 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePLGC: Pseudo-Labeled Graph Condensation
Jan 15, 2026Large graph datasets make training graph neural networks (GNNs) computationally costly. Graph condensation methods address this by generating small synthetic graphs that approximate the original data. However, existing approaches rely on clean, supervised labels, which limits their reliability when labels are scarce, noisy, or inconsistent. We propose Pseudo-Labeled Graph Condensation (PLGC), a self-supervised framework that constructs latent pseudo-labels from node embeddings and optimizes condensed graphs to match the original graph's structural and feature statistics -- without requiring ground-truth labels. PLGC offers three key contributions: (1) A diagnosis of why supervised condensation fails under label noise and distribution shift. (2) A label-free condensation method that jointly learns latent prototypes and node assignments. (3) Theoretical guarantees showing that pseudo-labels preserve latent structural statistics of the original graph and ensure accurate embedding alignment. Empirically, across node classification and link prediction tasks, PLGC achieves competitive performance with state-of-the-art supervised condensation methods on clean datasets and exhibits substantial robustness under label noise, often outperforming all baselines by a significant margin. Our findings highlight the practical and theoretical advantages of self-supervised graph condensation in noisy or weakly-labeled environments.
Improving Fairness-Accuracy tradeoff with few Test Samples under Covariate Shift
Oct 11, 2023Covariate shift in the test data can significantly downgrade both the accuracy and the fairness performance of the model. Ensuring fairness across different sensitive groups in such settings is of paramount importance due to societal implications like criminal justice. We operate under the unsupervised regime where only a small set of unlabeled test samples along with a labeled training set is available. Towards this problem, we make three contributions. First is a novel composite weighted entropy based objective for prediction accuracy which is optimized along with a representation matching loss for fairness. We experimentally verify that optimizing with our loss formulation outperforms a number of state-of-the-art baselines in the pareto sense with respect to the fairness-accuracy tradeoff on several standard datasets. Our second contribution is a new setting we term Asymmetric Covariate Shift that, to the best of our knowledge, has not been studied before. Asymmetric covariate shift occurs when distribution of covariates of one group shifts significantly compared to the other groups and this happens when a dominant group is over-represented. While this setting is extremely challenging for current baselines, We show that our proposed method significantly outperforms them. Our third contribution is theoretical, where we show that our weighted entropy term along with prediction loss on the training set approximates test loss under covariate shift. Empirically and through formal sample complexity bounds, we show that this approximation to the unseen test loss does not depend on importance sampling variance which affects many other baselines.
Multi-Variate Time Series Forecasting on Variable Subsets
Jun 25, 2022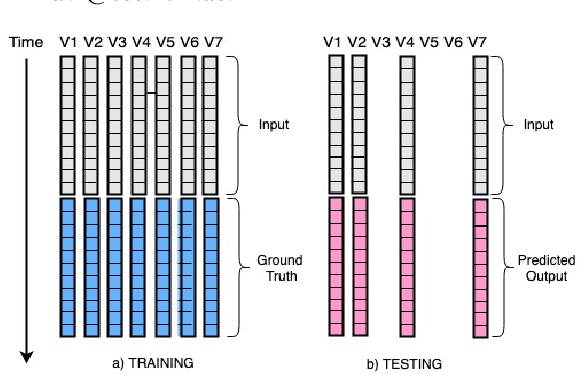
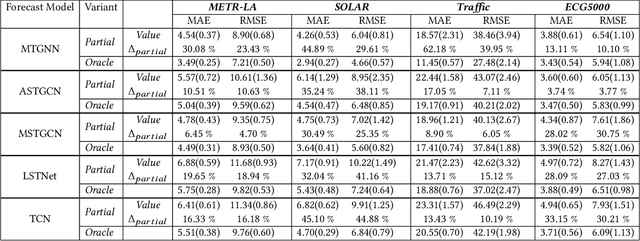
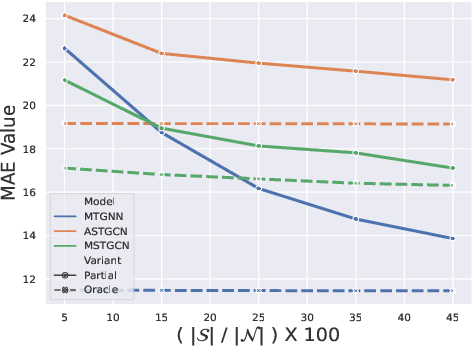

We formulate a new inference task in the domain of multivariate time series forecasting (MTSF), called Variable Subset Forecast (VSF), where only a small subset of the variables is available during inference. Variables are absent during inference because of long-term data loss (eg. sensor failures) or high -> low-resource domain shift between train / test. To the best of our knowledge, robustness of MTSF models in presence of such failures, has not been studied in the literature. Through extensive evaluation, we first show that the performance of state of the art methods degrade significantly in the VSF setting. We propose a non-parametric, wrapper technique that can be applied on top any existing forecast models. Through systematic experiments across 4 datasets and 5 forecast models, we show that our technique is able to recover close to 95\% performance of the models even when only 15\% of the original variables are present.
Distributional Shifts in Automated Diabetic Retinopathy Screening
Jul 25, 2021
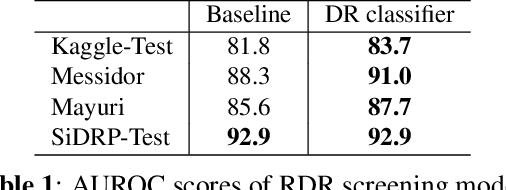

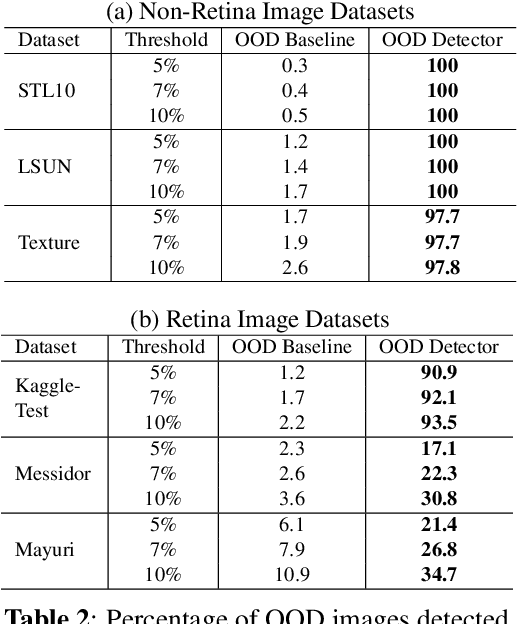
Deep learning-based models are developed to automatically detect if a retina image is `referable' in diabetic retinopathy (DR) screening. However, their classification accuracy degrades as the input images distributionally shift from their training distribution. Further, even if the input is not a retina image, a standard DR classifier produces a high confident prediction that the image is `referable'. Our paper presents a Dirichlet Prior Network-based framework to address this issue. It utilizes an out-of-distribution (OOD) detector model and a DR classification model to improve generalizability by identifying OOD images. Experiments on real-world datasets indicate that the proposed framework can eliminate the unknown non-retina images and identify the distributionally shifted retina images for human intervention.
Adversarially Robust Classifier with Covariate Shift Adaptation
Feb 09, 2021
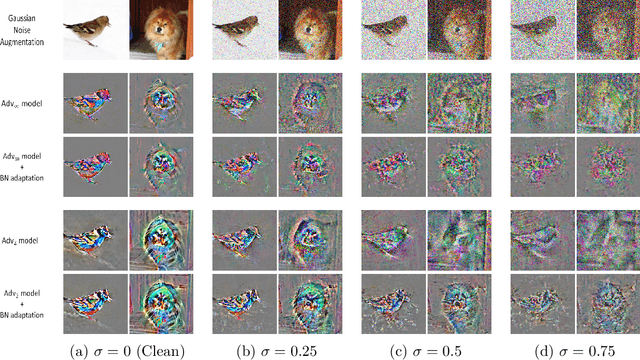
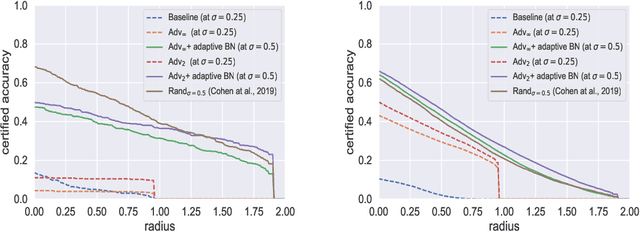
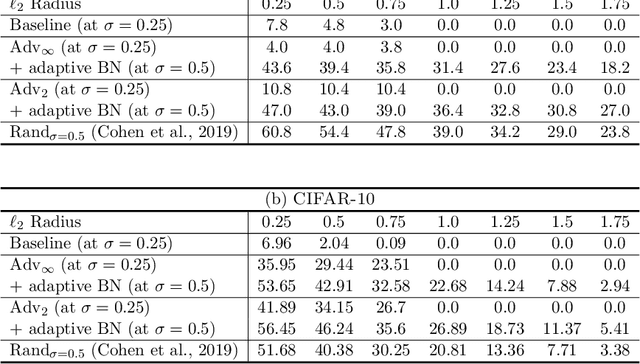
Existing adversarially trained models typically perform inference on test examples independently from each other. This mode of testing is unable to handle covariate shift in the test samples. Due to this, the performance of these models often degrades significantly. In this paper, we show that simple adaptive batch normalization (BN) technique that involves re-estimating the batch-normalization parameters during inference, can significantly improve the robustness of these models for any random perturbations, including the Gaussian noise. This simple finding enables us to transform adversarially trained models into randomized smoothing classifiers to produce certified robustness to $\ell_2$ noise. We show that we can achieve $\ell_2$ certified robustness even for adversarially trained models using $\ell_{\infty}$-bounded adversarial examples. We further demonstrate that adaptive BN technique significantly improves robustness against common corruptions, while often enhancing performance against adversarial attacks. This enables us to achieve both adversarial and corruption robustness for the same classifier.
Towards Maximizing the Representation Gap between In-Domain \& Out-of-Distribution Examples
Oct 20, 2020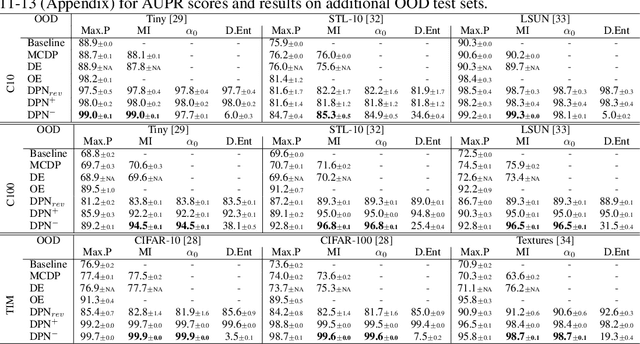



Among existing uncertainty estimation approaches, Dirichlet Prior Network (DPN) distinctly models different predictive uncertainty types. However, for in-domain examples with high data uncertainties among multiple classes, even a DPN model often produces indistinguishable representations from the out-of-distribution (OOD) examples, compromising their OOD detection performance. We address this shortcoming by proposing a novel loss function for DPN to maximize the \textit{representation gap} between in-domain and OOD examples. Experimental results demonstrate that our proposed approach consistently improves OOD detection performance.
Approximate Manifold Defense Against Multiple Adversarial Perturbations
Apr 05, 2020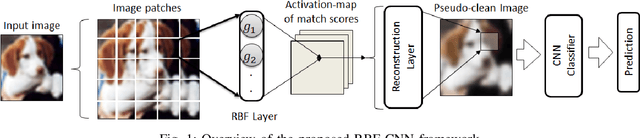



Existing defenses against adversarial attacks are typically tailored to a specific perturbation type. Using adversarial training to defend against multiple types of perturbation requires expensive adversarial examples from different perturbation types at each training step. In contrast, manifold-based defense incorporates a generative network to project an input sample onto the clean data manifold. This approach eliminates the need to generate expensive adversarial examples while achieving robustness against multiple perturbation types. However, the success of this approach relies on whether the generative network can capture the complete clean data manifold, which remains an open problem for complex input domain. In this work, we devise an approximate manifold defense mechanism, called RBF-CNN, for image classification. Instead of capturing the complete data manifold, we use an RBF layer to learn the density of small image patches. RBF-CNN also utilizes a reconstruction layer that mitigates any minor adversarial perturbations. Further, incorporating our proposed reconstruction process for training improves the adversarial robustness of our RBF-CNN models. Experiment results on MNIST and CIFAR-10 datasets indicate that RBF-CNN offers robustness for multiple perturbations without the need for expensive adversarial training.
Normal Similarity Network for Generative Modelling
May 14, 2018
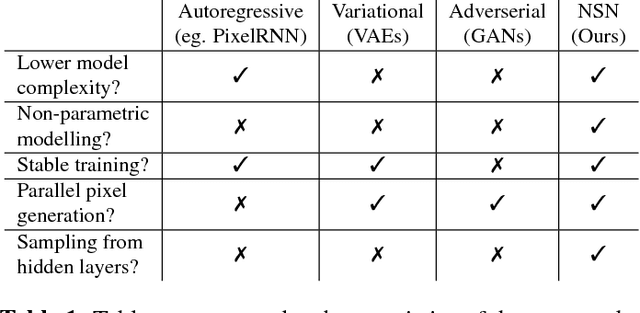
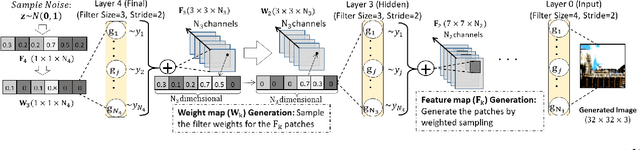
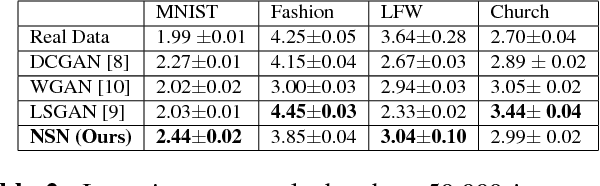
Gaussian distributions are commonly used as a key building block in many generative models. However, their applicability has not been well explored in deep networks. In this paper, we propose a novel deep generative model named as Normal Similarity Network (NSN) where the layers are constructed with Gaussian-style filters. NSN is trained with a layer-wise non-parametric density estimation algorithm that iteratively down-samples the training images and captures the density of the down-sampled training images in the final layer. Additionally, we propose NSN-Gen for generating new samples from noise vectors by iteratively reconstructing feature maps in the hidden layers of NSN. Our experiments suggest encouraging results of the proposed model for a wide range of computer vision applications including image generation, styling and reconstruction from occluded images.