 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTranslateGemma Technical Report
Jan 15, 2026We present TranslateGemma, a suite of open machine translation models based on the Gemma 3 foundation models. To enhance the inherent multilingual capabilities of Gemma 3 for the translation task, we employ a two-stage fine-tuning process. First, supervised fine-tuning is performed using a rich mixture of high-quality large-scale synthetic parallel data generated via state-of-the-art models and human-translated parallel data. This is followed by a reinforcement learning phase, where we optimize translation quality using an ensemble of reward models, including MetricX-QE and AutoMQM, targeting translation quality. We demonstrate the effectiveness of TranslateGemma with human evaluation on the WMT25 test set across 10 language pairs and with automatic evaluation on the WMT24++ benchmark across 55 language pairs. Automatic metrics show consistent and substantial gains over the baseline Gemma 3 models across all sizes. Notably, smaller TranslateGemma models often achieve performance comparable to larger baseline models, offering improved efficiency. We also show that TranslateGemma models retain strong multimodal capabilities, with enhanced performance on the Vistra image translation benchmark. The release of the open TranslateGemma models aims to provide the research community with powerful and adaptable tools for machine translation.
Deconstructing Self-Bias in LLM-generated Translation Benchmarks
Sep 30, 2025As large language models (LLMs) begin to saturate existing benchmarks, automated benchmark creation using LLMs (LLM as a benchmark) has emerged as a scalable alternative to slow and costly human curation. While these generated test sets have to potential to cheaply rank models, we demonstrate a critical flaw. LLM generated benchmarks systematically favor the model that created the benchmark, they exhibit self bias on low resource languages to English translation tasks. We show three key findings on automatic benchmarking of LLMs for translation: First, this bias originates from two sources: the generated test data (LLM as a testset) and the evaluation method (LLM as an evaluator), with their combination amplifying the effect. Second, self bias in LLM as a benchmark is heavily influenced by the model's generation capabilities in the source language. For instance, we observe more pronounced bias in into English translation, where the model's generation system is developed, than in out of English translation tasks. Third, we observe that low diversity in source text is one attribution to self bias. Our results suggest that improving the diversity of these generated source texts can mitigate some of the observed self bias.
Searching for Difficult-to-Translate Test Examples at Scale
Sep 30, 2025NLP models require test data that are sufficiently challenging. The difficulty of an example is linked to the topic it originates from (''seed topic''). The relationship between the topic and the difficulty of its instances is stochastic in nature: an example about a difficult topic can happen to be easy, and vice versa. At the scale of the Internet, there are tens of thousands of potential topics, and finding the most difficult one by drawing and evaluating a large number of examples across all topics is computationally infeasible. We formalize this task and treat it as a multi-armed bandit problem. In this framework, each topic is an ''arm,'' and pulling an arm (at a cost) involves drawing a single example, evaluating it, and measuring its difficulty. The goal is to efficiently identify the most difficult topics within a fixed computational budget. We illustrate the bandit problem setup of finding difficult examples for the task of machine translation. We find that various bandit strategies vastly outperform baseline methods like brute-force searching the most challenging topics.
Generating Difficult-to-Translate Texts
Sep 30, 2025Machine translation benchmarks sourced from the real world are quickly obsoleted, due to most examples being easy for state-of-the-art translation models. This limits the benchmark's ability to distinguish which model is better or to reveal models' weaknesses. Current methods for creating difficult test cases, such as subsampling or from-scratch synthesis, either fall short of identifying difficult examples or suffer from a lack of diversity and naturalness. Inspired by the iterative process of human experts probing for model failures, we propose MT-breaker, a method where a large language model iteratively refines a source text to increase its translation difficulty. The LLM iteratively queries a target machine translation model to guide its generation of difficult examples. Our approach generates examples that are more challenging for the target MT model while preserving the diversity of natural texts. While the examples are tailored to a particular machine translation model during the generation, the difficulty also transfers to other models and languages.
CA*: Addressing Evaluation Pitfalls in Computation-Aware Latency for Simultaneous Speech Translation
Oct 21, 2024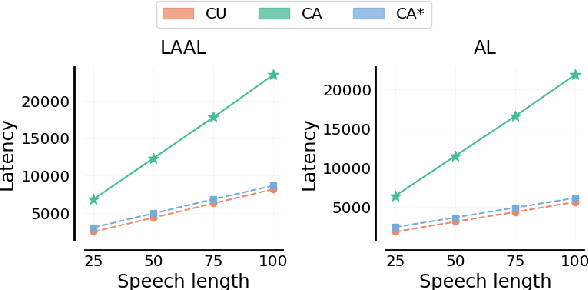

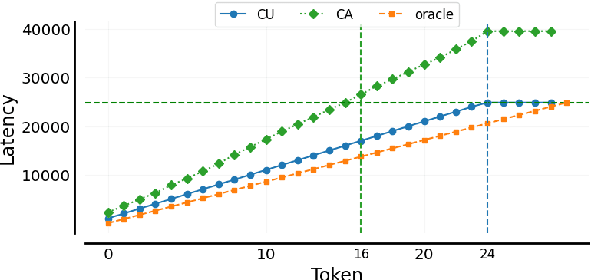
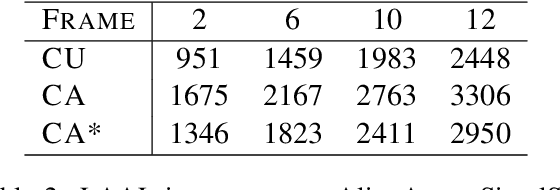
Simultaneous speech translation (SimulST) systems must balance translation quality with response time, making latency measurement crucial for evaluating their real-world performance. However, there has been a longstanding belief that current metrics yield unrealistically high latency measurements in unsegmented streaming settings. In this paper, we investigate this phenomenon, revealing its root cause in a fundamental misconception underlying existing latency evaluation approaches. We demonstrate that this issue affects not only streaming but also segment-level latency evaluation across different metrics. Furthermore, we propose a modification to correctly measure computation-aware latency for SimulST systems, addressing the limitations present in existing metrics.
Speculative Knowledge Distillation: Bridging the Teacher-Student Gap Through Interleaved Sampling
Oct 15, 2024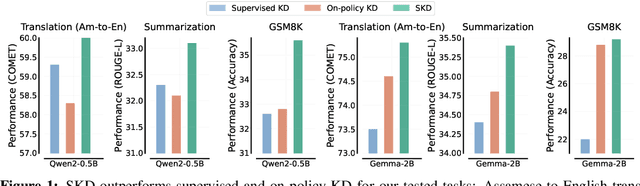
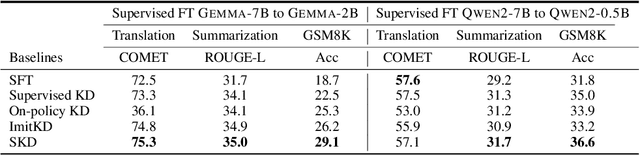

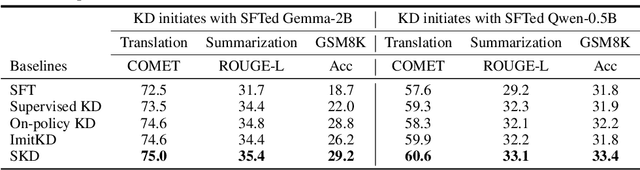
Recent advances in knowledge distillation (KD) have enabled smaller student models to approach the performance of larger teacher models. However, popular methods such as supervised KD and on-policy KD, are adversely impacted by the knowledge gaps between teacher-student in practical scenarios. Supervised KD suffers from a distribution mismatch between training with a static dataset and inference over final student-generated outputs. Conversely, on-policy KD, which uses student-generated samples for training, can suffer from low-quality training examples with which teacher models are not familiar, resulting in inaccurate teacher feedback. To address these limitations, we introduce Speculative Knowledge Distillation (SKD), a novel approach that leverages cooperation between student and teacher models to generate high-quality training data on-the-fly while aligning with the student's inference-time distribution. In SKD, the student proposes tokens, and the teacher replaces poorly ranked ones based on its own distribution, transferring high-quality knowledge adaptively. We evaluate SKD on various text generation tasks, including translation, summarization, math, and instruction following, and show that SKD consistently outperforms existing KD methods across different domains, data sizes, and model initialization strategies.
Uncovering Factor Level Preferences to Improve Human-Model Alignment
Oct 09, 2024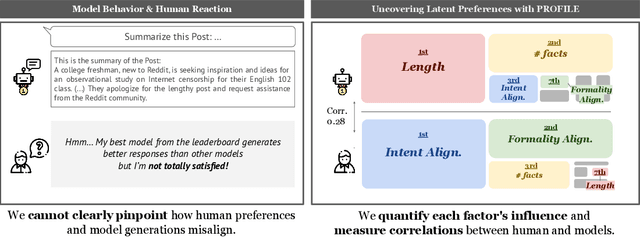

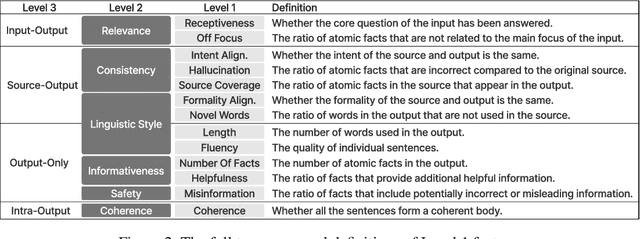

Despite advancements in Large Language Model (LLM) alignment, understanding the reasons behind LLM preferences remains crucial for bridging the gap between desired and actual behavior. LLMs often exhibit biases or tendencies that diverge from human preferences, such as favoring certain writing styles or producing overly verbose outputs. However, current methods for evaluating preference alignment often lack explainability, relying on coarse-grained comparisons. To address this, we introduce PROFILE (PRObing Factors of InfLuence for Explainability), a novel framework that uncovers and quantifies the influence of specific factors driving preferences. PROFILE's factor level analysis explains the 'why' behind human-model alignment and misalignment, offering insights into the direction of model improvement. We apply PROFILE to analyze human and LLM preferences across three tasks: summarization, helpful response generation, and document-based question-answering. Our factor level analysis reveals a substantial discrepancy between human and LLM preferences in generation tasks, whereas LLMs show strong alignment with human preferences in evaluation tasks. We demonstrate how leveraging factor level insights, including addressing misaligned factors or exploiting the generation-evaluation gap, can improve alignment with human preferences. This work underscores the importance of explainable preference analysis and highlights PROFILE's potential to provide valuable training signals, driving further improvements in human-model alignment.
Translation Canvas: An Explainable Interface to Pinpoint and Analyze Translation Systems
Oct 07, 2024


With the rapid advancement of machine translation research, evaluation toolkits have become essential for benchmarking system progress. Tools like COMET and SacreBLEU offer single quality score assessments that are effective for pairwise system comparisons. However, these tools provide limited insights for fine-grained system-level comparisons and the analysis of instance-level defects. To address these limitations, we introduce Translation Canvas, an explainable interface designed to pinpoint and analyze translation systems' performance: 1) Translation Canvas assists machine translation researchers in comprehending system-level model performance by identifying common errors (their frequency and severity) and analyzing relationships between different systems based on various evaluation metrics. 2) It supports fine-grained analysis by highlighting error spans with explanations and selectively displaying systems' predictions. According to human evaluation, Translation Canvas demonstrates superior performance over COMET and SacreBLEU packages under enjoyability and understandability criteria.
Design and Control of a Low-cost Non-backdrivable End-effector Upper Limb Rehabilitation Device
Jun 20, 2024This paper presents the development of an upper limb end-effector based rehabilitation device for stroke patients, offering assistance or resistance along any 2-dimensional trajectory during physical therapy. It employs a non-backdrivable ball-screw-driven mechanism for enhanced control accuracy. The control system features three novel algorithms: First, the Implicit Euler velocity control algorithm (IEVC) highlighted for its state-of-the-art accuracy, stability, efficiency and generalizability in motion restriction control. Second, an Admittance Virtual Dynamics simulation algorithm that achieves a smooth and natural human interaction with the non-backdrivable end-effector. Third, a generalized impedance force calculation algorithm allowing efficient impedance control on any trajectory or area boundary. Experimental validation demonstrated the system's effectiveness in accurate end-effector position control across various trajectories and configurations. The proposed upper limb end-effector-based rehabilitation device, with its high performance and adaptability, holds significant promise for extensive clinical application, potentially improving rehabilitation outcomes for stroke patients.
BPO: Supercharging Online Preference Learning by Adhering to the Proximity of Behavior LLM
Jun 18, 2024



Direct alignment from preferences (DAP) has emerged as a promising paradigm for aligning large language models (LLMs) to human desiderata from pre-collected, offline preference datasets. While recent studies indicate that existing offline DAP methods can directly benefit from online training samples, we highlight the need to develop specific online DAP algorithms to fully harness the power of online training. Specifically, we identify that the learned LLM should adhere to the proximity of the behavior LLM, which collects the training samples. To this end, we propose online Preference Optimization in proximity to the Behavior LLM (BPO), emphasizing the importance of constructing a proper trust region for LLM alignment. We conduct extensive experiments to validate the effectiveness and applicability of our approach by integrating it with various DAP methods, resulting in significant performance improvements across a wide range of tasks when training with the same amount of preference data. Even when only introducing one additional data collection phase, our online BPO improves its offline DAP baseline from 72.0% to 80.2% on TL;DR and from 82.2% to 89.1% on Anthropic Helpfulness in terms of win rate against human reference text.