 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHandyPriors: Physically Consistent Perception of Hand-Object Interactions with Differentiable Priors
Dec 03, 2023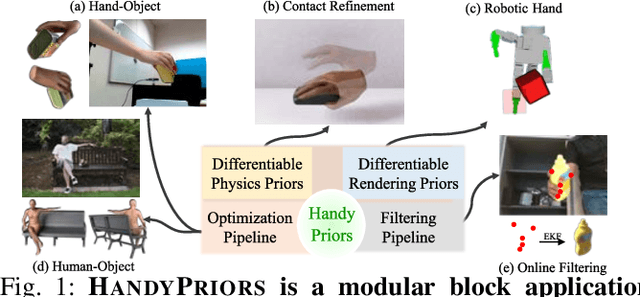
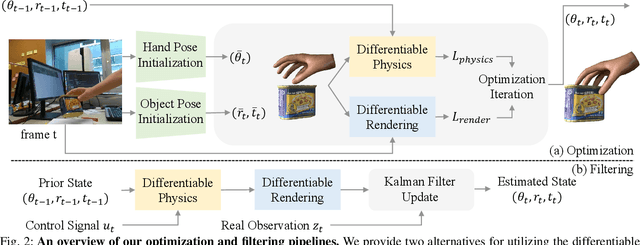
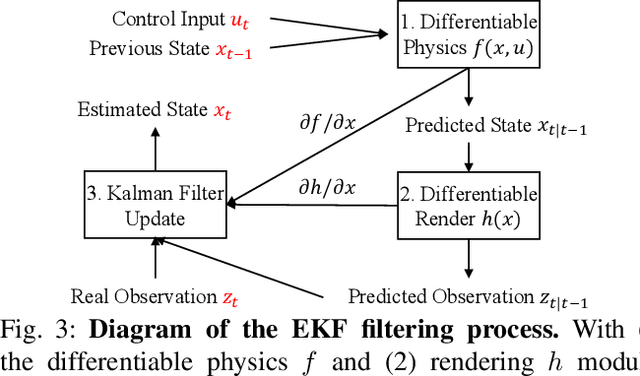

Various heuristic objectives for modeling hand-object interaction have been proposed in past work. However, due to the lack of a cohesive framework, these objectives often possess a narrow scope of applicability and are limited by their efficiency or accuracy. In this paper, we propose HandyPriors, a unified and general pipeline for pose estimation in human-object interaction scenes by leveraging recent advances in differentiable physics and rendering. Our approach employs rendering priors to align with input images and segmentation masks along with physics priors to mitigate penetration and relative-sliding across frames. Furthermore, we present two alternatives for hand and object pose estimation. The optimization-based pose estimation achieves higher accuracy, while the filtering-based tracking, which utilizes the differentiable priors as dynamics and observation models, executes faster. We demonstrate that HandyPriors attains comparable or superior results in the pose estimation task, and that the differentiable physics module can predict contact information for pose refinement. We also show that our approach generalizes to perception tasks, including robotic hand manipulation and human-object pose estimation in the wild.
Fast-Grasp'D: Dexterous Multi-finger Grasp Generation Through Differentiable Simulation
Jun 13, 2023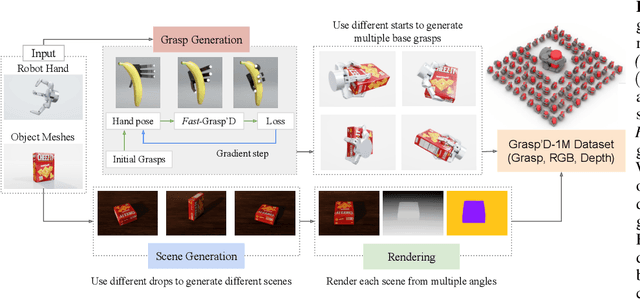
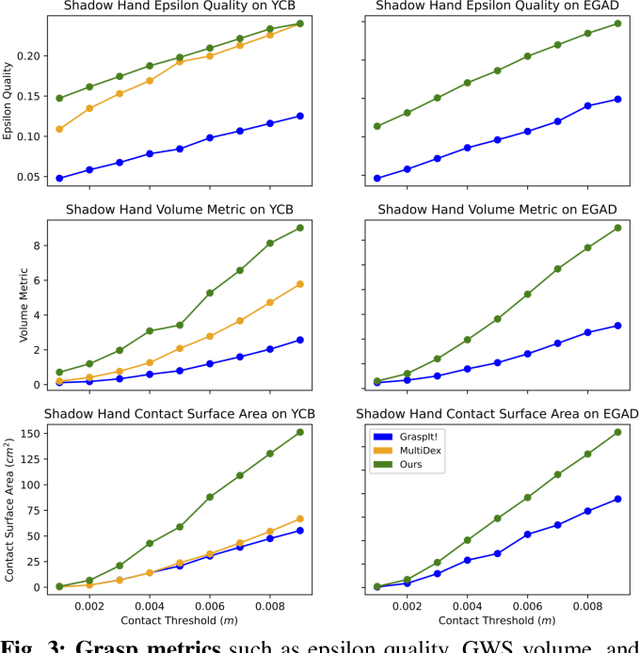
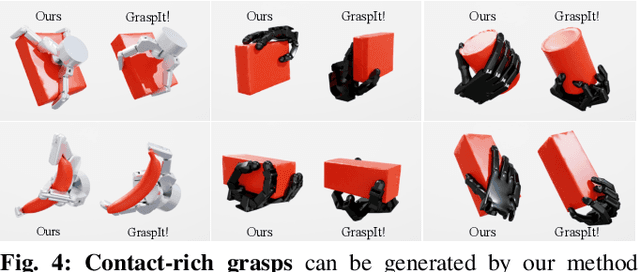

Multi-finger grasping relies on high quality training data, which is hard to obtain: human data is hard to transfer and synthetic data relies on simplifying assumptions that reduce grasp quality. By making grasp simulation differentiable, and contact dynamics amenable to gradient-based optimization, we accelerate the search for high-quality grasps with fewer limiting assumptions. We present Grasp'D-1M: a large-scale dataset for multi-finger robotic grasping, synthesized with Fast- Grasp'D, a novel differentiable grasping simulator. Grasp'D- 1M contains one million training examples for three robotic hands (three, four and five-fingered), each with multimodal visual inputs (RGB+depth+segmentation, available in mono and stereo). Grasp synthesis with Fast-Grasp'D is 10x faster than GraspIt! and 20x faster than the prior Grasp'D differentiable simulator. Generated grasps are more stable and contact-rich than GraspIt! grasps, regardless of the distance threshold used for contact generation. We validate the usefulness of our dataset by retraining an existing vision-based grasping pipeline on Grasp'D-1M, and showing a dramatic increase in model performance, predicting grasps with 30% more contact, a 33% higher epsilon metric, and 35% lower simulated displacement. Additional details at https://dexgrasp.github.io.
Grasp'D: Differentiable Contact-rich Grasp Synthesis for Multi-fingered Hands
Aug 26, 2022


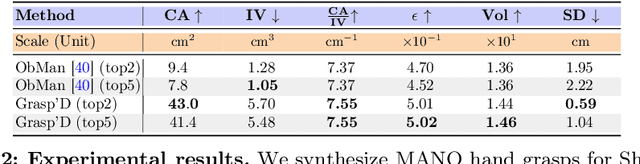
The study of hand-object interaction requires generating viable grasp poses for high-dimensional multi-finger models, often relying on analytic grasp synthesis which tends to produce brittle and unnatural results. This paper presents Grasp'D, an approach for grasp synthesis with a differentiable contact simulation from both known models as well as visual inputs. We use gradient-based methods as an alternative to sampling-based grasp synthesis, which fails without simplifying assumptions, such as pre-specified contact locations and eigengrasps. Such assumptions limit grasp discovery and, in particular, exclude high-contact power grasps. In contrast, our simulation-based approach allows for stable, efficient, physically realistic, high-contact grasp synthesis, even for gripper morphologies with high-degrees of freedom. We identify and address challenges in making grasp simulation amenable to gradient-based optimization, such as non-smooth object surface geometry, contact sparsity, and a rugged optimization landscape. Grasp'D compares favorably to analytic grasp synthesis on human and robotic hand models, and resultant grasps achieve over 4x denser contact, leading to significantly higher grasp stability. Video and code available at https://graspd-eccv22.github.io/.
Neural Shape Mating: Self-Supervised Object Assembly with Adversarial Shape Priors
May 30, 2022Learning to autonomously assemble shapes is a crucial skill for many robotic applications. While the majority of existing part assembly methods focus on correctly posing semantic parts to recreate a whole object, we interpret assembly more literally: as mating geometric parts together to achieve a snug fit. By focusing on shape alignment rather than semantic cues, we can achieve across-category generalization. In this paper, we introduce a novel task, pairwise 3D geometric shape mating, and propose Neural Shape Mating (NSM) to tackle this problem. Given the point clouds of two object parts of an unknown category, NSM learns to reason about the fit of the two parts and predict a pair of 3D poses that tightly mate them together. We couple the training of NSM with an implicit shape reconstruction task to make NSM more robust to imperfect point cloud observations. To train NSM, we present a self-supervised data collection pipeline that generates pairwise shape mating data with ground truth by randomly cutting an object mesh into two parts, resulting in a dataset that consists of 200K shape mating pairs from numerous object meshes with diverse cut types. We train NSM on the collected dataset and compare it with several point cloud registration methods and one part assembly baseline. Extensive experimental results and ablation studies under various settings demonstrate the effectiveness of the proposed algorithm. Additional material is available at: https://neural-shape-mating.github.io/
GIFT: Generalizable Interaction-aware Functional Tool Affordances without Labels
Jun 28, 2021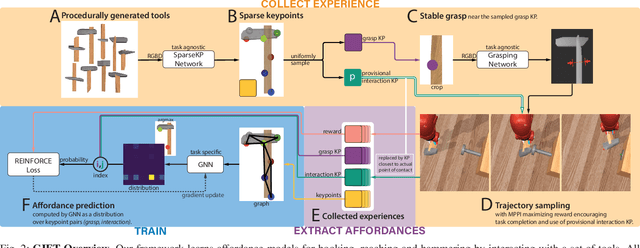
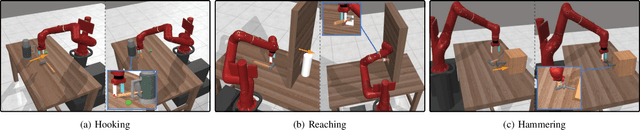

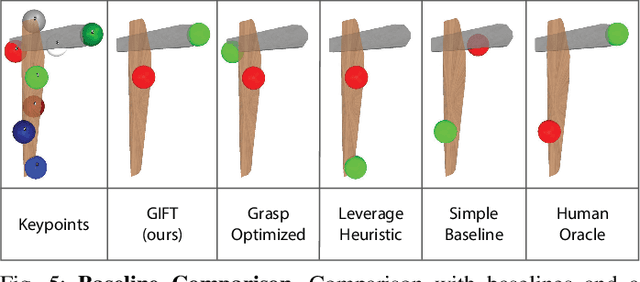
Tool use requires reasoning about the fit between an object's affordances and the demands of a task. Visual affordance learning can benefit from goal-directed interaction experience, but current techniques rely on human labels or expert demonstrations to generate this data. In this paper, we describe a method that grounds affordances in physical interactions instead, thus removing the need for human labels or expert policies. We use an efficient sampling-based method to generate successful trajectories that provide contact data, which are then used to reveal affordance representations. Our framework, GIFT, operates in two phases: first, we discover visual affordances from goal-directed interaction with a set of procedurally generated tools; second, we train a model to predict new instances of the discovered affordances on novel tools in a self-supervised fashion. In our experiments, we show that GIFT can leverage a sparse keypoint representation to predict grasp and interaction points to accommodate multiple tasks, such as hooking, reaching, and hammering. GIFT outperforms baselines on all tasks and matches a human oracle on two of three tasks using novel tools.
De-anonymization of authors through arXiv submissions during double-blind review
Jul 01, 2020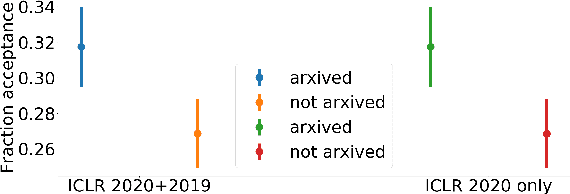
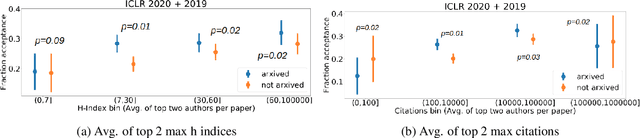
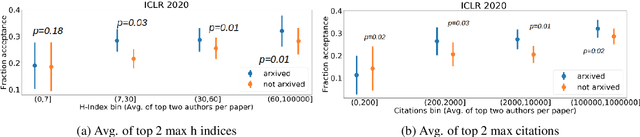
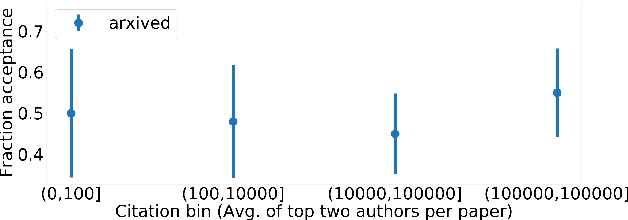
In this paper, we investigate the effects of releasing arXiv preprints of papers that are undergoing a double-blind review process. In particular, we ask the following research question: What is the relation between de-anonymization of authors through arXiv preprints and acceptance of a research paper at a (nominally) double-blind venue? Under two conditions: papers that are released on arXiv before the review phase and papers that are not, we examine the correlation between the reputation of their authors with the review scores and acceptance decisions. By analyzing a dataset of ICLR 2020 and ICLR 2019 submissions (n=5050), we find statistically significant evidence of positive correlation between percentage acceptance and papers with high reputation released on arXiv. In order to understand this observed association better, we perform additional analyses based on self-specified confidence scores of reviewers and observe that less confident reviewers are more likely to assign high review scores to papers with well known authors and low review scores to papers with less known authors, where reputation is quantified in terms of number of Google Scholar citations. We emphasize upfront that our results are purely correlational and we neither can nor intend to make any causal claims. A blog post accompanying the paper and our scraping code will be linked in the project website https://sites.google.com/view/deanon-arxiv/home