 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning under Label Proportions for Text Classification
Oct 18, 2023



We present one of the preliminary NLP works under the challenging setup of Learning from Label Proportions (LLP), where the data is provided in an aggregate form called bags and only the proportion of samples in each class as the ground truth. This setup is inline with the desired characteristics of training models under Privacy settings and Weakly supervision. By characterizing some irregularities of the most widely used baseline technique DLLP, we propose a novel formulation that is also robust. This is accompanied with a learnability result that provides a generalization bound under LLP. Combining this formulation with a self-supervised objective, our method achieves better results as compared to the baselines in almost 87% of the experimental configurations which include large scale models for both long and short range texts across multiple metrics.
Improving Fairness-Accuracy tradeoff with few Test Samples under Covariate Shift
Oct 11, 2023Covariate shift in the test data can significantly downgrade both the accuracy and the fairness performance of the model. Ensuring fairness across different sensitive groups in such settings is of paramount importance due to societal implications like criminal justice. We operate under the unsupervised regime where only a small set of unlabeled test samples along with a labeled training set is available. Towards this problem, we make three contributions. First is a novel composite weighted entropy based objective for prediction accuracy which is optimized along with a representation matching loss for fairness. We experimentally verify that optimizing with our loss formulation outperforms a number of state-of-the-art baselines in the pareto sense with respect to the fairness-accuracy tradeoff on several standard datasets. Our second contribution is a new setting we term Asymmetric Covariate Shift that, to the best of our knowledge, has not been studied before. Asymmetric covariate shift occurs when distribution of covariates of one group shifts significantly compared to the other groups and this happens when a dominant group is over-represented. While this setting is extremely challenging for current baselines, We show that our proposed method significantly outperforms them. Our third contribution is theoretical, where we show that our weighted entropy term along with prediction loss on the training set approximates test loss under covariate shift. Empirically and through formal sample complexity bounds, we show that this approximation to the unseen test loss does not depend on importance sampling variance which affects many other baselines.
Learning Over Molecular Conformer Ensembles: Datasets and Benchmarks
Sep 29, 2023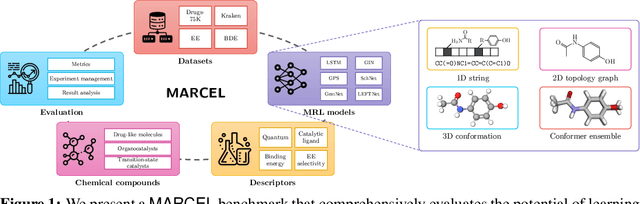
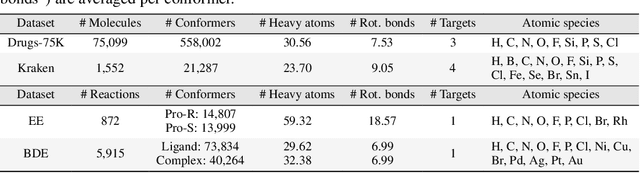

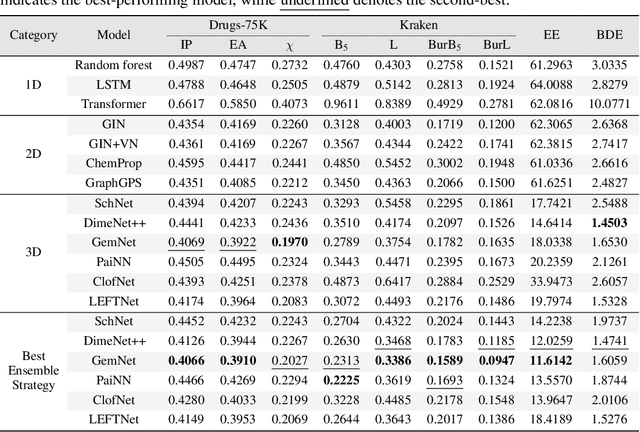
Molecular Representation Learning (MRL) has proven impactful in numerous biochemical applications such as drug discovery and enzyme design. While Graph Neural Networks (GNNs) are effective at learning molecular representations from a 2D molecular graph or a single 3D structure, existing works often overlook the flexible nature of molecules, which continuously interconvert across conformations via chemical bond rotations and minor vibrational perturbations. To better account for molecular flexibility, some recent works formulate MRL as an ensemble learning problem, focusing on explicitly learning from a set of conformer structures. However, most of these studies have limited datasets, tasks, and models. In this work, we introduce the first MoleculAR Conformer Ensemble Learning (MARCEL) benchmark to thoroughly evaluate the potential of learning on conformer ensembles and suggest promising research directions. MARCEL includes four datasets covering diverse molecule- and reaction-level properties of chemically diverse molecules including organocatalysts and transition-metal catalysts, extending beyond the scope of common GNN benchmarks that are confined to drug-like molecules. In addition, we conduct a comprehensive empirical study, which benchmarks representative 1D, 2D, and 3D molecular representation learning models, along with two strategies that explicitly incorporate conformer ensembles into 3D MRL models. Our findings reveal that direct learning from an accessible conformer space can improve performance on a variety of tasks and models.
Universality and Limitations of Prompt Tuning
May 30, 2023Despite the demonstrated empirical efficacy of prompt tuning to adapt a pretrained language model for a new task, the theoretical underpinnings of the difference between "tuning parameters before the input" against "the tuning of model weights" are limited. We thus take one of the first steps to understand the role of soft-prompt tuning for transformer-based architectures. By considering a general purpose architecture, we analyze prompt tuning from the lens of both: universal approximation and limitations with finite-depth fixed-weight pretrained transformers for continuous-valued functions. Our universality result guarantees the existence of a strong transformer with a prompt to approximate any sequence-to-sequence function in the set of Lipschitz functions. The limitations of prompt tuning for limited-depth transformers are first proved by constructing a set of datasets, that cannot be memorized by a prompt of any length for a given single encoder layer. We also provide a lower bound on the required number of tunable prompt parameters and compare the result with the number of parameters required for a low-rank update (based on LoRA) for a single-layer setting. We finally extend our analysis to multi-layer settings by providing sufficient conditions under which the transformer can at best learn datasets from invertible functions only. Our theoretical claims are also corroborated by empirical results.
Multi-Variate Time Series Forecasting on Variable Subsets
Jun 25, 2022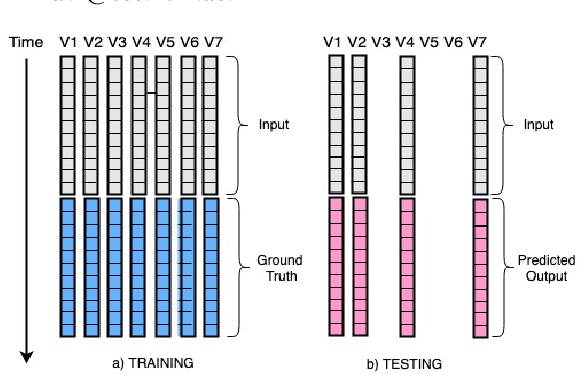
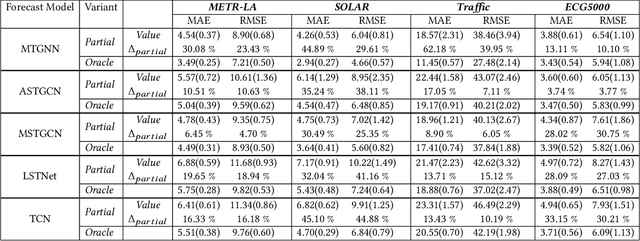
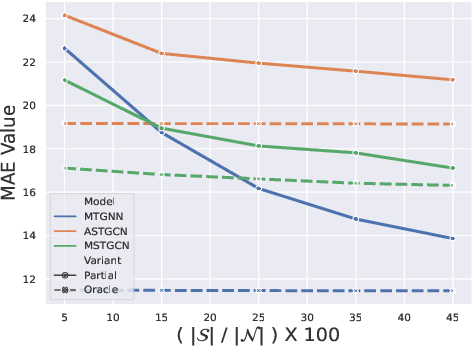

We formulate a new inference task in the domain of multivariate time series forecasting (MTSF), called Variable Subset Forecast (VSF), where only a small subset of the variables is available during inference. Variables are absent during inference because of long-term data loss (eg. sensor failures) or high -> low-resource domain shift between train / test. To the best of our knowledge, robustness of MTSF models in presence of such failures, has not been studied in the literature. Through extensive evaluation, we first show that the performance of state of the art methods degrade significantly in the VSF setting. We propose a non-parametric, wrapper technique that can be applied on top any existing forecast models. Through systematic experiments across 4 datasets and 5 forecast models, we show that our technique is able to recover close to 95\% performance of the models even when only 15\% of the original variables are present.
BERTops: Studying BERT Representations under a Topological Lens
May 02, 2022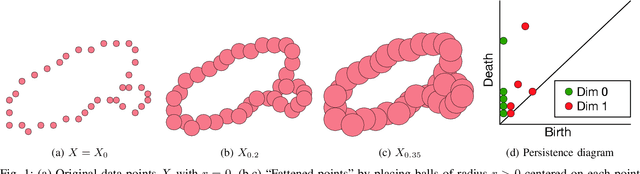
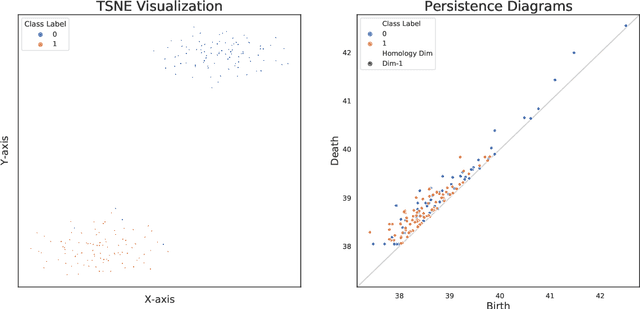
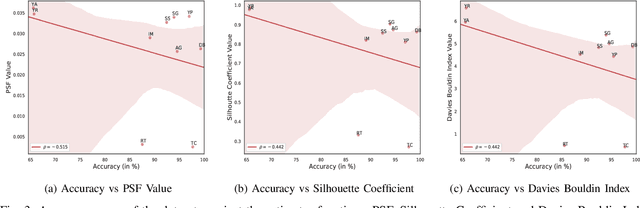
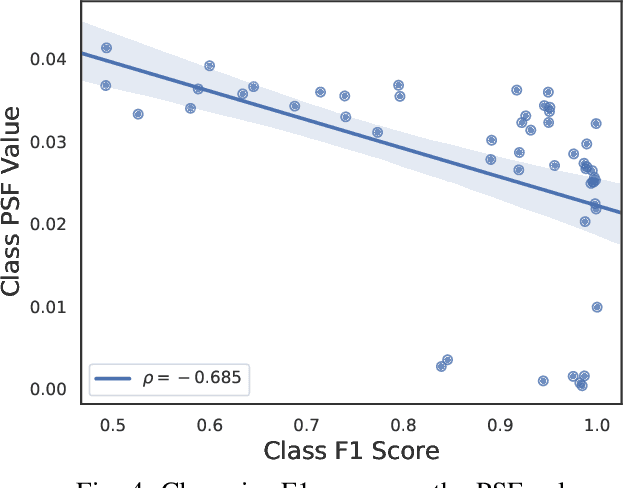
Proposing scoring functions to effectively understand, analyze and learn various properties of high dimensional hidden representations of large-scale transformer models like BERT can be a challenging task. In this work, we explore a new direction by studying the topological features of BERT hidden representations using persistent homology (PH). We propose a novel scoring function named "persistence scoring function (PSF)" which: (i) accurately captures the homology of the high-dimensional hidden representations and correlates well with the test set accuracy of a wide range of datasets and outperforms existing scoring metrics, (ii) captures interesting post fine-tuning "per-class" level properties from both qualitative and quantitative viewpoints, (iii) is more stable to perturbations as compared to the baseline functions, which makes it a very robust proxy, and (iv) finally, also serves as a predictor of the attack success rates for a wide category of black-box and white-box adversarial attack methods. Our extensive correlation experiments demonstrate the practical utility of PSF on various NLP tasks relevant to BERT.
A Probabilistic Framework for Knowledge Graph Data Augmentation
Oct 25, 2021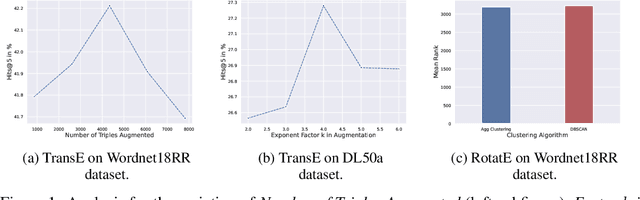



We present NNMFAug, a probabilistic framework to perform data augmentation for the task of knowledge graph completion to counter the problem of data scarcity, which can enhance the learning process of neural link predictors. Our method can generate potentially diverse triples with the advantage of being efficient and scalable as well as agnostic to the choice of the link prediction model and dataset used. Experiments and analysis done on popular models and benchmarks show that NNMFAug can bring notable improvements over the baselines.
Target Model Agnostic Adversarial Attacks with Query Budgets on Language Understanding Models
Jun 13, 2021
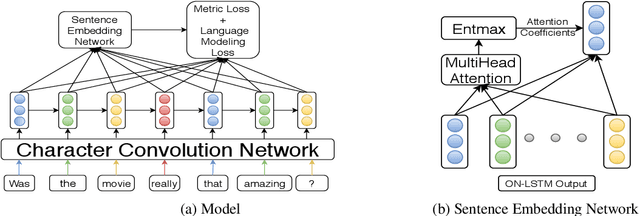
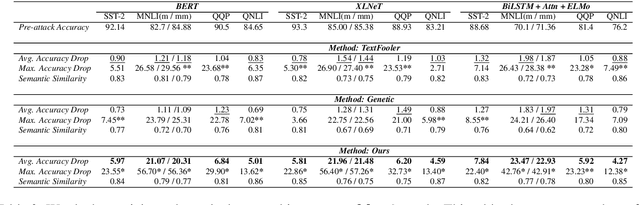
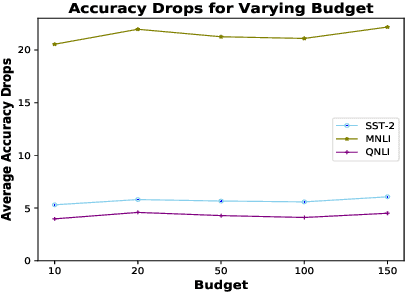
Despite significant improvements in natural language understanding models with the advent of models like BERT and XLNet, these neural-network based classifiers are vulnerable to blackbox adversarial attacks, where the attacker is only allowed to query the target model outputs. We add two more realistic restrictions on the attack methods, namely limiting the number of queries allowed (query budget) and crafting attacks that easily transfer across different pre-trained models (transferability), which render previous attack models impractical and ineffective. Here, we propose a target model agnostic adversarial attack method with a high degree of attack transferability across the attacked models. Our empirical studies show that in comparison to baseline methods, our method generates highly transferable adversarial sentences under the restriction of limited query budgets.
Learning Representations using Spectral-Biased Random Walks on Graphs
May 19, 2020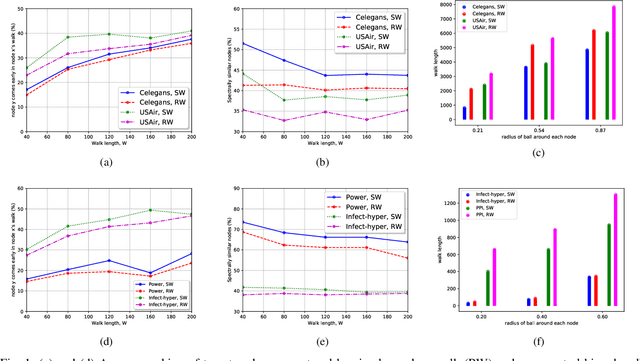

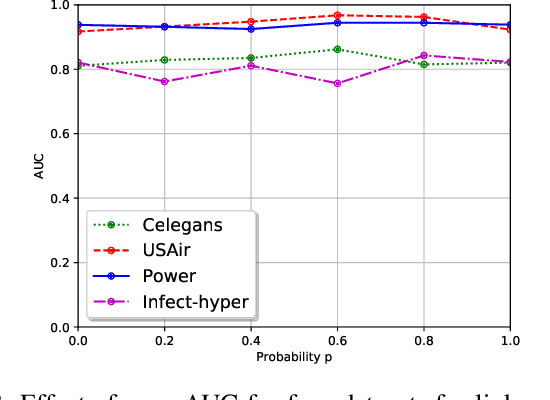

Several state-of-the-art neural graph embedding methods are based on short random walks (stochastic processes) because of their ease of computation, simplicity in capturing complex local graph properties, scalability, and interpretibility. In this work, we are interested in studying how much a probabilistic bias in this stochastic process affects the quality of the nodes picked by the process. In particular, our biased walk, with a certain probability, favors movement towards nodes whose neighborhoods bear a structural resemblance to the current node's neighborhood. We succinctly capture this neighborhood as a probability measure based on the spectrum of the node's neighborhood subgraph represented as a normalized laplacian matrix. We propose the use of a paragraph vector model with a novel Wasserstein regularization term. We empirically evaluate our approach against several state-of-the-art node embedding techniques on a wide variety of real-world datasets and demonstrate that our proposed method significantly improves upon existing methods on both link prediction and node classification tasks.
Few-Shot Learning on Graphs via Super-Classes based on Graph Spectral Measures
Feb 27, 2020
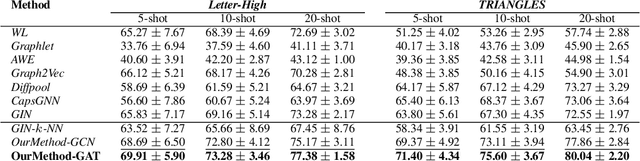
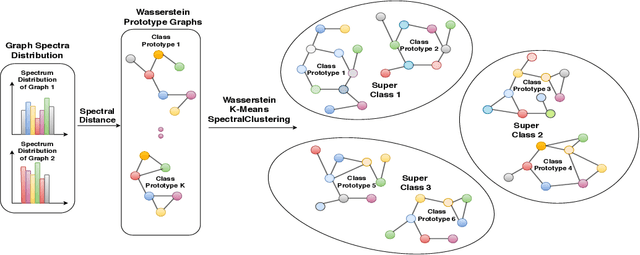
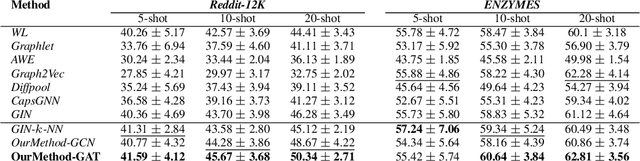
We propose to study the problem of few shot graph classification in graph neural networks (GNNs) to recognize unseen classes, given limited labeled graph examples. Despite several interesting GNN variants being proposed recently for node and graph classification tasks, when faced with scarce labeled examples in the few shot setting, these GNNs exhibit significant loss in classification performance. Here, we present an approach where a probability measure is assigned to each graph based on the spectrum of the graphs normalized Laplacian. This enables us to accordingly cluster the graph base labels associated with each graph into super classes, where the Lp Wasserstein distance serves as our underlying distance metric. Subsequently, a super graph constructed based on the super classes is then fed to our proposed GNN framework which exploits the latent inter class relationships made explicit by the super graph to achieve better class label separation among the graphs. We conduct exhaustive empirical evaluations of our proposed method and show that it outperforms both the adaptation of state of the art graph classification methods to few shot scenario and our naive baseline GNNs. Additionally, we also extend and study the behavior of our method to semi supervised and active learning scenarios.