 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQIME: Constructing Interpretable Medical Text Embeddings via Ontology-Grounded Questions
Mar 03, 2026While dense biomedical embeddings achieve strong performance, their black-box nature limits their utility in clinical decision-making. Recent question-based interpretable embeddings represent text as binary answers to natural-language questions, but these approaches often rely on heuristic or surface-level contrastive signals and overlook specialized domain knowledge. We propose QIME, an ontology-grounded framework for constructing interpretable medical text embeddings in which each dimension corresponds to a clinically meaningful yes/no question. By conditioning on cluster-specific medical concept signatures, QIME generates semantically atomic questions that capture fine-grained distinctions in biomedical text. Furthermore, QIME supports a training-free embedding construction strategy that eliminates per-question classifier training while further improving performance. Experiments across biomedical semantic similarity, clustering, and retrieval benchmarks show that QIME consistently outperforms prior interpretable embedding methods and substantially narrows the gap to strong black-box biomedical encoders, while providing concise and clinically informative explanations.
Multi-Part Object Representations via Graph Structures and Co-Part Discovery
Dec 20, 2025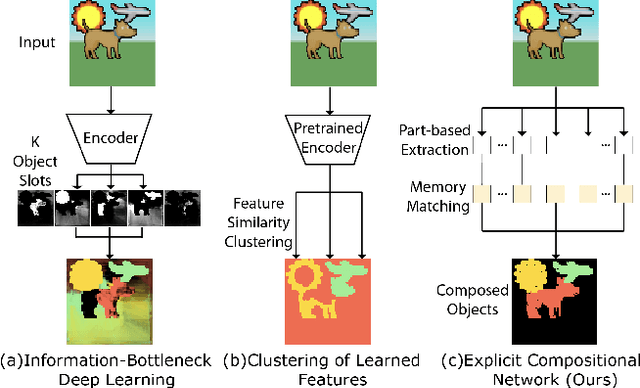
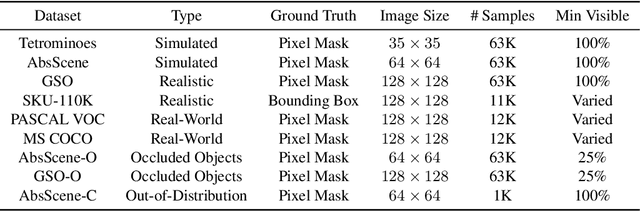
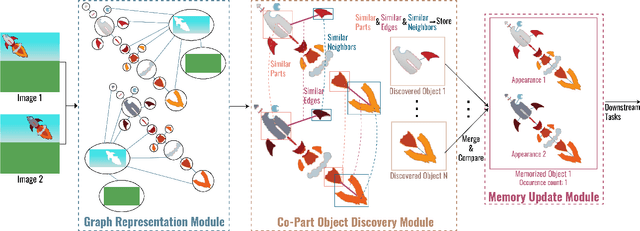
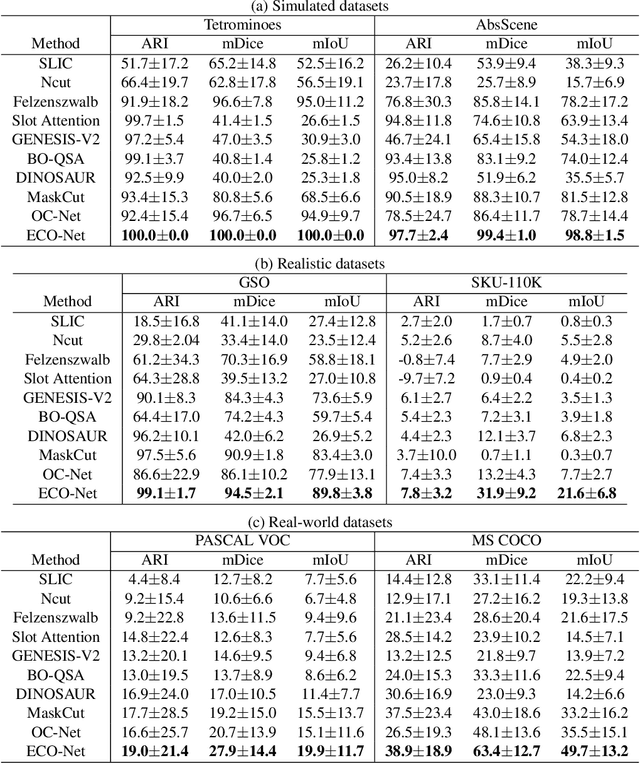
Discovering object-centric representations from images can significantly enhance the robustness, sample efficiency and generalizability of vision models. Works on images with multi-part objects typically follow an implicit object representation approach, which fail to recognize these learned objects in occluded or out-of-distribution contexts. This is due to the assumption that object part-whole relations are implicitly encoded into the representations through indirect training objectives. We address this limitation by proposing a novel method that leverages on explicit graph representations for parts and present a co-part object discovery algorithm. We then introduce three benchmarks to evaluate the robustness of object-centric methods in recognizing multi-part objects within occluded and out-of-distribution settings. Experimental results on simulated, realistic, and real-world images show marked improvements in the quality of discovered objects compared to state-of-the-art methods, as well as the accurate recognition of multi-part objects in occluded and out-of-distribution contexts. We also show that the discovered object-centric representations can more accurately predict key object properties in a downstream task, highlighting the potential of our method to advance the field of object-centric representations.
Multi-Modal Continual Learning via Cross-Modality Adapters and Representation Alignment with Knowledge Preservation
Nov 10, 2025Continual learning is essential for adapting models to new tasks while retaining previously acquired knowledge. While existing approaches predominantly focus on uni-modal data, multi-modal learning offers substantial benefits by utilizing diverse sensory inputs, akin to human perception. However, multi-modal continual learning presents additional challenges, as the model must effectively integrate new information from various modalities while preventing catastrophic forgetting. In this work, we propose a pre-trained model-based framework for multi-modal continual learning. Our framework includes a novel cross-modality adapter with a mixture-of-experts structure to facilitate effective integration of multi-modal information across tasks. We also introduce a representation alignment loss that fosters learning of robust multi-modal representations, and regularize relationships between learned representations to preserve knowledge from previous tasks. Experiments on several multi-modal datasets demonstrate that our approach consistently outperforms baselines in both class-incremental and domain-incremental learning, achieving higher accuracy and reduced forgetting.
* Accepted to ECAI 2025
TRUST-VL: An Explainable News Assistant for General Multimodal Misinformation Detection
Sep 04, 2025Multimodal misinformation, encompassing textual, visual, and cross-modal distortions, poses an increasing societal threat that is amplified by generative AI. Existing methods typically focus on a single type of distortion and struggle to generalize to unseen scenarios. In this work, we observe that different distortion types share common reasoning capabilities while also requiring task-specific skills. We hypothesize that joint training across distortion types facilitates knowledge sharing and enhances the model's ability to generalize. To this end, we introduce TRUST-VL, a unified and explainable vision-language model for general multimodal misinformation detection. TRUST-VL incorporates a novel Question-Aware Visual Amplifier module, designed to extract task-specific visual features. To support training, we also construct TRUST-Instruct, a large-scale instruction dataset containing 198K samples featuring structured reasoning chains aligned with human fact-checking workflows. Extensive experiments on both in-domain and zero-shot benchmarks demonstrate that TRUST-VL achieves state-of-the-art performance, while also offering strong generalization and interpretability.
From Personas to Talks: Revisiting the Impact of Personas on LLM-Synthesized Emotional Support Conversations
Feb 17, 2025



The rapid advancement of Large Language Models (LLMs) has revolutionized the generation of emotional support conversations (ESC), offering scalable solutions with reduced costs and enhanced data privacy. This paper explores the role of personas in the creation of ESC by LLMs. Our research utilizes established psychological frameworks to measure and infuse persona traits into LLMs, which then generate dialogues in the emotional support scenario. We conduct extensive evaluations to understand the stability of persona traits in dialogues, examining shifts in traits post-generation and their impact on dialogue quality and strategy distribution. Experimental results reveal several notable findings: 1) LLMs can infer core persona traits, 2) subtle shifts in emotionality and extraversion occur, influencing the dialogue dynamics, and 3) the application of persona traits modifies the distribution of emotional support strategies, enhancing the relevance and empathetic quality of the responses. These findings highlight the potential of persona-driven LLMs in crafting more personalized, empathetic, and effective emotional support dialogues, which has significant implications for the future design of AI-driven emotional support systems.
Mitigating GenAI-powered Evidence Pollution for Out-of-Context Multimodal Misinformation Detection
Jan 24, 2025While large generative artificial intelligence (GenAI) models have achieved significant success, they also raise growing concerns about online information security due to their potential misuse for generating deceptive content. Out-of-context (OOC) multimodal misinformation detection, which often retrieves Web evidence to identify the repurposing of images in false contexts, faces the issue of reasoning over GenAI-polluted evidence to derive accurate predictions. Existing works simulate GenAI-powered pollution at the claim level with stylistic rewriting to conceal linguistic cues, and ignore evidence-level pollution for such information-seeking applications. In this work, we investigate how polluted evidence affects the performance of existing OOC detectors, revealing a performance degradation of more than 9 percentage points. We propose two strategies, cross-modal evidence reranking and cross-modal claim-evidence reasoning, to address the challenges posed by polluted evidence. Extensive experiments on two benchmark datasets show that these strategies can effectively enhance the robustness of existing out-of-context detectors amidst polluted evidence.
ChronoFact: Timeline-based Temporal Fact Verification
Oct 19, 2024



Automated fact verification plays an essential role in fostering trust in the digital space. Despite the growing interest, the verification of temporal facts has not received much attention in the community. Temporal fact verification brings new challenges where cues of the temporal information need to be extracted and temporal reasoning involving various temporal aspects of the text must be applied. In this work, we propose an end-to-end solution for temporal fact verification that considers the temporal information in claims to obtain relevant evidence sentences and harness the power of large language model for temporal reasoning. Recognizing that temporal facts often involve events, we model these events in the claim and evidence sentences. We curate two temporal fact datasets to learn time-sensitive representations that encapsulate not only the semantic relationships among the events, but also their chronological proximity. This allows us to retrieve the top-k relevant evidence sentences and provide the context for a large language model to perform temporal reasoning and outputs whether a claim is supported or refuted by the retrieved evidence sentences. Experiment results demonstrate that the proposed approach significantly enhances the accuracy of temporal claim verification, thereby advancing current state-of-the-art in automated fact verification.
Evidence-Based Temporal Fact Verification
Jul 21, 2024Automated fact verification plays an essential role in fostering trust in the digital space. Despite the growing interest, the verification of temporal facts has not received much attention in the community. Temporal fact verification brings new challenges where cues of the temporal information need to be extracted and temporal reasoning involving various temporal aspects of the text must be applied. In this work, we propose an end-to-end solution for temporal fact verification that considers the temporal information in claims to obtain relevant evidence sentences and harness the power of large language model for temporal reasoning. Recognizing that temporal facts often involve events, we model these events in the claim and evidence sentences. We curate two temporal fact datasets to learn time-sensitive representations that encapsulate not only the semantic relationships among the events, but also their chronological proximity. This allows us to retrieve the top-k relevant evidence sentences and provide the context for a large language model to perform temporal reasoning and outputs whether a claim is supported or refuted by the retrieved evidence sentences. Experiment results demonstrate that the proposed approach significantly enhances the accuracy of temporal claim verification, thereby advancing current state-of-the-art in automated fact verification.
Cross-Domain Feature Augmentation for Domain Generalization
May 14, 2024



Domain generalization aims to develop models that are robust to distribution shifts. Existing methods focus on learning invariance across domains to enhance model robustness, and data augmentation has been widely used to learn invariant predictors, with most methods performing augmentation in the input space. However, augmentation in the input space has limited diversity whereas in the feature space is more versatile and has shown promising results. Nonetheless, feature semantics is seldom considered and existing feature augmentation methods suffer from a limited variety of augmented features. We decompose features into class-generic, class-specific, domain-generic, and domain-specific components. We propose a cross-domain feature augmentation method named XDomainMix that enables us to increase sample diversity while emphasizing the learning of invariant representations to achieve domain generalization. Experiments on widely used benchmark datasets demonstrate that our proposed method is able to achieve state-of-the-art performance. Quantitative analysis indicates that our feature augmentation approach facilitates the learning of effective models that are invariant across different domains.
SNIFFER: Multimodal Large Language Model for Explainable Out-of-Context Misinformation Detection
Mar 05, 2024Misinformation is a prevalent societal issue due to its potential high risks. Out-of-context (OOC) misinformation, where authentic images are repurposed with false text, is one of the easiest and most effective ways to mislead audiences. Current methods focus on assessing image-text consistency but lack convincing explanations for their judgments, which is essential for debunking misinformation. While Multimodal Large Language Models (MLLMs) have rich knowledge and innate capability for visual reasoning and explanation generation, they still lack sophistication in understanding and discovering the subtle crossmodal differences. In this paper, we introduce SNIFFER, a novel multimodal large language model specifically engineered for OOC misinformation detection and explanation. SNIFFER employs two-stage instruction tuning on InstructBLIP. The first stage refines the model's concept alignment of generic objects with news-domain entities and the second stage leverages language-only GPT-4 generated OOC-specific instruction data to fine-tune the model's discriminatory powers. Enhanced by external tools and retrieval, SNIFFER not only detects inconsistencies between text and image but also utilizes external knowledge for contextual verification. Our experiments show that SNIFFER surpasses the original MLLM by over 40% and outperforms state-of-the-art methods in detection accuracy. SNIFFER also provides accurate and persuasive explanations as validated by quantitative and human evaluations.