 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMem2Ego: Empowering Vision-Language Models with Global-to-Ego Memory for Long-Horizon Embodied Navigation
Feb 20, 2025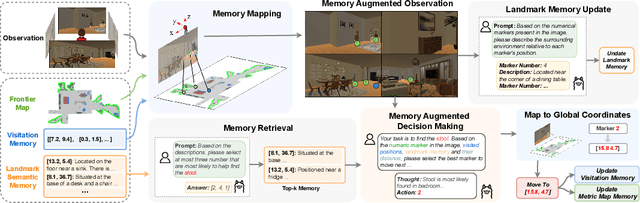
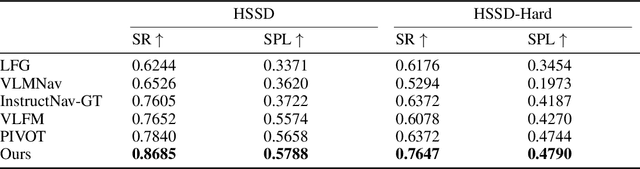
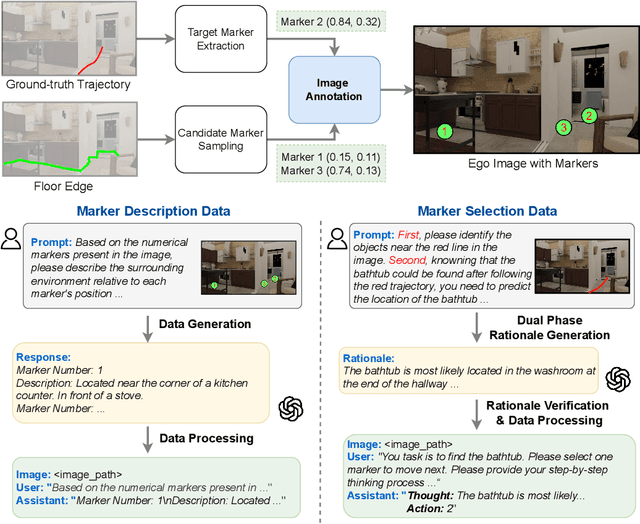

Recent advancements in Large Language Models (LLMs) and Vision-Language Models (VLMs) have made them powerful tools in embodied navigation, enabling agents to leverage commonsense and spatial reasoning for efficient exploration in unfamiliar environments. Existing LLM-based approaches convert global memory, such as semantic or topological maps, into language descriptions to guide navigation. While this improves efficiency and reduces redundant exploration, the loss of geometric information in language-based representations hinders spatial reasoning, especially in intricate environments. To address this, VLM-based approaches directly process ego-centric visual inputs to select optimal directions for exploration. However, relying solely on a first-person perspective makes navigation a partially observed decision-making problem, leading to suboptimal decisions in complex environments. In this paper, we present a novel vision-language model (VLM)-based navigation framework that addresses these challenges by adaptively retrieving task-relevant cues from a global memory module and integrating them with the agent's egocentric observations. By dynamically aligning global contextual information with local perception, our approach enhances spatial reasoning and decision-making in long-horizon tasks. Experimental results demonstrate that the proposed method surpasses previous state-of-the-art approaches in object navigation tasks, providing a more effective and scalable solution for embodied navigation.
Discovering Robotic Interaction Modes with Discrete Representation Learning
Oct 26, 2024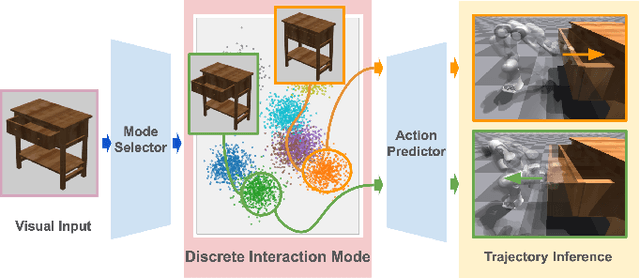
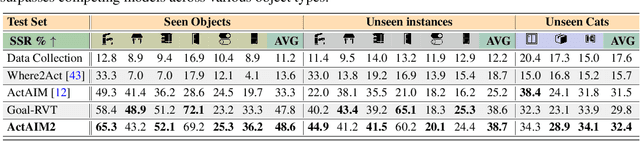
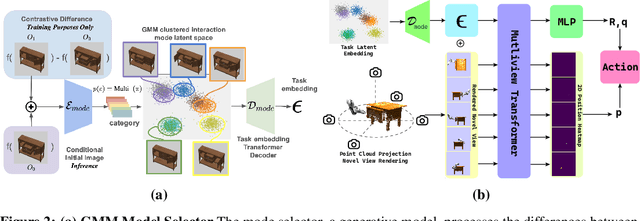

Human actions manipulating articulated objects, such as opening and closing a drawer, can be categorized into multiple modalities we define as interaction modes. Traditional robot learning approaches lack discrete representations of these modes, which are crucial for empirical sampling and grounding. In this paper, we present ActAIM2, which learns a discrete representation of robot manipulation interaction modes in a purely unsupervised fashion, without the use of expert labels or simulator-based privileged information. Utilizing novel data collection methods involving simulator rollouts, ActAIM2 consists of an interaction mode selector and a low-level action predictor. The selector generates discrete representations of potential interaction modes with self-supervision, while the predictor outputs corresponding action trajectories. Our method is validated through its success rate in manipulating articulated objects and its robustness in sampling meaningful actions from the discrete representation. Extensive experiments demonstrate ActAIM2's effectiveness in enhancing manipulability and generalizability over baselines and ablation studies. For videos and additional results, see our website: https://actaim2.github.io/.
ORGANA: A Robotic Assistant for Automated Chemistry Experimentation and Characterization
Jan 13, 2024



Chemistry experimentation is often resource- and labor-intensive. Despite the many benefits incurred by the integration of advanced and special-purpose lab equipment, many aspects of experimentation are still manually conducted by chemists, for example, polishing an electrode in electrochemistry experiments. Traditional lab automation infrastructure faces challenges when it comes to flexibly adapting to new chemistry experiments. To address this issue, we propose a human-friendly and flexible robotic system, ORGANA, that automates a diverse set of chemistry experiments. It is capable of interacting with chemists in the lab through natural language, using Large Language Models (LLMs). ORGANA keeps scientists informed by providing timely reports that incorporate statistical analyses. Additionally, it actively engages with users when necessary for disambiguation or troubleshooting. ORGANA can reason over user input to derive experiment goals, and plan long sequences of both high-level tasks and low-level robot actions while using feedback from the visual perception of the environment. It also supports scheduling and parallel execution for experiments that require resource allocation and coordination between multiple robots and experiment stations. We show that ORGANA successfully conducts a diverse set of chemistry experiments, including solubility assessment, pH measurement, recrystallization, and electrochemistry experiments. For the latter, we show that ORGANA robustly executes a long-horizon plan, comprising 19 steps executed in parallel, to characterize the electrochemical properties of quinone derivatives, a class of molecules used in rechargeable flow batteries. Our user study indicates that ORGANA significantly improves many aspects of user experience while reducing their physical workload. More details about ORGANA can be found at https://ac-rad.github.io/organa/.
MVTrans: Multi-View Perception of Transparent Objects
Feb 22, 2023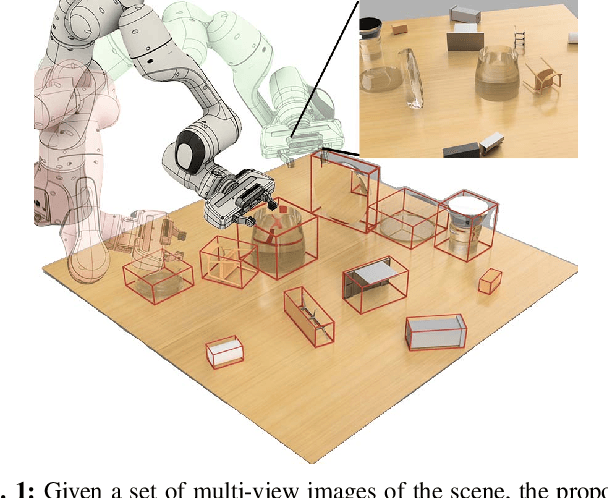

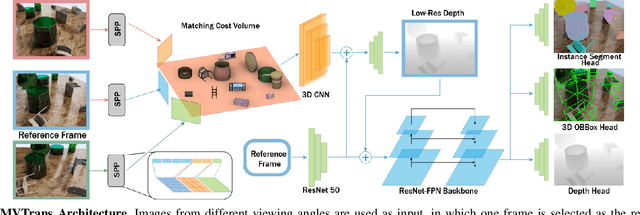

Transparent object perception is a crucial skill for applications such as robot manipulation in household and laboratory settings. Existing methods utilize RGB-D or stereo inputs to handle a subset of perception tasks including depth and pose estimation. However, transparent object perception remains to be an open problem. In this paper, we forgo the unreliable depth map from RGB-D sensors and extend the stereo based method. Our proposed method, MVTrans, is an end-to-end multi-view architecture with multiple perception capabilities, including depth estimation, segmentation, and pose estimation. Additionally, we establish a novel procedural photo-realistic dataset generation pipeline and create a large-scale transparent object detection dataset, Syn-TODD, which is suitable for training networks with all three modalities, RGB-D, stereo and multi-view RGB. Project Site: https://ac-rad.github.io/MVTrans/
An Adaptive Robotics Framework for Chemistry Lab Automation
Dec 19, 2022In the process of materials discovery, chemists currently need to perform many laborious, time-consuming, and often dangerous lab experiments. To accelerate this process, we propose a framework for robots to assist chemists by performing lab experiments autonomously. The solution allows a general-purpose robot to perform diverse chemistry experiments and efficiently make use of available lab tools. Our system can load high-level descriptions of chemistry experiments, perceive a dynamic workspace, and autonomously plan the required actions and motions to perform the given chemistry experiments with common tools found in the existing lab environment. Our architecture uses a modified PDDLStream solver for integrated task and constrained motion planning, which generates plans and motions that are guaranteed to be safe by preventing collisions and spillage. We present a modular framework that can scale to many different experiments, actions, and lab tools. In this work, we demonstrate the utility of our framework on three pouring skills and two foundational chemical experiments for materials synthesis: solubility and recrystallization. More experiments and updated evaluations can be found at https://ac-rad.github.io/arc-icra2023.
Seeing Glass: Joint Point Cloud and Depth Completion for Transparent Objects
Sep 30, 2021
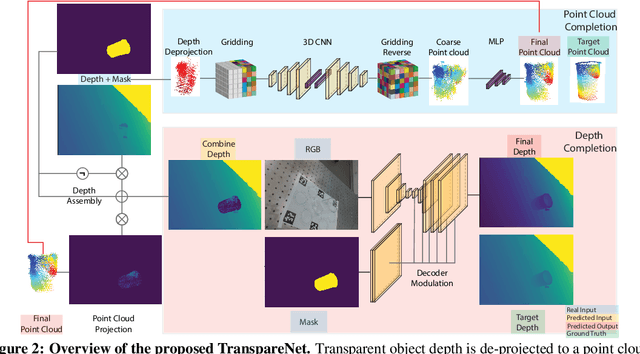
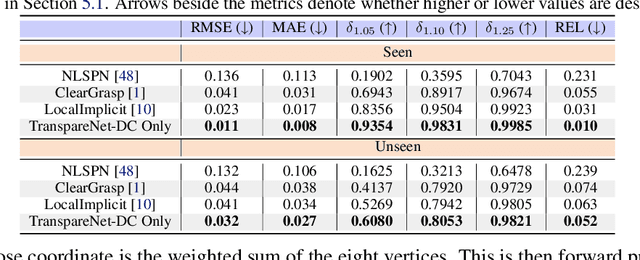
The basis of many object manipulation algorithms is RGB-D input. Yet, commodity RGB-D sensors can only provide distorted depth maps for a wide range of transparent objects due light refraction and absorption. To tackle the perception challenges posed by transparent objects, we propose TranspareNet, a joint point cloud and depth completion method, with the ability to complete the depth of transparent objects in cluttered and complex scenes, even with partially filled fluid contents within the vessels. To address the shortcomings of existing transparent object data collection schemes in literature, we also propose an automated dataset creation workflow that consists of robot-controlled image collection and vision-based automatic annotation. Through this automated workflow, we created Toronto Transparent Objects Depth Dataset (TODD), which consists of nearly 15000 RGB-D images. Our experimental evaluation demonstrates that TranspareNet outperforms existing state-of-the-art depth completion methods on multiple datasets, including ClearGrasp, and that it also handles cluttered scenes when trained on TODD. Code and dataset will be released at https://www.pair.toronto.edu/TranspareNet/
Predicting 3D shapes, masks, and properties of materials, liquids, and objects inside transparent containers, using the TransProteus CGI dataset
Sep 15, 2021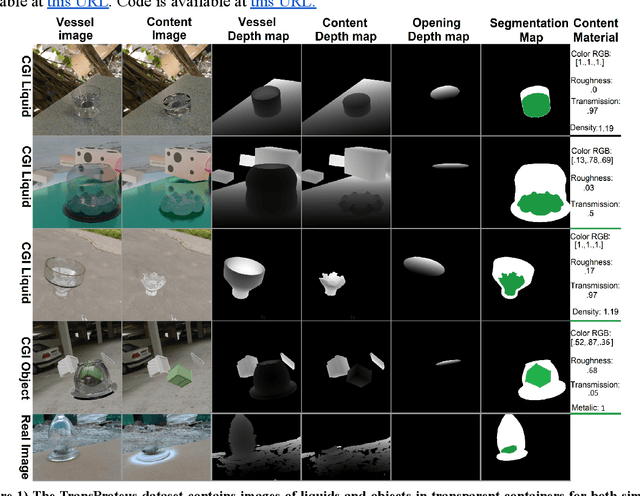
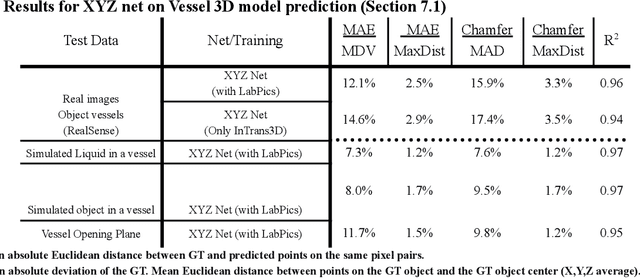
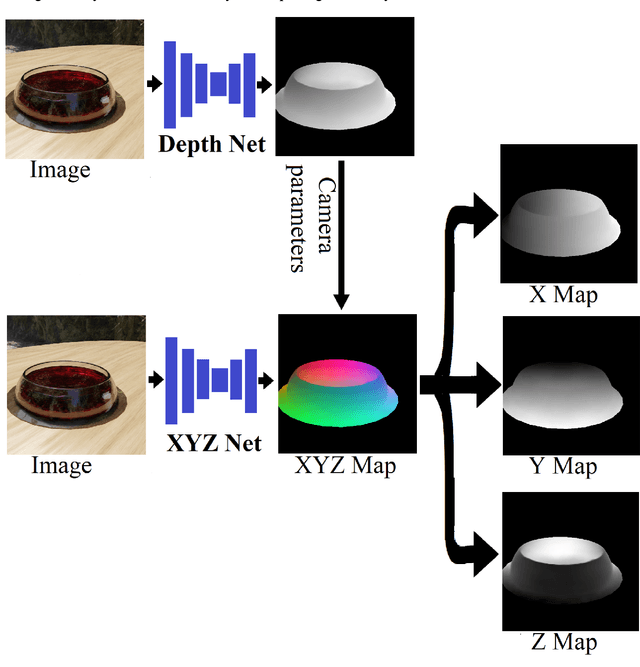
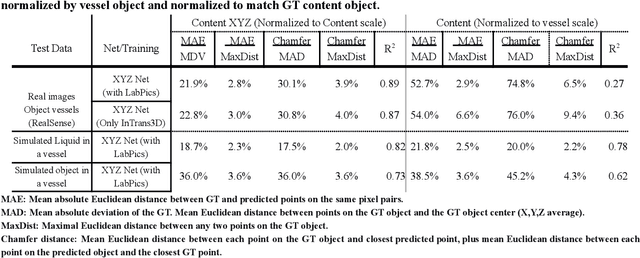
We present TransProteus, a dataset, and methods for predicting the 3D structure, masks, and properties of materials, liquids, and objects inside transparent vessels from a single image without prior knowledge of the image source and camera parameters. Manipulating materials in transparent containers is essential in many fields and depends heavily on vision. This work supplies a new procedurally generated dataset consisting of 50k images of liquids and solid objects inside transparent containers. The image annotations include 3D models, material properties (color/transparency/roughness...), and segmentation masks for the vessel and its content. The synthetic (CGI) part of the dataset was procedurally generated using 13k different objects, 500 different environments (HDRI), and 1450 material textures (PBR) combined with simulated liquids and procedurally generated vessels. In addition, we supply 104 real-world images of objects inside transparent vessels with depth maps of both the vessel and its content. We propose a camera agnostic method that predicts 3D models from an image as an XYZ map. This allows the trained net to predict the 3D model as a map with XYZ coordinates per pixel without prior knowledge of the image source. To calculate the training loss, we use the distance between pairs of points inside the 3D model instead of the absolute XYZ coordinates. This makes the loss function translation invariant. We use this to predict 3D models of vessels and their content from a single image. Finally, we demonstrate a net that uses a single image to predict the material properties of the vessel content and surface.
Computer vision for liquid samples in hospitals and medical labs using hierarchical image segmentation and relations prediction
May 04, 2021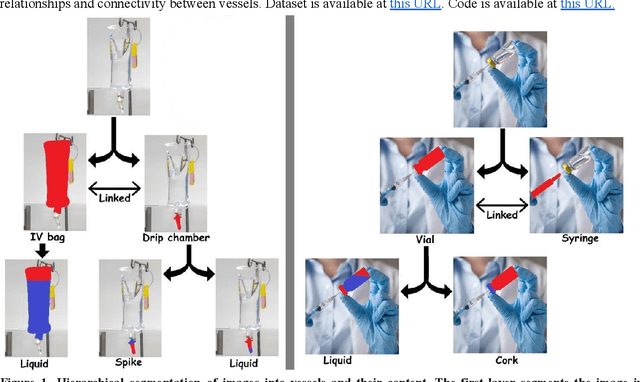
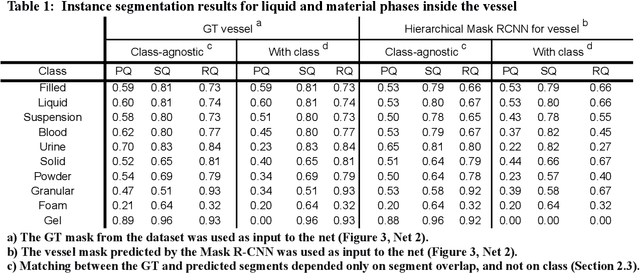
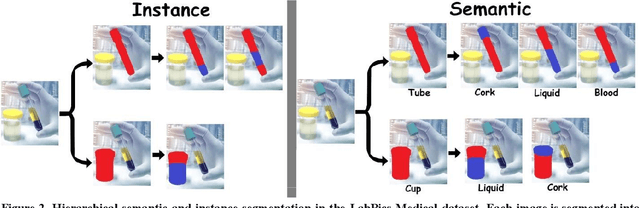
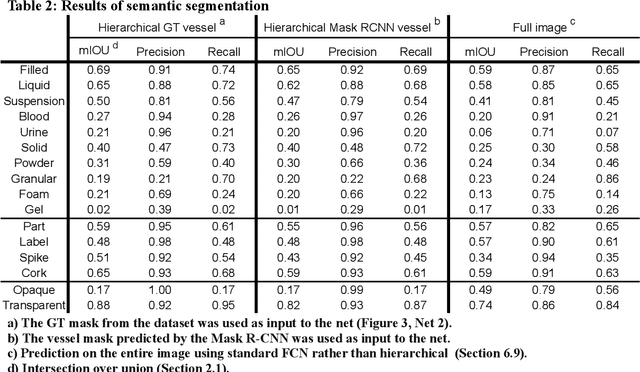
This work explores the use of computer vision for image segmentation and classification of medical fluid samples in transparent containers (for example, tubes, syringes, infusion bags). Handling fluids such as infusion fluids, blood, and urine samples is a significant part of the work carried out in medical labs and hospitals. The ability to accurately identify and segment the liquids and the vessels that contain them from images can help in automating such processes. Modern computer vision typically involves training deep neural nets on large datasets of annotated images. This work presents a new dataset containing 1,300 annotated images of medical samples involving vessels containing liquids and solid material. The images are annotated with the type of liquid (e.g., blood, urine), the phase of the material (e.g., liquid, solid, foam, suspension), the type of vessel (e.g., syringe, tube, cup, infusion bottle/bag), and the properties of the vessel (transparent, opaque). In addition, vessel parts such as corks, labels, spikes, and valves are annotated. Relations and hierarchies between vessels and materials are also annotated, such as which vessel contains which material or which vessels are linked or contain each other. Three neural networks are trained on the dataset: One network learns to detect vessels, a second net detects the materials and parts inside each vessel, and a third net identifies relationships and connectivity between vessels.