 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReSteer: Quantifying and Refining the Steerability of Multitask Robot Policies
Mar 18, 2026Despite strong multi-task pretraining, existing policies often exhibit poor task steerability. For example, a robot may fail to respond to a new instruction ``put the bowl in the sink" when moving towards the oven, executing ``close the oven", even though it can complete both tasks when executed separately. We propose ReSteer, a framework to quantify and improve task steerability in multitask robot policies. We conduct an exhaustive evaluation of state-of-the-art policies, revealing a common lack of steerability. We find that steerability is associated with limited overlap among training task trajectory distributions, and introduce a proxy metric to measure this overlap from policy behavior. Building on this insight, ReSteer improves steerability via three components: (i) a steerability estimator that identifies low-steerability states without full-rollout evaluation, (ii) a steerable data generator that synthesizes motion segments from these states, and (iii) a self-refinement pipeline that improves policy steerability using the generated data. In simulation on LIBERO, ReSteer improves steerability by 11\% over 18k rollouts. In real-world experiments, we show that improved steerability is critical for interactive use, enabling users to instruct robots to perform any task at any time. We hope this work motivates further study on quantifying steerability and data collection strategies for large robot policies.
MosaicMem: Hybrid Spatial Memory for Controllable Video World Models
Mar 17, 2026Video diffusion models are moving beyond short, plausible clips toward world simulators that must remain consistent under camera motion, revisits, and intervention. Yet spatial memory remains a key bottleneck: explicit 3D structures can improve reprojection-based consistency but struggle to depict moving objects, while implicit memory often produces inaccurate camera motion even with correct poses. We propose Mosaic Memory (MosaicMem), a hybrid spatial memory that lifts patches into 3D for reliable localization and targeted retrieval, while exploiting the model's native conditioning to preserve prompt-following generation. MosaicMem composes spatially aligned patches in the queried view via a patch-and-compose interface, preserving what should persist while allowing the model to inpaint what should evolve. With PRoPE camera conditioning and two new memory alignment methods, experiments show improved pose adherence compared to implicit memory and stronger dynamic modeling than explicit baselines. MosaicMem further enables minute-level navigation, memory-based scene editing, and autoregressive rollout.
Dexterous Manipulation Policies from RGB Human Videos via 4D Hand-Object Trajectory Reconstruction
Feb 09, 2026Multi-finger robotic hand manipulation and grasping are challenging due to the high-dimensional action space and the difficulty of acquiring large-scale training data. Existing approaches largely rely on human teleoperation with wearable devices or specialized sensing equipment to capture hand-object interactions, which limits scalability. In this work, we propose VIDEOMANIP, a device-free framework that learns dexterous manipulation directly from RGB human videos. Leveraging recent advances in computer vision, VIDEOMANIP reconstructs explicit 4D robot-object trajectories from monocular videos by estimating human hand poses, object meshes, and retargets the reconstructed human motions to robotic hands for manipulation learning. To make the reconstructed robot data suitable for dexterous manipulation training, we introduce hand-object contact optimization with interaction-centric grasp modeling, as well as a demonstration synthesis strategy that generates diverse training trajectories from a single video, enabling generalizable policy learning without additional robot demonstrations. In simulation, the learned grasping model achieves a 70.25% success rate across 20 diverse objects using the Inspire Hand. In the real world, manipulation policies trained from RGB videos achieve an average 62.86% success rate across seven tasks using the LEAP Hand, outperforming retargeting-based methods by 15.87%. Project videos are available at videomanip.github.io.
Discovering Robotic Interaction Modes with Discrete Representation Learning
Oct 26, 2024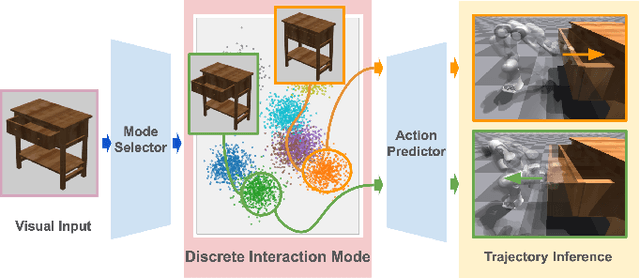
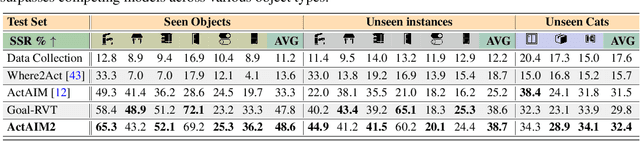
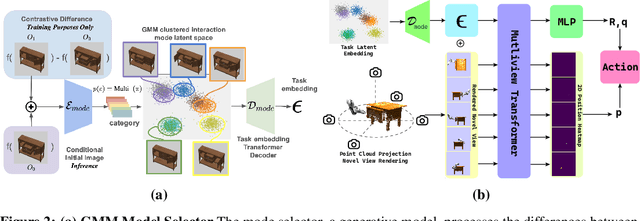

Human actions manipulating articulated objects, such as opening and closing a drawer, can be categorized into multiple modalities we define as interaction modes. Traditional robot learning approaches lack discrete representations of these modes, which are crucial for empirical sampling and grounding. In this paper, we present ActAIM2, which learns a discrete representation of robot manipulation interaction modes in a purely unsupervised fashion, without the use of expert labels or simulator-based privileged information. Utilizing novel data collection methods involving simulator rollouts, ActAIM2 consists of an interaction mode selector and a low-level action predictor. The selector generates discrete representations of potential interaction modes with self-supervision, while the predictor outputs corresponding action trajectories. Our method is validated through its success rate in manipulating articulated objects and its robustness in sampling meaningful actions from the discrete representation. Extensive experiments demonstrate ActAIM2's effectiveness in enhancing manipulability and generalizability over baselines and ablation studies. For videos and additional results, see our website: https://actaim2.github.io/.
Learning Agility and Adaptive Legged Locomotion via Curricular Hindsight Reinforcement Learning
Oct 24, 2023



Agile and adaptive maneuvers such as fall recovery, high-speed turning, and sprinting in the wild are challenging for legged systems. We propose a Curricular Hindsight Reinforcement Learning (CHRL) that learns an end-to-end tracking controller that achieves powerful agility and adaptation for the legged robot. The two key components are (I) a novel automatic curriculum strategy on task difficulty and (ii) a Hindsight Experience Replay strategy adapted to legged locomotion tasks. We demonstrated successful agile and adaptive locomotion on a real quadruped robot that performed fall recovery autonomously, coherent trotting, sustained outdoor speeds up to 3.45 m/s, and tuning speeds up to 3.2 rad/s. This system produces adaptive behaviours responding to changing situations and unexpected disturbances on natural terrains like grass and dirt.
Self-Supervised Learning of Action Affordances as Interaction Modes
May 27, 2023When humans perform a task with an articulated object, they interact with the object only in a handful of ways, while the space of all possible interactions is nearly endless. This is because humans have prior knowledge about what interactions are likely to be successful, i.e., to open a new door we first try the handle. While learning such priors without supervision is easy for humans, it is notoriously hard for machines. In this work, we tackle unsupervised learning of priors of useful interactions with articulated objects, which we call interaction modes. In contrast to the prior art, we use no supervision or privileged information; we only assume access to the depth sensor in the simulator to learn the interaction modes. More precisely, we define a successful interaction as the one changing the visual environment substantially and learn a generative model of such interactions, that can be conditioned on the desired goal state of the object. In our experiments, we show that our model covers most of the human interaction modes, outperforms existing state-of-the-art methods for affordance learning, and can generalize to objects never seen during training. Additionally, we show promising results in the goal-conditional setup, where our model can be quickly fine-tuned to perform a given task. We show in the experiments that such affordance learning predicts interaction which covers most modes of interaction for the querying articulated object and can be fine-tuned to a goal-conditional model. For supplementary: https://actaim.github.io.
Grasp'D: Differentiable Contact-rich Grasp Synthesis for Multi-fingered Hands
Aug 26, 2022


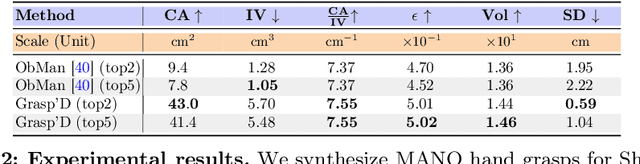
The study of hand-object interaction requires generating viable grasp poses for high-dimensional multi-finger models, often relying on analytic grasp synthesis which tends to produce brittle and unnatural results. This paper presents Grasp'D, an approach for grasp synthesis with a differentiable contact simulation from both known models as well as visual inputs. We use gradient-based methods as an alternative to sampling-based grasp synthesis, which fails without simplifying assumptions, such as pre-specified contact locations and eigengrasps. Such assumptions limit grasp discovery and, in particular, exclude high-contact power grasps. In contrast, our simulation-based approach allows for stable, efficient, physically realistic, high-contact grasp synthesis, even for gripper morphologies with high-degrees of freedom. We identify and address challenges in making grasp simulation amenable to gradient-based optimization, such as non-smooth object surface geometry, contact sparsity, and a rugged optimization landscape. Grasp'D compares favorably to analytic grasp synthesis on human and robotic hand models, and resultant grasps achieve over 4x denser contact, leading to significantly higher grasp stability. Video and code available at https://graspd-eccv22.github.io/.
Balancing Value Underestimation and Overestimation with Realistic Actor-Critic
Nov 10, 2021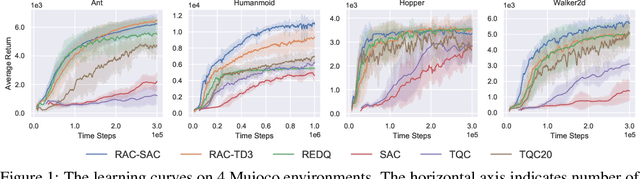

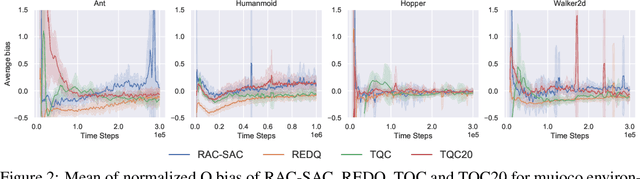
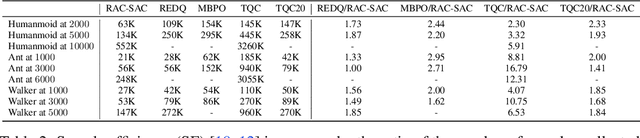
Model-free deep reinforcement learning (RL) has been successfully applied to challenging continuous control domains. However, poor sample efficiency prevents these methods from being widely used in real-world domains. We address this problem by proposing a novel model-free algorithm, Realistic Actor-Critic(RAC), which aims to solve trade-offs between value underestimation and overestimation by learning a policy family concerning various confidence-bounds of Q-function. We construct uncertainty punished Q-learning(UPQ), which uses uncertainty from the ensembling of multiple critics to control estimation bias of Q-function, making Q-functions smoothly shift from lower- to higher-confidence bounds. With the guide of these critics, RAC employs Universal Value Function Approximators (UVFA) to simultaneously learn many optimistic and pessimistic policies with the same neural network. Optimistic policies generate effective exploratory behaviors, while pessimistic policies reduce the risk of value overestimation to ensure stable updates of policies and Q-functions. The proposed method can be incorporated with any off-policy actor-critic RL algorithms. Our method achieve 10x sample efficiency and 25\% performance improvement compared to SAC on the most challenging Humanoid environment, obtaining the episode reward $11107\pm 475$ at $10^6$ time steps. All the source codes are available at https://github.com/ihuhuhu/RAC.
GIFT: Generalizable Interaction-aware Functional Tool Affordances without Labels
Jun 28, 2021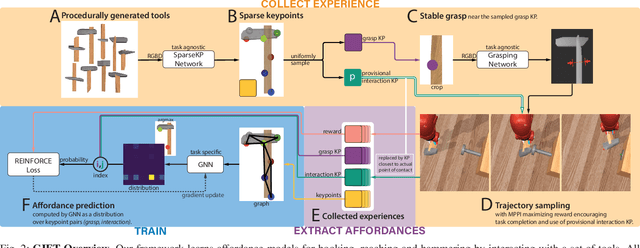
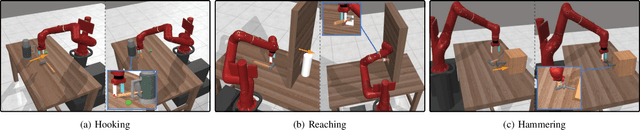

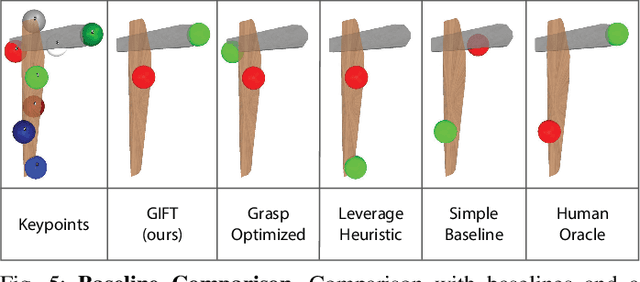
Tool use requires reasoning about the fit between an object's affordances and the demands of a task. Visual affordance learning can benefit from goal-directed interaction experience, but current techniques rely on human labels or expert demonstrations to generate this data. In this paper, we describe a method that grounds affordances in physical interactions instead, thus removing the need for human labels or expert policies. We use an efficient sampling-based method to generate successful trajectories that provide contact data, which are then used to reveal affordance representations. Our framework, GIFT, operates in two phases: first, we discover visual affordances from goal-directed interaction with a set of procedurally generated tools; second, we train a model to predict new instances of the discovered affordances on novel tools in a self-supervised fashion. In our experiments, we show that GIFT can leverage a sparse keypoint representation to predict grasp and interaction points to accommodate multiple tasks, such as hooking, reaching, and hammering. GIFT outperforms baselines on all tasks and matches a human oracle on two of three tasks using novel tools.