 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGroup-Evolving Agents: Open-Ended Self-Improvement via Experience Sharing
Feb 04, 2026Open-ended self-improving agents can autonomously modify their own structural designs to advance their capabilities and overcome the limits of pre-defined architectures, thus reducing reliance on human intervention. We introduce Group-Evolving Agents (GEA), a new paradigm for open-ended self-improvements, which treats a group of agents as the fundamental evolutionary unit, enabling explicit experience sharing and reuse within the group throughout evolution. Unlike existing open-ended self-evolving paradigms that adopt tree-structured evolution, GEA overcomes the limitation of inefficient utilization of exploratory diversity caused by isolated evolutionary branches. We evaluate GEA on challenging coding benchmarks, where it significantly outperforms state-of-the-art self-evolving methods (71.0% vs. 56.7% on SWE-bench Verified, 88.3% vs. 68.3% on Polyglot) and matches or exceeds top human-designed agent frameworks (71.8% and 52.0% on two benchmarks, respectively). Analysis reveals that GEA more effectively converts early-stage exploratory diversity into sustained, long-term progress, achieving stronger performance under the same number of evolved agents. Furthermore, GEA exhibits consistent transferability across different coding models and greater robustness, fixing framework-level bugs in 1.4 iterations on average, versus 5 for self-evolving methods.
MLGym: A New Framework and Benchmark for Advancing AI Research Agents
Feb 20, 2025



We introduce Meta MLGym and MLGym-Bench, a new framework and benchmark for evaluating and developing LLM agents on AI research tasks. This is the first Gym environment for machine learning (ML) tasks, enabling research on reinforcement learning (RL) algorithms for training such agents. MLGym-bench consists of 13 diverse and open-ended AI research tasks from diverse domains such as computer vision, natural language processing, reinforcement learning, and game theory. Solving these tasks requires real-world AI research skills such as generating new ideas and hypotheses, creating and processing data, implementing ML methods, training models, running experiments, analyzing the results, and iterating through this process to improve on a given task. We evaluate a number of frontier large language models (LLMs) on our benchmarks such as Claude-3.5-Sonnet, Llama-3.1 405B, GPT-4o, o1-preview, and Gemini-1.5 Pro. Our MLGym framework makes it easy to add new tasks, integrate and evaluate models or agents, generate synthetic data at scale, as well as develop new learning algorithms for training agents on AI research tasks. We find that current frontier models can improve on the given baselines, usually by finding better hyperparameters, but do not generate novel hypotheses, algorithms, architectures, or substantial improvements. We open-source our framework and benchmark to facilitate future research in advancing the AI research capabilities of LLM agents.
MAF: Multi-Aspect Feedback for Improving Reasoning in Large Language Models
Oct 19, 2023Language Models (LMs) have shown impressive performance in various natural language tasks. However, when it comes to natural language reasoning, LMs still face challenges such as hallucination, generating incorrect intermediate reasoning steps, and making mathematical errors. Recent research has focused on enhancing LMs through self-improvement using feedback. Nevertheless, existing approaches relying on a single generic feedback source fail to address the diverse error types found in LM-generated reasoning chains. In this work, we propose Multi-Aspect Feedback, an iterative refinement framework that integrates multiple feedback modules, including frozen LMs and external tools, each focusing on a specific error category. Our experimental results demonstrate the efficacy of our approach to addressing several errors in the LM-generated reasoning chain and thus improving the overall performance of an LM in several reasoning tasks. We see a relative improvement of up to 20% in Mathematical Reasoning and up to 18% in Logical Entailment.
Automatically Correcting Large Language Models: Surveying the landscape of diverse self-correction strategies
Aug 06, 2023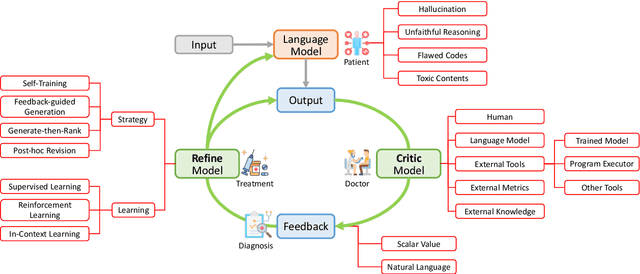
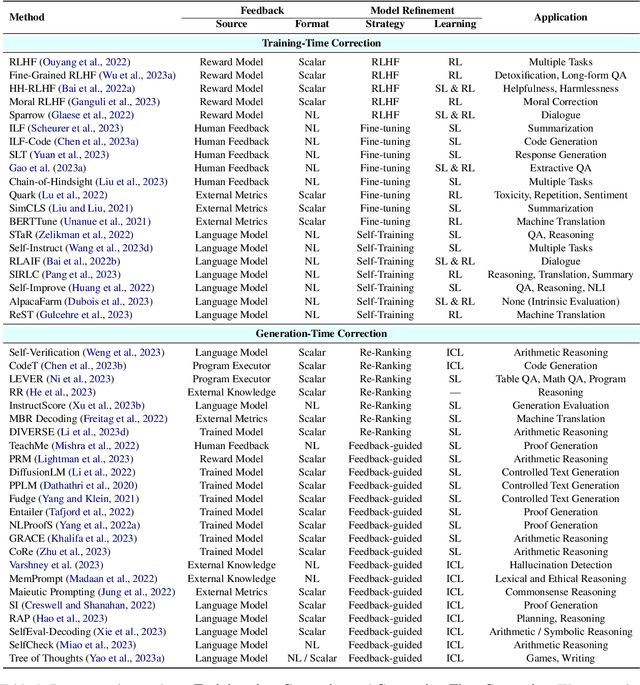
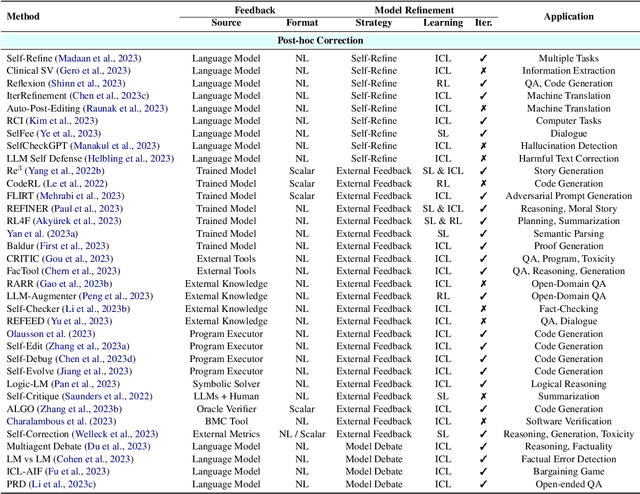
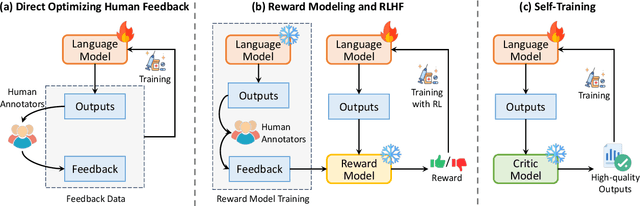
Large language models (LLMs) have demonstrated remarkable performance across a wide array of NLP tasks. However, their efficacy is undermined by undesired and inconsistent behaviors, including hallucination, unfaithful reasoning, and toxic content. A promising approach to rectify these flaws is self-correction, where the LLM itself is prompted or guided to fix problems in its own output. Techniques leveraging automated feedback -- either produced by the LLM itself or some external system -- are of particular interest as they are a promising way to make LLM-based solutions more practical and deployable with minimal human feedback. This paper presents a comprehensive review of this emerging class of techniques. We analyze and taxonomize a wide array of recent work utilizing these strategies, including training-time, generation-time, and post-hoc correction. We also summarize the major applications of this strategy and conclude by discussing future directions and challenges.
Few-shot Controllable Style Transfer for Low-Resource Settings: A Study in Indian Languages
Oct 14, 2021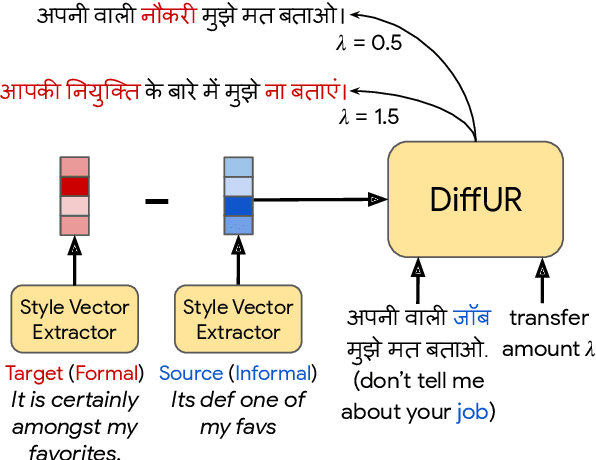
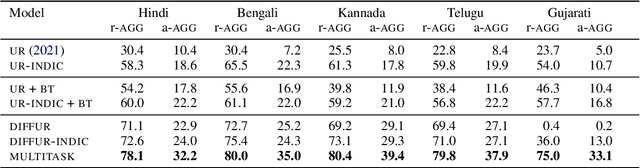
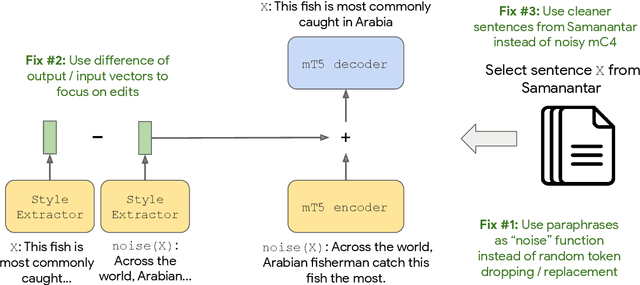
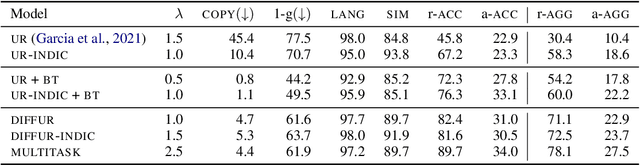
Style transfer is the task of rewriting an input sentence into a target style while approximately preserving its content. While most prior literature assumes access to large style-labelled corpora, recent work (Riley et al. 2021) has attempted "few-shot" style transfer using only 3-10 sentences at inference for extracting the target style. In this work we consider one such low resource setting where no datasets are available: style transfer for Indian languages. We find that existing few-shot methods perform this task poorly, with a strong tendency to copy inputs verbatim. We push the state-of-the-art for few-shot style transfer with a new method modeling the stylistic difference between paraphrases. When compared to prior work using automatic and human evaluations, our model achieves 2-3x better performance and output diversity in formality transfer and code-mixing addition across five Indian languages. Moreover, our method is better able to control the amount of style transfer using an input scalar knob. We report promising qualitative results for several attribute transfer directions, including sentiment transfer, text simplification, gender neutralization and text anonymization, all without retraining the model. Finally we found model evaluation to be difficult due to the lack of evaluation datasets and metrics for Indian languages. To facilitate further research in formality transfer for Indic languages, we crowdsource annotations for 4000 sentence pairs in four languages, and use this dataset to design our automatic evaluation suite.
Few-Shot Learning on Graphs via Super-Classes based on Graph Spectral Measures
Feb 27, 2020
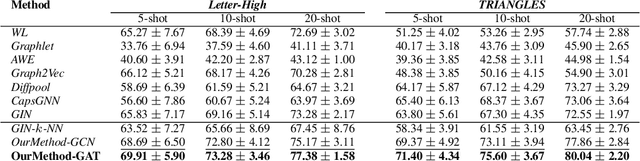
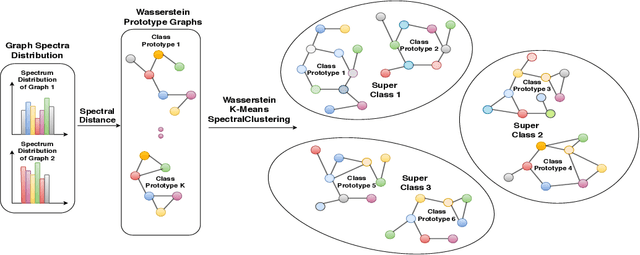
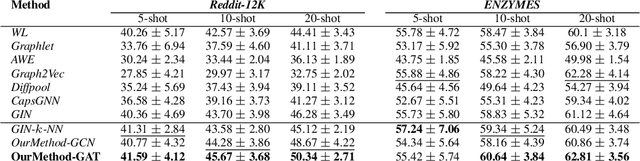
We propose to study the problem of few shot graph classification in graph neural networks (GNNs) to recognize unseen classes, given limited labeled graph examples. Despite several interesting GNN variants being proposed recently for node and graph classification tasks, when faced with scarce labeled examples in the few shot setting, these GNNs exhibit significant loss in classification performance. Here, we present an approach where a probability measure is assigned to each graph based on the spectrum of the graphs normalized Laplacian. This enables us to accordingly cluster the graph base labels associated with each graph into super classes, where the Lp Wasserstein distance serves as our underlying distance metric. Subsequently, a super graph constructed based on the super classes is then fed to our proposed GNN framework which exploits the latent inter class relationships made explicit by the super graph to achieve better class label separation among the graphs. We conduct exhaustive empirical evaluations of our proposed method and show that it outperforms both the adaptation of state of the art graph classification methods to few shot scenario and our naive baseline GNNs. Additionally, we also extend and study the behavior of our method to semi supervised and active learning scenarios.
Solving Partial Assignment Problems using Random Clique Complexes
Jul 03, 2019
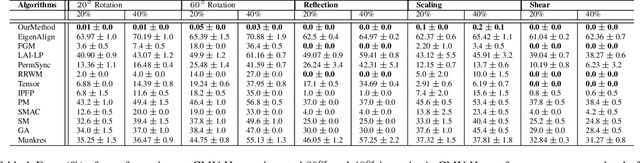

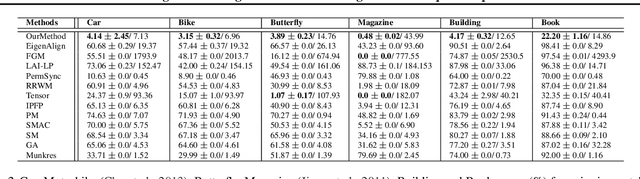
We present an alternate formulation of the partial assignment problem as matching random clique complexes, that are higher-order analogues of random graphs, designed to provide a set of invariants that better detect higher-order structure. The proposed method creates random clique adjacency matrices for each k-skeleton of the random clique complexes and matches them, taking into account each point as the affine combination of its geometric neighbourhood. We justify our solution theoretically, by analyzing the runtime and storage complexity of our algorithm along with the asymptotic behaviour of the quadratic assignment problem (QAP) that is associated with the underlying random clique adjacency matrices. Experiments on both synthetic and real-world datasets, containing severe occlusions and distortions, provide insight into the accuracy, efficiency, and robustness of our approach. We outperform diverse matching algorithms by a significant margin.
Learning Attention-based Embeddings for Relation Prediction in Knowledge Graphs
Jun 04, 2019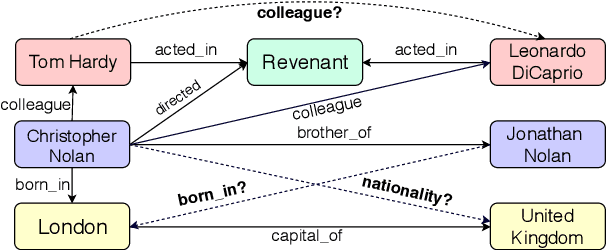
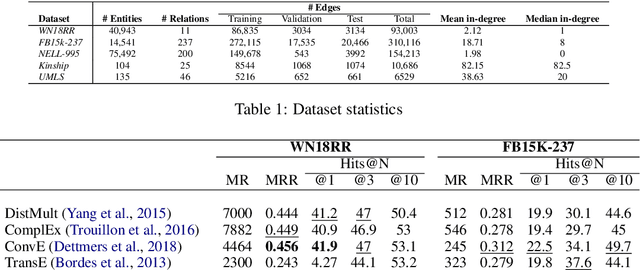


The recent proliferation of knowledge graphs (KGs) coupled with incomplete or partial information, in the form of missing relations (links) between entities, has fueled a lot of research on knowledge base completion (also known as relation prediction). Several recent works suggest that convolutional neural network (CNN) based models generate richer and more expressive feature embeddings and hence also perform well on relation prediction. However, we observe that these KG embeddings treat triples independently and thus fail to cover the complex and hidden information that is inherently implicit in the local neighborhood surrounding a triple. To this effect, our paper proposes a novel attention based feature embedding that captures both entity and relation features in any given entity's neighborhood. Additionally, we also encapsulate relation clusters and multihop relations in our model. Our empirical study offers insights into the efficacy of our attention based model and we show marked performance gains in comparison to state of the art methods on all datasets.