 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKOLD: Korean Offensive Language Dataset
May 23, 2022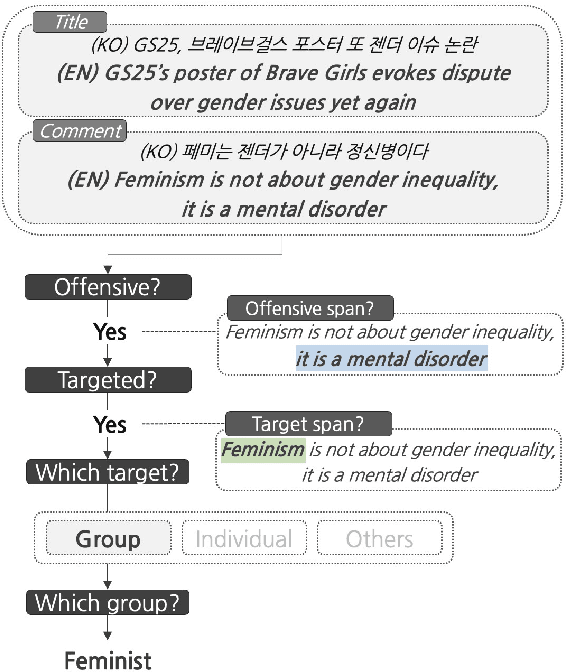
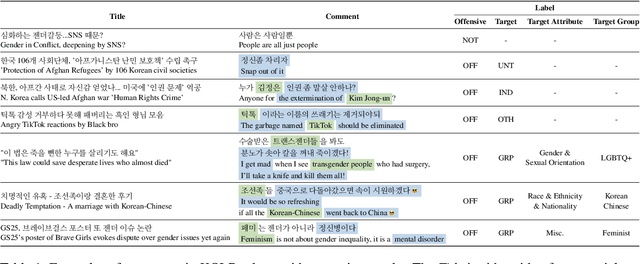
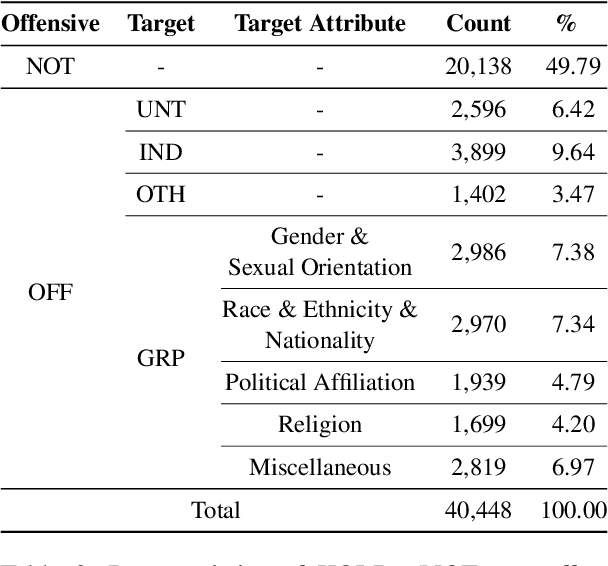
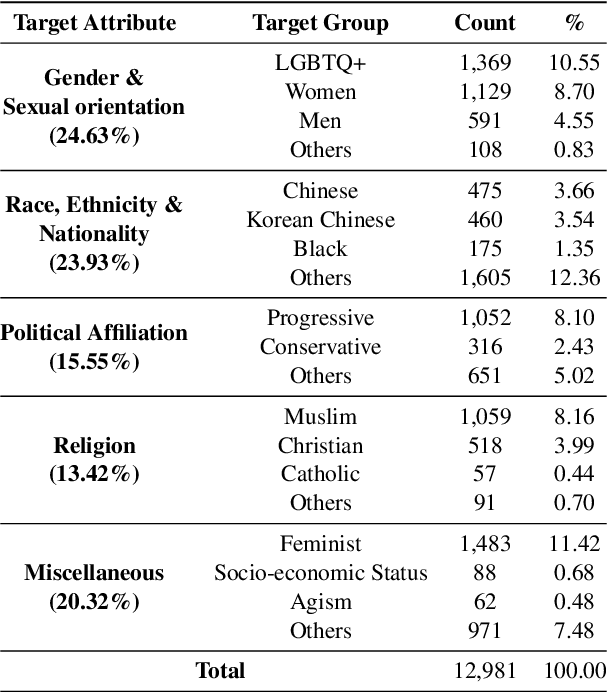
Although large attention has been paid to the detection of hate speech, most work has been done in English, failing to make it applicable to other languages. To fill this gap, we present a Korean offensive language dataset (KOLD), 40k comments labeled with offensiveness, target, and targeted group information. We also collect two types of span, offensive and target span that justifies the decision of the categorization within the text. Comparing the distribution of targeted groups with the existing English dataset, we point out the necessity of a hate speech dataset fitted to the language that best reflects the culture. Trained with our dataset, we report the baseline performance of the models built on top of large pretrained language models. We also show that title information serves as context and is helpful to discern the target of hatred, especially when they are omitted in the comment.
Mitigating Language-Dependent Ethnic Bias in BERT
Sep 14, 2021
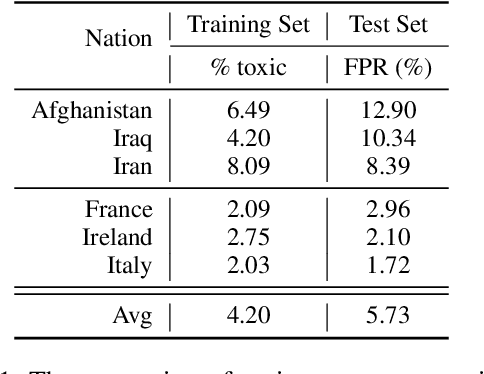
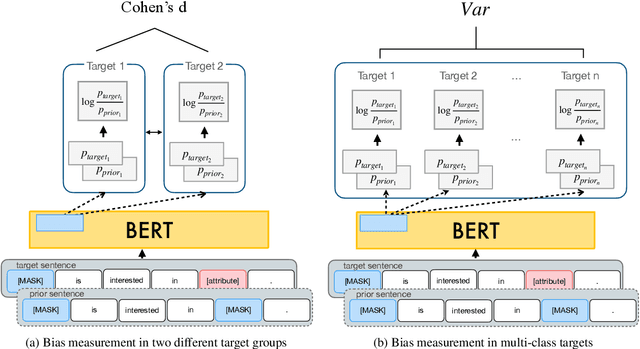
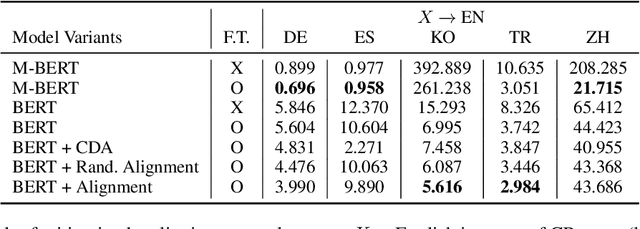
BERT and other large-scale language models (LMs) contain gender and racial bias. They also exhibit other dimensions of social bias, most of which have not been studied in depth, and some of which vary depending on the language. In this paper, we study ethnic bias and how it varies across languages by analyzing and mitigating ethnic bias in monolingual BERT for English, German, Spanish, Korean, Turkish, and Chinese. To observe and quantify ethnic bias, we develop a novel metric called Categorical Bias score. Then we propose two methods for mitigation; first using a multilingual model, and second using contextual word alignment of two monolingual models. We compare our proposed methods with monolingual BERT and show that these methods effectively alleviate the ethnic bias. Which of the two methods works better depends on the amount of NLP resources available for that language. We additionally experiment with Arabic and Greek to verify that our proposed methods work for a wider variety of languages.