 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMAVERIX: Multimodal Audio-Visual Evaluation Reasoning IndeX
Mar 27, 2025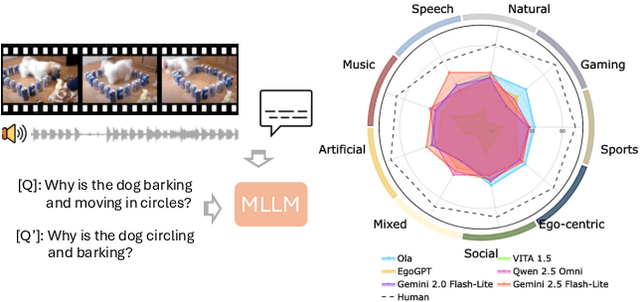
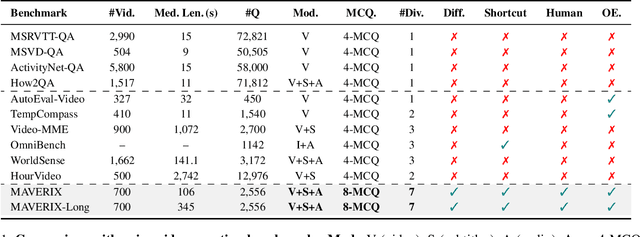
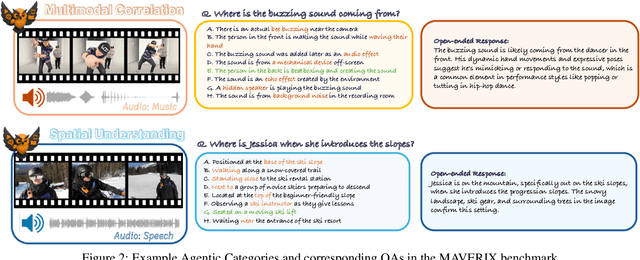
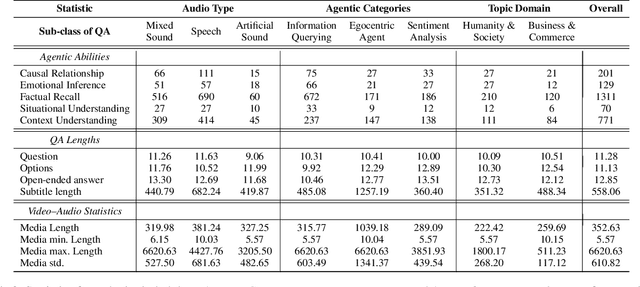
Frontier models have either been language-only or have primarily focused on vision and language modalities. Although recent advancements in models with vision and audio understanding capabilities have shown substantial progress, the field lacks a standardized evaluation framework for thoroughly assessing their cross-modality perception performance. We introduce MAVERIX~(Multimodal Audio-Visual Evaluation Reasoning IndeX), a novel benchmark with 700 videos and 2,556 questions explicitly designed to evaluate multimodal models through tasks that necessitate close integration of video and audio information. MAVERIX uniquely provides models with audiovisual tasks, closely mimicking the multimodal perceptual experiences available to humans during inference and decision-making processes. To our knowledge, MAVERIX is the first benchmark aimed explicitly at assessing comprehensive audiovisual integration. Experiments with state-of-the-art models, including Gemini 1.5 Pro and o1, show performance approaching human levels (around 70% accuracy), while human experts reach near-ceiling performance (95.1%). With standardized evaluation protocols, a rigorously annotated pipeline, and a public toolkit, MAVERIX establishes a challenging testbed for advancing audiovisual multimodal intelligence.
Don't Look Twice: Faster Video Transformers with Run-Length Tokenization
Nov 07, 2024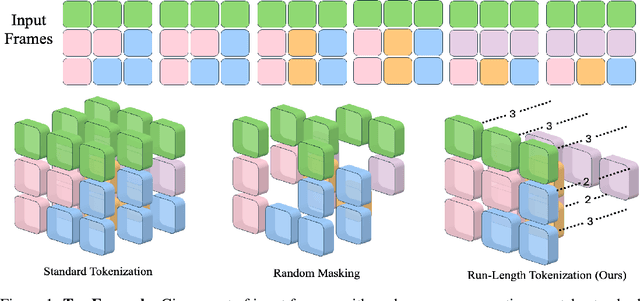
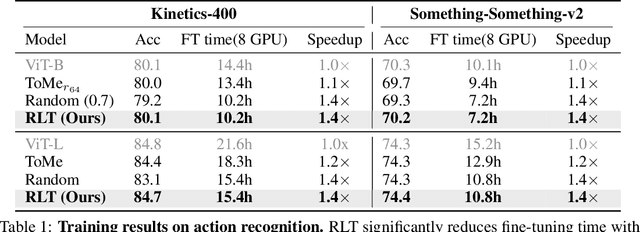
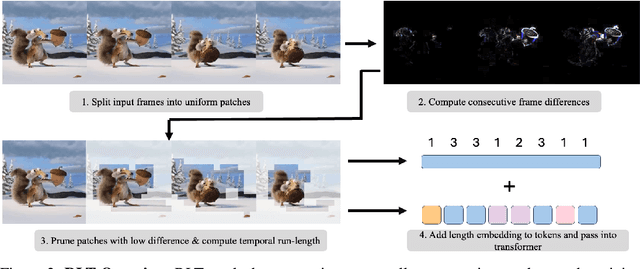
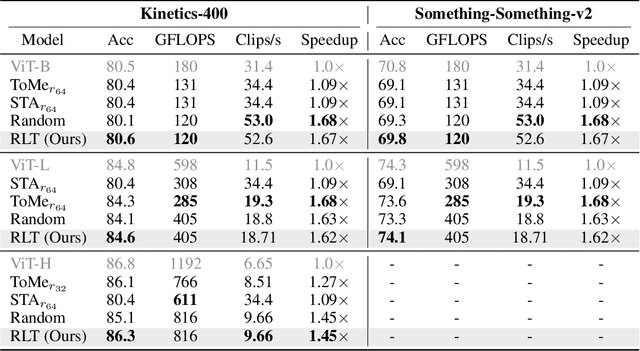
Transformers are slow to train on videos due to extremely large numbers of input tokens, even though many video tokens are repeated over time. Existing methods to remove such uninformative tokens either have significant overhead, negating any speedup, or require tuning for different datasets and examples. We present Run-Length Tokenization (RLT), a simple approach to speed up video transformers inspired by run-length encoding for data compression. RLT efficiently finds and removes runs of patches that are repeated over time prior to model inference, then replaces them with a single patch and a positional encoding to represent the resulting token's new length. Our method is content-aware, requiring no tuning for different datasets, and fast, incurring negligible overhead. RLT yields a large speedup in training, reducing the wall-clock time to fine-tune a video transformer by 30% while matching baseline model performance. RLT also works without any training, increasing model throughput by 35% with only 0.1% drop in accuracy. RLT speeds up training at 30 FPS by more than 100%, and on longer video datasets, can reduce the token count by up to 80%. Our project page is at https://rccchoudhury.github.io/projects/rlt/.
JaywalkerVR: A VR System for Collecting Safety-Critical Pedestrian-Vehicle Interactions
Jul 05, 2024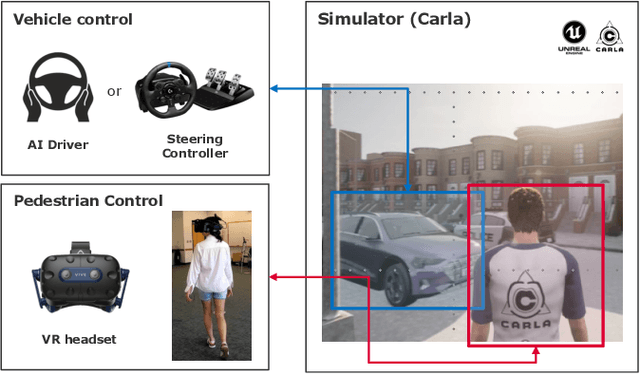


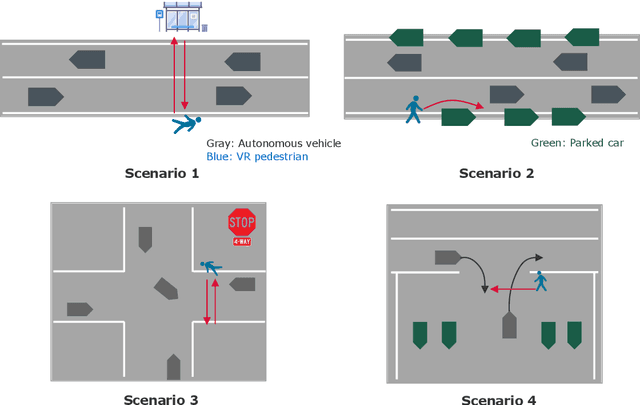
Developing autonomous vehicles that can safely interact with pedestrians requires large amounts of pedestrian and vehicle data in order to learn accurate pedestrian-vehicle interaction models. However, gathering data that include crucial but rare scenarios - such as pedestrians jaywalking into heavy traffic - can be costly and unsafe to collect. We propose a virtual reality human-in-the-loop simulator, JaywalkerVR, to obtain vehicle-pedestrian interaction data to address these challenges. Our system enables efficient, affordable, and safe collection of long-tail pedestrian-vehicle interaction data. Using our proposed simulator, we create a high-quality dataset with vehicle-pedestrian interaction data from safety critical scenarios called CARLA-VR. The CARLA-VR dataset addresses the lack of long-tail data samples in commonly used real world autonomous driving datasets. We demonstrate that models trained with CARLA-VR improve displacement error and collision rate by 10.7% and 4.9%, respectively, and are more robust in rare vehicle-pedestrian scenarios.
Zero-Shot Video Question Answering with Procedural Programs
Dec 01, 2023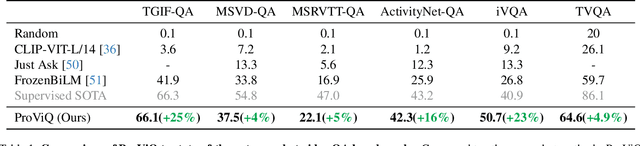
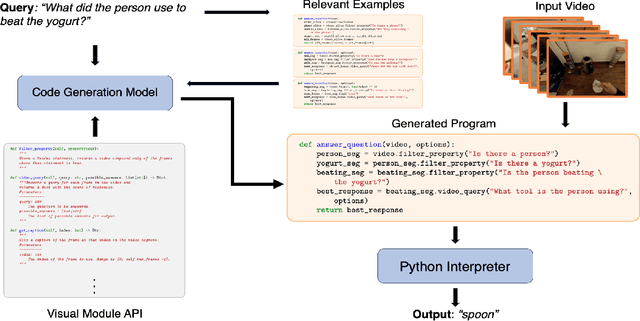
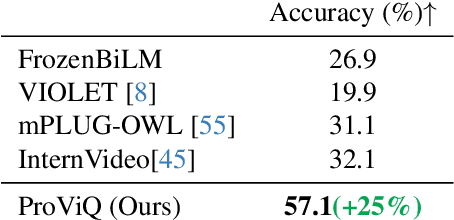
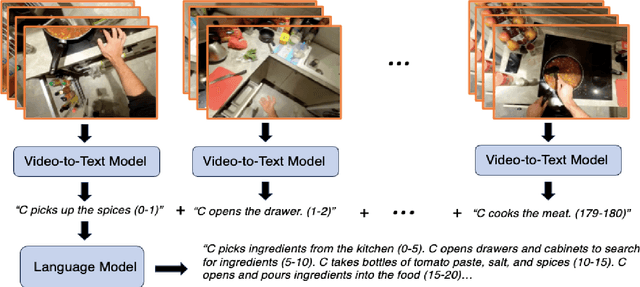
We propose to answer zero-shot questions about videos by generating short procedural programs that derive a final answer from solving a sequence of visual subtasks. We present Procedural Video Querying (ProViQ), which uses a large language model to generate such programs from an input question and an API of visual modules in the prompt, then executes them to obtain the output. Recent similar procedural approaches have proven successful for image question answering, but videos remain challenging: we provide ProViQ with modules intended for video understanding, allowing it to generalize to a wide variety of videos. This code generation framework additionally enables ProViQ to perform other video tasks in addition to question answering, such as multi-object tracking or basic video editing. ProViQ achieves state-of-the-art results on a diverse range of benchmarks, with improvements of up to 25% on short, long, open-ended, and multimodal video question-answering datasets. Our project page is at https://rccchoudhury.github.io/proviq2023.
TEMPO: Efficient Multi-View Pose Estimation, Tracking, and Forecasting
Sep 14, 2023



Existing volumetric methods for predicting 3D human pose estimation are accurate, but computationally expensive and optimized for single time-step prediction. We present TEMPO, an efficient multi-view pose estimation model that learns a robust spatiotemporal representation, improving pose accuracy while also tracking and forecasting human pose. We significantly reduce computation compared to the state-of-the-art by recurrently computing per-person 2D pose features, fusing both spatial and temporal information into a single representation. In doing so, our model is able to use spatiotemporal context to predict more accurate human poses without sacrificing efficiency. We further use this representation to track human poses over time as well as predict future poses. Finally, we demonstrate that our model is able to generalize across datasets without scene-specific fine-tuning. TEMPO achieves 10$\%$ better MPJPE with a 33$\times$ improvement in FPS compared to TesseTrack on the challenging CMU Panoptic Studio dataset.