 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDon't Look Twice: Faster Video Transformers with Run-Length Tokenization
Nov 07, 2024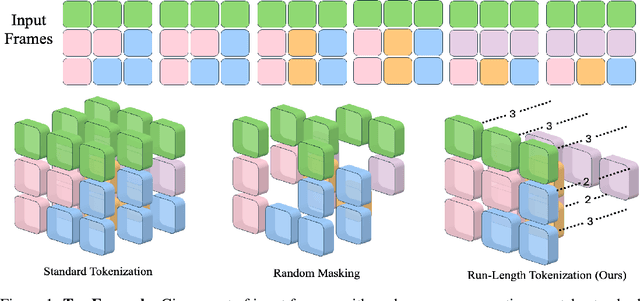
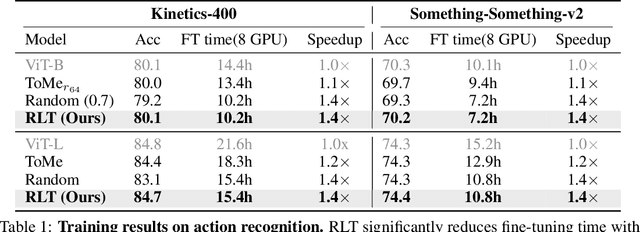
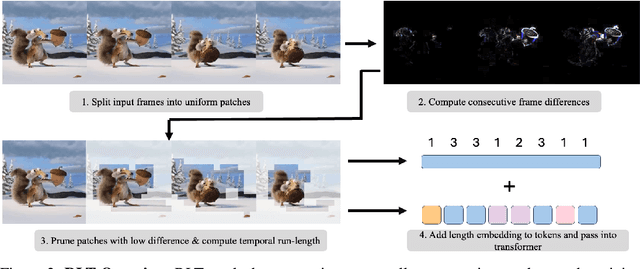
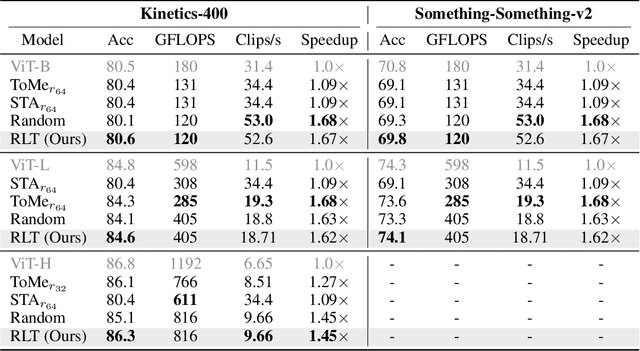
Transformers are slow to train on videos due to extremely large numbers of input tokens, even though many video tokens are repeated over time. Existing methods to remove such uninformative tokens either have significant overhead, negating any speedup, or require tuning for different datasets and examples. We present Run-Length Tokenization (RLT), a simple approach to speed up video transformers inspired by run-length encoding for data compression. RLT efficiently finds and removes runs of patches that are repeated over time prior to model inference, then replaces them with a single patch and a positional encoding to represent the resulting token's new length. Our method is content-aware, requiring no tuning for different datasets, and fast, incurring negligible overhead. RLT yields a large speedup in training, reducing the wall-clock time to fine-tune a video transformer by 30% while matching baseline model performance. RLT also works without any training, increasing model throughput by 35% with only 0.1% drop in accuracy. RLT speeds up training at 30 FPS by more than 100%, and on longer video datasets, can reduce the token count by up to 80%. Our project page is at https://rccchoudhury.github.io/projects/rlt/.
Perils of Self-Feedback: Self-Bias Amplifies in Large Language Models
Feb 18, 2024



Recent studies show that self-feedback improves large language models (LLMs) on certain tasks while worsens other tasks. We discovered that such a contrary is due to LLM's bias towards their own output. In this paper, we formally define LLM's self-bias -- the tendency to favor its own generation -- using two statistics. We analyze six LLMs on translation, constrained text generation, and mathematical reasoning tasks. We find that self-bias is prevalent in all examined LLMs across multiple languages and tasks. Our analysis reveals that while the self-refine pipeline improves the fluency and understandability of model outputs, it further amplifies self-bias. To mitigate such biases, we discover that larger model size and external feedback with accurate assessment can significantly reduce bias in the self-refine pipeline, leading to actual performance improvement in downstream tasks.
HandyPriors: Physically Consistent Perception of Hand-Object Interactions with Differentiable Priors
Dec 03, 2023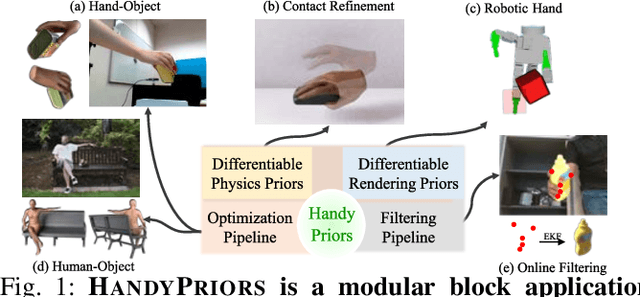
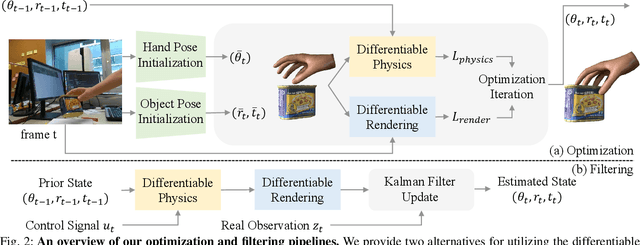
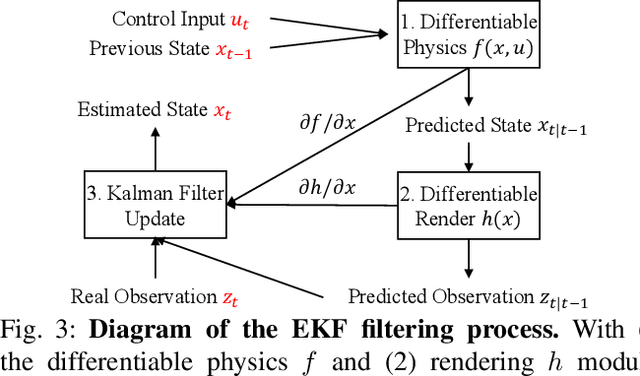

Various heuristic objectives for modeling hand-object interaction have been proposed in past work. However, due to the lack of a cohesive framework, these objectives often possess a narrow scope of applicability and are limited by their efficiency or accuracy. In this paper, we propose HandyPriors, a unified and general pipeline for pose estimation in human-object interaction scenes by leveraging recent advances in differentiable physics and rendering. Our approach employs rendering priors to align with input images and segmentation masks along with physics priors to mitigate penetration and relative-sliding across frames. Furthermore, we present two alternatives for hand and object pose estimation. The optimization-based pose estimation achieves higher accuracy, while the filtering-based tracking, which utilizes the differentiable priors as dynamics and observation models, executes faster. We demonstrate that HandyPriors attains comparable or superior results in the pose estimation task, and that the differentiable physics module can predict contact information for pose refinement. We also show that our approach generalizes to perception tasks, including robotic hand manipulation and human-object pose estimation in the wild.
Fast-Grasp'D: Dexterous Multi-finger Grasp Generation Through Differentiable Simulation
Jun 13, 2023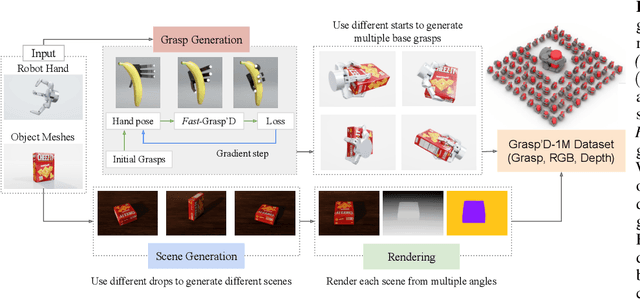
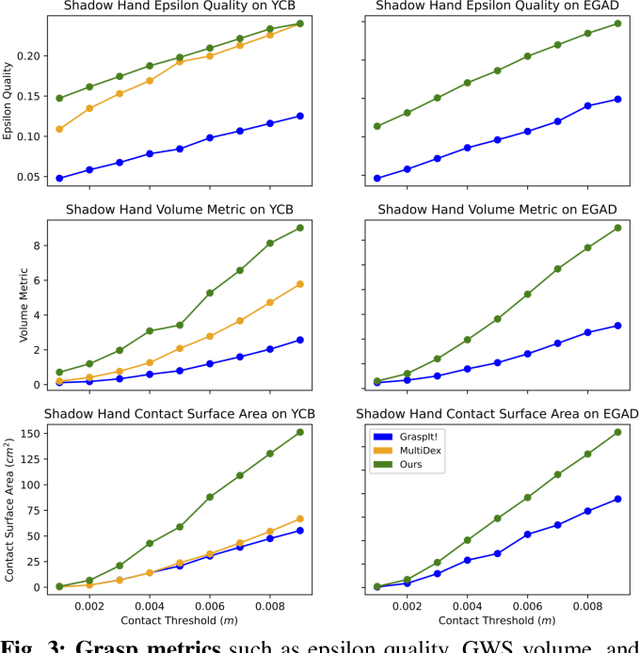
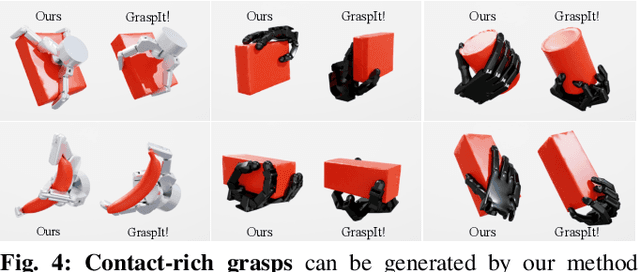

Multi-finger grasping relies on high quality training data, which is hard to obtain: human data is hard to transfer and synthetic data relies on simplifying assumptions that reduce grasp quality. By making grasp simulation differentiable, and contact dynamics amenable to gradient-based optimization, we accelerate the search for high-quality grasps with fewer limiting assumptions. We present Grasp'D-1M: a large-scale dataset for multi-finger robotic grasping, synthesized with Fast- Grasp'D, a novel differentiable grasping simulator. Grasp'D- 1M contains one million training examples for three robotic hands (three, four and five-fingered), each with multimodal visual inputs (RGB+depth+segmentation, available in mono and stereo). Grasp synthesis with Fast-Grasp'D is 10x faster than GraspIt! and 20x faster than the prior Grasp'D differentiable simulator. Generated grasps are more stable and contact-rich than GraspIt! grasps, regardless of the distance threshold used for contact generation. We validate the usefulness of our dataset by retraining an existing vision-based grasping pipeline on Grasp'D-1M, and showing a dramatic increase in model performance, predicting grasps with 30% more contact, a 33% higher epsilon metric, and 35% lower simulated displacement. Additional details at https://dexgrasp.github.io.