 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOLA: Output Language Alignment in Code-Switched LLM Interactions
Jan 07, 2026Code-switching, alternating between languages within a conversation, is natural for multilingual users, yet poses fundamental challenges for large language models (LLMs). When a user code-switches in their prompt to an LLM, they typically do not specify the expected language of the LLM response, and thus LLMs must infer the output language from contextual and pragmatic cues. We find that current LLMs systematically fail to align with this expectation, responding in undesired languages even when cues are clear to humans. We introduce OLA, a benchmark to evaluate LLMs' Output Language Alignment in code-switched interactions. OLA focuses on Korean--English code-switching and spans simple intra-sentential mixing to instruction-content mismatches. Even frontier models frequently misinterpret implicit language expectation, exhibiting a bias toward non-English responses. We further show this bias generalizes beyond Korean to Chinese and Indonesian pairs. Models also show instability through mid-response switching and language intrusions. Chain-of-Thought prompting fails to resolve these errors, indicating weak pragmatic reasoning about output language. However, Code-Switching Aware DPO with minimal data (about 1K examples) substantially reduces misalignment, suggesting these failures stem from insufficient alignment rather than fundamental limitations. Our results highlight the need to align multilingual LLMs with users' implicit expectations in real-world code-switched interactions.
Are they lovers or friends? Evaluating LLMs' Social Reasoning in English and Korean Dialogues
Oct 21, 2025As large language models (LLMs) are increasingly used in human-AI interactions, their social reasoning capabilities in interpersonal contexts are critical. We introduce SCRIPTS, a 1k-dialogue dataset in English and Korean, sourced from movie scripts. The task involves evaluating models' social reasoning capability to infer the interpersonal relationships (e.g., friends, sisters, lovers) between speakers in each dialogue. Each dialogue is annotated with probabilistic relational labels (Highly Likely, Less Likely, Unlikely) by native (or equivalent) Korean and English speakers from Korea and the U.S. Evaluating nine models on our task, current proprietary LLMs achieve around 75-80% on the English dataset, whereas their performance on Korean drops to 58-69%. More strikingly, models select Unlikely relationships in 10-25% of their responses. Furthermore, we find that thinking models and chain-of-thought prompting, effective for general reasoning, provide minimal benefits for social reasoning and occasionally amplify social biases. Our findings reveal significant limitations in current LLMs' social reasoning capabilities, highlighting the need for efforts to develop socially-aware language models.
Spotting Out-of-Character Behavior: Atomic-Level Evaluation of Persona Fidelity in Open-Ended Generation
Jun 24, 2025Ensuring persona fidelity in large language models (LLMs) is essential for maintaining coherent and engaging human-AI interactions. However, LLMs often exhibit Out-of-Character (OOC) behavior, where generated responses deviate from an assigned persona, leading to inconsistencies that affect model reliability. Existing evaluation methods typically assign single scores to entire responses, struggling to capture subtle persona misalignment, particularly in long-form text generation. To address this limitation, we propose an atomic-level evaluation framework that quantifies persona fidelity at a finer granularity. Our three key metrics measure the degree of persona alignment and consistency within and across generations. Our approach enables a more precise and realistic assessment of persona fidelity by identifying subtle deviations that real users would encounter. Through our experiments, we demonstrate that our framework effectively detects persona inconsistencies that prior methods overlook. By analyzing persona fidelity across diverse tasks and personality types, we reveal how task structure and persona desirability influence model adaptability, highlighting challenges in maintaining consistent persona expression.
Flex-TravelPlanner: A Benchmark for Flexible Planning with Language Agents
Jun 05, 2025Real-world planning problems require constant adaptation to changing requirements and balancing of competing constraints. However, current benchmarks for evaluating LLMs' planning capabilities primarily focus on static, single-turn scenarios. We introduce Flex-TravelPlanner, a benchmark that evaluates language models' ability to reason flexibly in dynamic planning scenarios. Building on the TravelPlanner dataset~\citep{xie2024travelplanner}, we introduce two novel evaluation settings: (1) sequential constraint introduction across multiple turns, and (2) scenarios with explicitly prioritized competing constraints. Our analysis of GPT-4o and Llama 3.1 70B reveals several key findings: models' performance on single-turn tasks poorly predicts their ability to adapt plans across multiple turns; constraint introduction order significantly affects performance; and models struggle with constraint prioritization, often incorrectly favoring newly introduced lower priority preferences over existing higher-priority constraints. These findings highlight the importance of evaluating LLMs in more realistic, dynamic planning scenarios and suggest specific directions for improving model performance on complex planning tasks. The code and dataset for our framework are publicly available at https://github.com/juhyunohh/FlexTravelBench.
Uncovering Factor Level Preferences to Improve Human-Model Alignment
Oct 09, 2024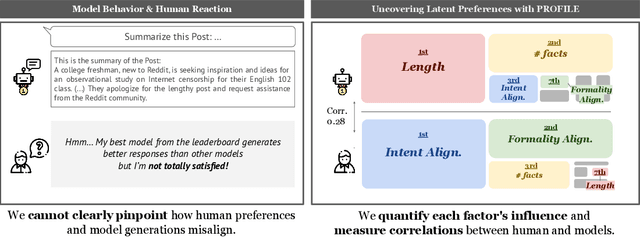

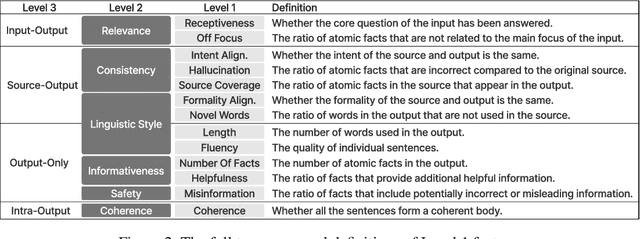

Despite advancements in Large Language Model (LLM) alignment, understanding the reasons behind LLM preferences remains crucial for bridging the gap between desired and actual behavior. LLMs often exhibit biases or tendencies that diverge from human preferences, such as favoring certain writing styles or producing overly verbose outputs. However, current methods for evaluating preference alignment often lack explainability, relying on coarse-grained comparisons. To address this, we introduce PROFILE (PRObing Factors of InfLuence for Explainability), a novel framework that uncovers and quantifies the influence of specific factors driving preferences. PROFILE's factor level analysis explains the 'why' behind human-model alignment and misalignment, offering insights into the direction of model improvement. We apply PROFILE to analyze human and LLM preferences across three tasks: summarization, helpful response generation, and document-based question-answering. Our factor level analysis reveals a substantial discrepancy between human and LLM preferences in generation tasks, whereas LLMs show strong alignment with human preferences in evaluation tasks. We demonstrate how leveraging factor level insights, including addressing misaligned factors or exploiting the generation-evaluation gap, can improve alignment with human preferences. This work underscores the importance of explainable preference analysis and highlights PROFILE's potential to provide valuable training signals, driving further improvements in human-model alignment.
Multi-FAct: Assessing Multilingual LLMs' Multi-Regional Knowledge using FActScore
Mar 01, 2024Large Language Models (LLMs) are prone to factuality hallucination, generating text that contradicts established knowledge. While extensive research has addressed this in English, little is known about multilingual LLMs. This paper systematically evaluates multilingual LLMs' factual accuracy across languages and geographic regions. We introduce a novel pipeline for multilingual factuality evaluation, adapting FActScore(Min et al., 2023) for diverse languages. Our analysis across nine languages reveals that English consistently outperforms others in factual accuracy and quantity of generated facts. Furthermore, multilingual models demonstrate a bias towards factual information from Western continents. These findings highlight the need for improved multilingual factuality assessment and underscore geographical biases in LLMs' fact generation.
The Generative AI Paradox on Evaluation: What It Can Solve, It May Not Evaluate
Feb 09, 2024



This paper explores the assumption that Large Language Models (LLMs) skilled in generation tasks are equally adept as evaluators. We assess the performance of three LLMs and one open-source LM in Question-Answering (QA) and evaluation tasks using the TriviaQA (Joshi et al., 2017) dataset. Results indicate a significant disparity, with LLMs exhibiting lower performance in evaluation tasks compared to generation tasks. Intriguingly, we discover instances of unfaithful evaluation where models accurately evaluate answers in areas where they lack competence, underscoring the need to examine the faithfulness and trustworthiness of LLMs as evaluators. This study contributes to the understanding of "the Generative AI Paradox" (West et al., 2023), highlighting a need to explore the correlation between generative excellence and evaluation proficiency, and the necessity to scrutinize the faithfulness aspect in model evaluations.
KOLD: Korean Offensive Language Dataset
May 23, 2022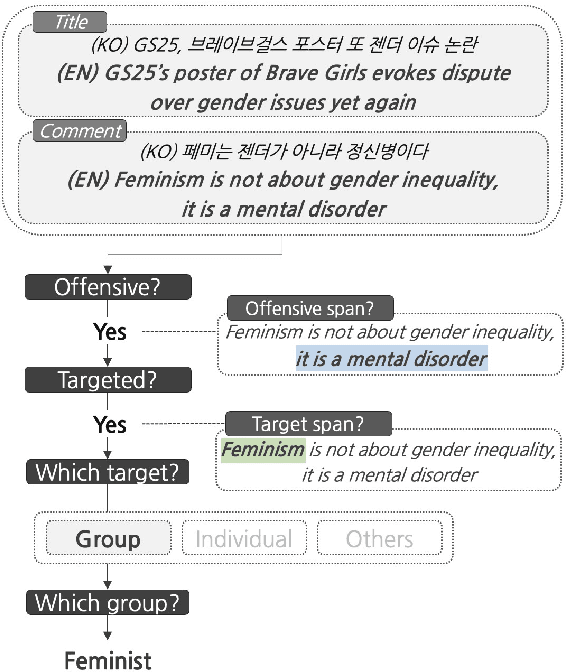
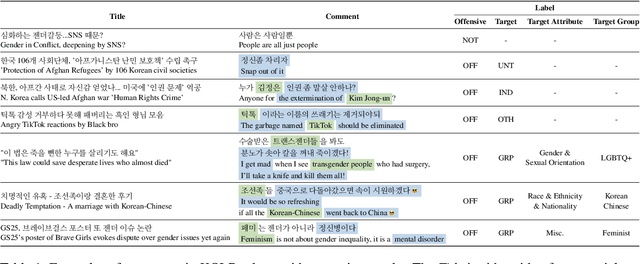
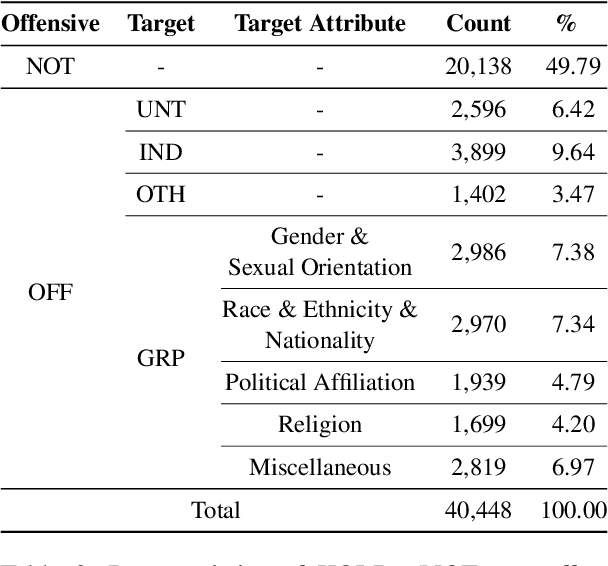
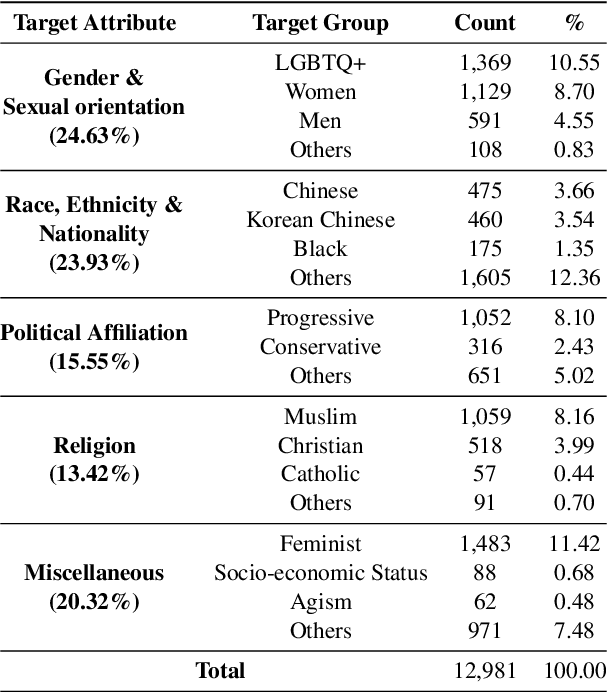
Although large attention has been paid to the detection of hate speech, most work has been done in English, failing to make it applicable to other languages. To fill this gap, we present a Korean offensive language dataset (KOLD), 40k comments labeled with offensiveness, target, and targeted group information. We also collect two types of span, offensive and target span that justifies the decision of the categorization within the text. Comparing the distribution of targeted groups with the existing English dataset, we point out the necessity of a hate speech dataset fitted to the language that best reflects the culture. Trained with our dataset, we report the baseline performance of the models built on top of large pretrained language models. We also show that title information serves as context and is helpful to discern the target of hatred, especially when they are omitted in the comment.
KLUE: Korean Language Understanding Evaluation
Jun 11, 2021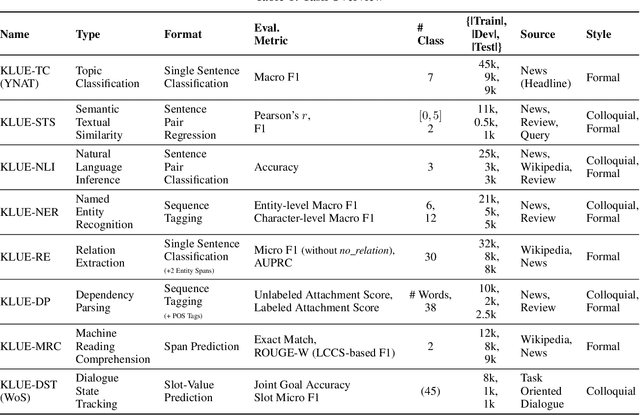
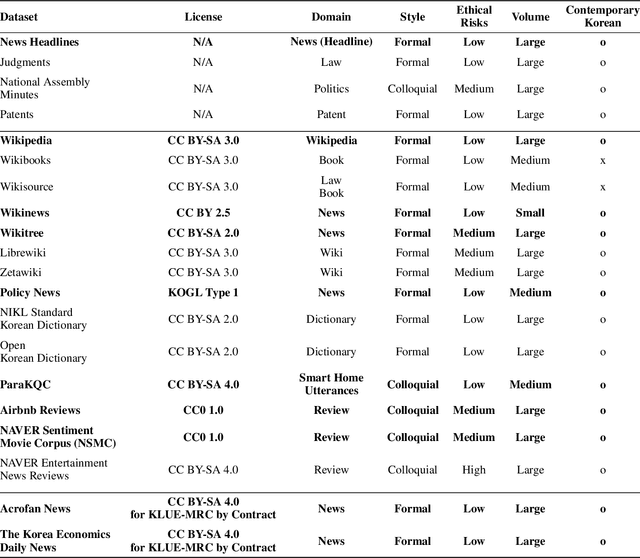
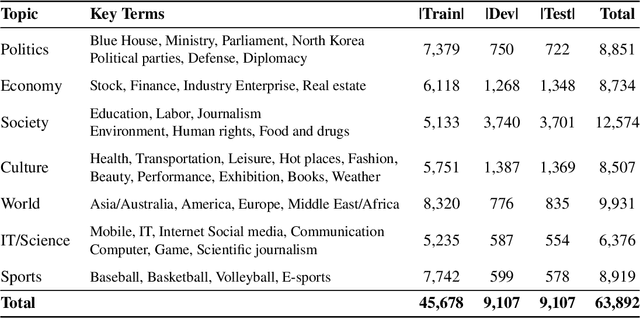
We introduce Korean Language Understanding Evaluation (KLUE) benchmark. KLUE is a collection of 8 Korean natural language understanding (NLU) tasks, including Topic Classification, SemanticTextual Similarity, Natural Language Inference, Named Entity Recognition, Relation Extraction, Dependency Parsing, Machine Reading Comprehension, and Dialogue State Tracking. We build all of the tasks from scratch from diverse source corpora while respecting copyrights, to ensure accessibility for anyone without any restrictions. With ethical considerations in mind, we carefully design annotation protocols. Along with the benchmark tasks and data, we provide suitable evaluation metrics and fine-tuning recipes for pretrained language models for each task. We furthermore release the pretrained language models (PLM), KLUE-BERT and KLUE-RoBERTa, to help reproducing baseline models on KLUE and thereby facilitate future research. We make a few interesting observations from the preliminary experiments using the proposed KLUE benchmark suite, already demonstrating the usefulness of this new benchmark suite. First, we find KLUE-RoBERTa-large outperforms other baselines, including multilingual PLMs and existing open-source Korean PLMs. Second, we see minimal degradation in performance even when we replace personally identifiable information from the pretraining corpus, suggesting that privacy and NLU capability are not at odds with each other. Lastly, we find that using BPE tokenization in combination with morpheme-level pre-tokenization is effective in tasks involving morpheme-level tagging, detection and generation. In addition to accelerating Korean NLP research, our comprehensive documentation on creating KLUE will facilitate creating similar resources for other languages in the future. KLUE is available at https://klue-benchmark.com.