 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUltrON: Ultrasound Occupancy Networks
Sep 10, 2025In free-hand ultrasound imaging, sonographers rely on expertise to mentally integrate partial 2D views into 3D anatomical shapes. Shape reconstruction can assist clinicians in this process. Central to this task is the choice of shape representation, as it determines how accurately and efficiently the structure can be visualized, analyzed, and interpreted. Implicit representations, such as SDF and occupancy function, offer a powerful alternative to traditional voxel- or mesh-based methods by modeling continuous, smooth surfaces with compact storage, avoiding explicit discretization. Recent studies demonstrate that SDF can be effectively optimized using annotations derived from segmented B-mode ultrasound images. Yet, these approaches hinge on precise annotations, overlooking the rich acoustic information embedded in B-mode intensity. Moreover, implicit representation approaches struggle with the ultrasound's view-dependent nature and acoustic shadowing artifacts, which impair reconstruction. To address the problems resulting from occlusions and annotation dependency, we propose an occupancy-based representation and introduce \gls{UltrON} that leverages acoustic features to improve geometric consistency in weakly-supervised optimization regime. We show that these features can be obtained from B-mode images without additional annotation cost. Moreover, we propose a novel loss function that compensates for view-dependency in the B-mode images and facilitates occupancy optimization from multiview ultrasound. By incorporating acoustic properties, \gls{UltrON} generalizes to shapes of the same anatomy. We show that \gls{UltrON} mitigates the limitations of occlusions and sparse labeling and paves the way for more accurate 3D reconstruction. Code and dataset will be available at https://github.com/magdalena-wysocki/ultron.
MAVERIX: Multimodal Audio-Visual Evaluation Reasoning IndeX
Mar 27, 2025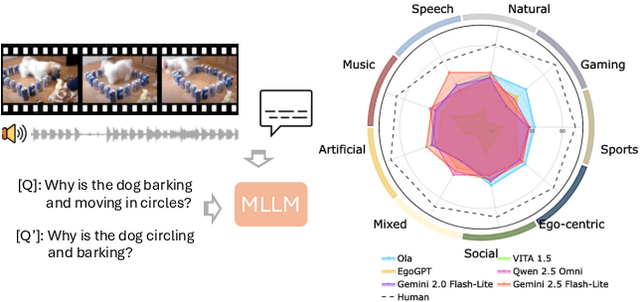
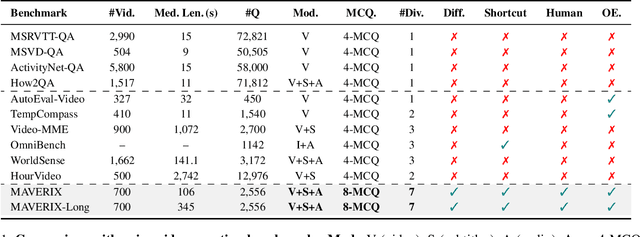
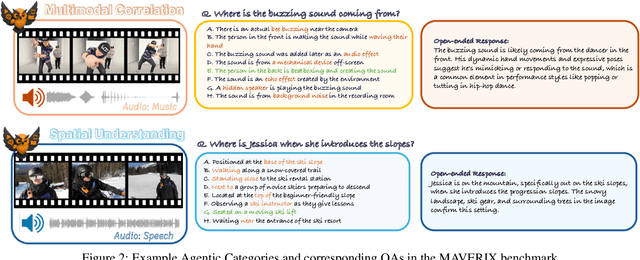
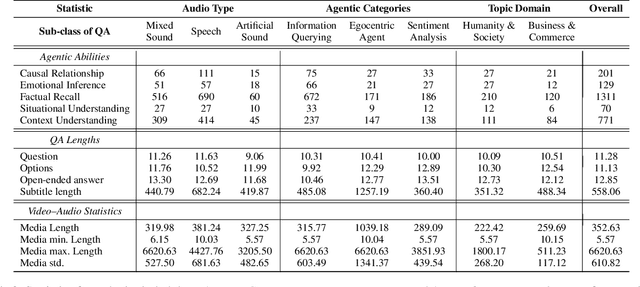
Frontier models have either been language-only or have primarily focused on vision and language modalities. Although recent advancements in models with vision and audio understanding capabilities have shown substantial progress, the field lacks a standardized evaluation framework for thoroughly assessing their cross-modality perception performance. We introduce MAVERIX~(Multimodal Audio-Visual Evaluation Reasoning IndeX), a novel benchmark with 700 videos and 2,556 questions explicitly designed to evaluate multimodal models through tasks that necessitate close integration of video and audio information. MAVERIX uniquely provides models with audiovisual tasks, closely mimicking the multimodal perceptual experiences available to humans during inference and decision-making processes. To our knowledge, MAVERIX is the first benchmark aimed explicitly at assessing comprehensive audiovisual integration. Experiments with state-of-the-art models, including Gemini 1.5 Pro and o1, show performance approaching human levels (around 70% accuracy), while human experts reach near-ceiling performance (95.1%). With standardized evaluation protocols, a rigorously annotated pipeline, and a public toolkit, MAVERIX establishes a challenging testbed for advancing audiovisual multimodal intelligence.
Unsupervised Deformable Ultrasound Image Registration and Its Application for Vessel Segmentation
Jun 23, 2023This paper presents a deep-learning model for deformable registration of ultrasound images at online rates, which we call U-RAFT. As its name suggests, U-RAFT is based on RAFT, a convolutional neural network for estimating optical flow. U-RAFT, however, can be trained in an unsupervised manner and can generate synthetic images for training vessel segmentation models. We propose and compare the registration quality of different loss functions for training U-RAFT. We also show how our approach, together with a robot performing force-controlled scans, can be used to generate synthetic deformed images to significantly expand the size of a femoral vessel segmentation training dataset without the need for additional manual labeling. We validate our approach on both a silicone human tissue phantom as well as on in-vivo porcine images. We show that U-RAFT generates synthetic ultrasound images with 98% and 81% structural similarity index measure (SSIM) to the real ultrasound images for the phantom and porcine datasets, respectively. We also demonstrate that synthetic deformed images from U-RAFT can be used as a data augmentation technique for vessel segmentation models to improve intersection-over-union (IoU) segmentation performance