications, particularly in healthcare. Currently, the most common approach to survival analysis is based on Cox's partial likelihood, which can be interpreted as a ranking model optimized on a lower bound of the concordance index. This relation between ranking models and Cox's partial likelihood considers only pairwise comparisons. Recent work has developed differentiable sorting methods which relax this pairwise independence assumption, enabling the ranking of sets of samples. However, current differentiable sorting methods cannot account for censoring, a key factor in many real-world datasets. To address this limitation, we propose a novel method called Diffsurv. We extend differentiable sorting methods to handle censored tasks by predicting matrices of possible permutations that take into account the label uncertainty introduced by censored samples. We contrast this approach with methods derived from partial likelihood and ranking losses. Our experiments show that Diffsurv outperforms established baselines in various simulated and real-world risk prediction scenarios. Additionally, we demonstrate the benefits of the algorithmic supervision enabled by Diffsurv by presenting a novel method for top-k risk prediction that outperforms current methods.