 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFew-shot Controllable Style Transfer for Low-Resource Settings: A Study in Indian Languages
Paper and Code
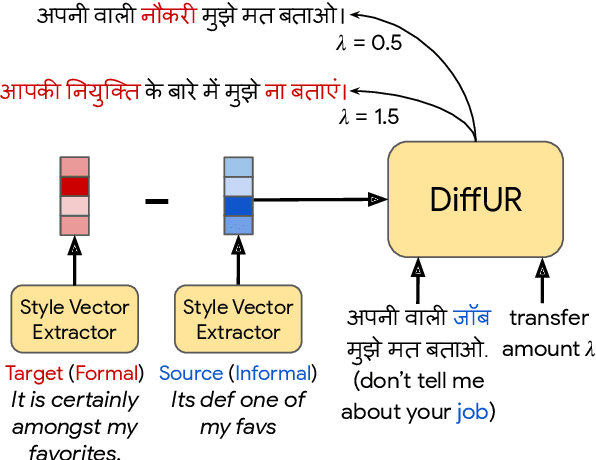
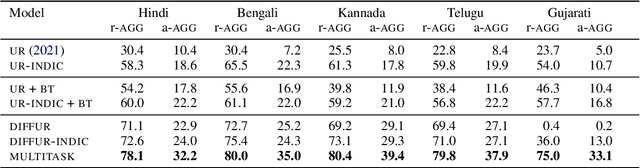
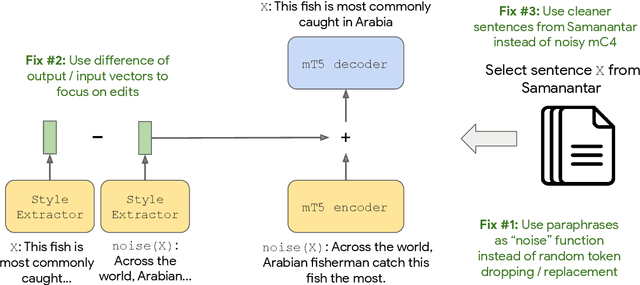
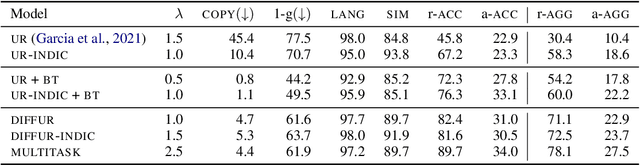
Style transfer is the task of rewriting an input sentence into a target style while approximately preserving its content. While most prior literature assumes access to large style-labelled corpora, recent work (Riley et al. 2021) has attempted "few-shot" style transfer using only 3-10 sentences at inference for extracting the target style. In this work we consider one such low resource setting where no datasets are available: style transfer for Indian languages. We find that existing few-shot methods perform this task poorly, with a strong tendency to copy inputs verbatim. We push the state-of-the-art for few-shot style transfer with a new method modeling the stylistic difference between paraphrases. When compared to prior work using automatic and human evaluations, our model achieves 2-3x better performance and output diversity in formality transfer and code-mixing addition across five Indian languages. Moreover, our method is better able to control the amount of style transfer using an input scalar knob. We report promising qualitative results for several attribute transfer directions, including sentiment transfer, text simplification, gender neutralization and text anonymization, all without retraining the model. Finally we found model evaluation to be difficult due to the lack of evaluation datasets and metrics for Indian languages. To facilitate further research in formality transfer for Indic languages, we crowdsource annotations for 4000 sentence pairs in four languages, and use this dataset to design our automatic evaluation suite.