 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEl Agente Estructural: An Artificially Intelligent Molecular Editor
Feb 04, 2026We present El Agente Estructural, a multimodal, natural-language-driven geometry-generation and manipulation agent for autonomous chemistry and molecular modelling. Unlike molecular generation or editing via generative models, Estructural mimics how human experts directly manipulate molecular systems in three dimensions by integrating a comprehensive set of domain-informed tools and vision-language models. This design enables precise control over atomic or functional group replacements, atomic connectivity, and stereochemistry without the need to rebuild extensive core molecular frameworks. Through a series of representative case studies, we demonstrate that Estructural enables chemically meaningful geometry manipulation across a wide range of real-world scenarios. These include site-selective functionalization, ligand binding, ligand exchange, stereochemically controlled structure construction, isomer interconversion, fragment-level structural analysis, image-guided generation of structures from schematic reaction mechanisms, and mechanism-driven geometry generation and modification. These examples illustrate how multimodal reasoning, when combined with specialized geometry-aware tools, supports interactive and context-aware molecular modelling beyond structure generation. Looking forward, the integration of Estructural into El Agente Quntur, an autonomous multi-agent quantum chemistry platform, enhances its capabilities by adding sophisticated tools for the generation and editing of three-dimensional structures.
El Agente Quntur: A research collaborator agent for quantum chemistry
Feb 04, 2026Quantum chemistry is a foundational enabling tool for the fields of chemistry, materials science, computational biology and others. Despite of its power, the practical application of quantum chemistry simulations remains in the hands of qualified experts due to methodological complexity, software heterogeneity, and the need for informed interpretation of results. To bridge the accessibility gap for these tools and expand their reach to chemists with broader backgrounds, we introduce El Agente Quntur, a hierarchical, multi-agent AI system designed to operate not merely as an automation tool but as a research collaborator for computational quantum chemistry. Quntur was designed following three main strategies: i) elimination of hard-coded procedural policies in favour of reasoning-driven decisions, ii) construction of general and composable actions that facilitate generalization and efficiency, and iii) implementation of guided deep research to integrate abstract quantum-chemical reasoning across subdisciplines and a detailed understanding of the software's internal logic and syntax. Although instantiated in ORCA, these design principles are applicable to research agents more generally and easily expandable to additional quantum chemistry packages and beyond. Quntur supports the full range of calculations available in ORCA 6.0 and reasons over software documentation and scientific literature to plan, execute, adapt, and analyze in silico chemistry experiments following best practices. We discuss the advances and current bottlenecks in agentic systems operating at the research level in computational chemistry, and outline a roadmap toward a fully autonomous end-to-end computational chemistry research agent.
MATTERIX: toward a digital twin for robotics-assisted chemistry laboratory automation
Jan 19, 2026Accelerated materials discovery is critical for addressing global challenges. However, developing new laboratory workflows relies heavily on real-world experimental trials, and this can hinder scalability because of the need for numerous physical make-and-test iterations. Here we present MATTERIX, a multiscale, graphics processing unit-accelerated robotic simulation framework designed to create high-fidelity digital twins of chemistry laboratories, thus accelerating workflow development. This multiscale digital twin simulates robotic physical manipulation, powder and liquid dynamics, device functionalities, heat transfer and basic chemical reaction kinetics. This is enabled by integrating realistic physics simulation and photorealistic rendering with a modular graphics processing unit-accelerated semantics engine, which models logical states and continuous behaviors to simulate chemistry workflows across different levels of abstraction. MATTERIX streamlines the creation of digital twin environments through open-source asset libraries and interfaces, while enabling flexible workflow design via hierarchical plan definition and a modular skill library that incorporates learning-based methods. Our approach demonstrates sim-to-real transfer in robotic chemistry setups, reducing reliance on costly real-world experiments and enabling the testing of hypothetical automated workflows in silico. The project website is available at https://accelerationconsortium.github.io/Matterix/ .
El Agente: An Autonomous Agent for Quantum Chemistry
May 05, 2025Computational chemistry tools are widely used to study the behaviour of chemical phenomena. Yet, the complexity of these tools can make them inaccessible to non-specialists and challenging even for experts. In this work, we introduce El Agente Q, an LLM-based multi-agent system that dynamically generates and executes quantum chemistry workflows from natural language user prompts. The system is built on a novel cognitive architecture featuring a hierarchical memory framework that enables flexible task decomposition, adaptive tool selection, post-analysis, and autonomous file handling and submission. El Agente Q is benchmarked on six university-level course exercises and two case studies, demonstrating robust problem-solving performance (averaging >87% task success) and adaptive error handling through in situ debugging. It also supports longer-term, multi-step task execution for more complex workflows, while maintaining transparency through detailed action trace logs. Together, these capabilities lay the foundation for increasingly autonomous and accessible quantum chemistry.
Non-destructive Degradation Pattern Decoupling for Ultra-early Battery Prototype Verification Using Physics-informed Machine Learning
Jun 01, 2024



Manufacturing complexities and uncertainties have impeded the transition from material prototypes to commercial batteries, making prototype verification critical to quality assessment. A fundamental challenge involves deciphering intertwined chemical processes to characterize degradation patterns and their quantitative relationship with battery performance. Here we show that a physics-informed machine learning approach can quantify and visualize temporally resolved losses concerning thermodynamics and kinetics only using electric signals. Our method enables non-destructive degradation pattern characterization, expediting temperature-adaptable predictions of entire lifetime trajectories, rather than end-of-life points. The verification speed is 25 times faster yet maintaining 95.1% accuracy across temperatures. Such advances facilitate more sustainable management of defective prototypes before massive production, establishing a 19.76 billion USD scrap material recycling market by 2060 in China. By incorporating stepwise charge acceptance as a measure of the initial manufacturing variability of normally identical batteries, we can immediately identify long-term degradation variations. We attribute the predictive power to interpreting machine learning insights using material-agnostic featurization taxonomy for degradation pattern decoupling. Our findings offer new possibilities for dynamic system analysis, such as battery prototype degradation, demonstrating that complex pattern evolutions can be accurately predicted in a non-destructive and data-driven fashion by integrating physics-informed machine learning.
ORGANA: A Robotic Assistant for Automated Chemistry Experimentation and Characterization
Jan 13, 2024



Chemistry experimentation is often resource- and labor-intensive. Despite the many benefits incurred by the integration of advanced and special-purpose lab equipment, many aspects of experimentation are still manually conducted by chemists, for example, polishing an electrode in electrochemistry experiments. Traditional lab automation infrastructure faces challenges when it comes to flexibly adapting to new chemistry experiments. To address this issue, we propose a human-friendly and flexible robotic system, ORGANA, that automates a diverse set of chemistry experiments. It is capable of interacting with chemists in the lab through natural language, using Large Language Models (LLMs). ORGANA keeps scientists informed by providing timely reports that incorporate statistical analyses. Additionally, it actively engages with users when necessary for disambiguation or troubleshooting. ORGANA can reason over user input to derive experiment goals, and plan long sequences of both high-level tasks and low-level robot actions while using feedback from the visual perception of the environment. It also supports scheduling and parallel execution for experiments that require resource allocation and coordination between multiple robots and experiment stations. We show that ORGANA successfully conducts a diverse set of chemistry experiments, including solubility assessment, pH measurement, recrystallization, and electrochemistry experiments. For the latter, we show that ORGANA robustly executes a long-horizon plan, comprising 19 steps executed in parallel, to characterize the electrochemical properties of quinone derivatives, a class of molecules used in rechargeable flow batteries. Our user study indicates that ORGANA significantly improves many aspects of user experience while reducing their physical workload. More details about ORGANA can be found at https://ac-rad.github.io/organa/.
Revealing the structure of language model capabilities
Jun 14, 2023Building a theoretical understanding of the capabilities of large language models (LLMs) is vital for our ability to predict and explain the behavior of these systems. Here, we investigate the structure of LLM capabilities by extracting latent capabilities from patterns of individual differences across a varied population of LLMs. Using a combination of Bayesian and frequentist factor analysis, we analyzed data from 29 different LLMs across 27 cognitive tasks. We found evidence that LLM capabilities are not monolithic. Instead, they are better explained by three well-delineated factors that represent reasoning, comprehension and core language modeling. Moreover, we found that these three factors can explain a high proportion of the variance in model performance. These results reveal a consistent structure in the capabilities of different LLMs and demonstrate the multifaceted nature of these capabilities. We also found that the three abilities show different relationships to model properties such as model size and instruction tuning. These patterns help refine our understanding of scaling laws and indicate that changes to a model that improve one ability might simultaneously impair others. Based on these findings, we suggest that benchmarks could be streamlined by focusing on tasks that tap into each broad model ability.
One-shot recognition of any material anywhere using contrastive learning with physics-based rendering
Dec 14, 2022


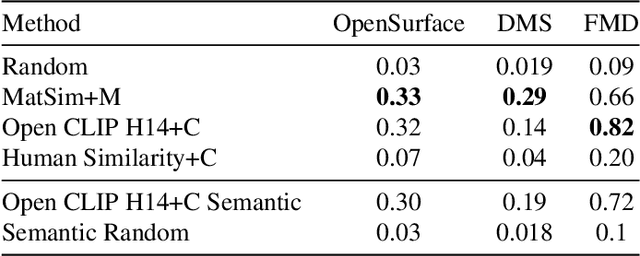
We present MatSim: a synthetic dataset, a benchmark, and a method for computer vision based recognition of similarities and transitions between materials and textures, focusing on identifying any material under any conditions using one or a few examples (one-shot learning). The visual recognition of materials is essential to everything from examining food while cooking to inspecting agriculture, chemistry, and industrial products. In this work, we utilize giant repositories used by computer graphics artists to generate a new CGI dataset for material similarity. We use physics-based rendering (PBR) repositories for visual material simulation, assign these materials random 3D objects, and render images with a vast range of backgrounds and illumination conditions (HDRI). We add a gradual transition between materials to support applications with a smooth transition between states (like gradually cooked food). We also render materials inside transparent containers to support beverage and chemistry lab use cases. We then train a contrastive learning network to generate a descriptor that identifies unfamiliar materials using a single image. We also present a new benchmark for a few-shot material recognition that contains a wide range of real-world examples, including the state of a chemical reaction, rotten/fresh fruits, states of food, different types of construction materials, types of ground, and many other use cases involving material states, transitions and subclasses. We show that a network trained on the MatSim synthetic dataset outperforms state-of-the-art models like Clip on the benchmark, despite being tested on material classes that were not seen during training. The dataset, benchmark, code and trained models are available online.
TOSE: A Fast Capacity Estimation Algorithm Based on Spike Approximations
Sep 02, 2022
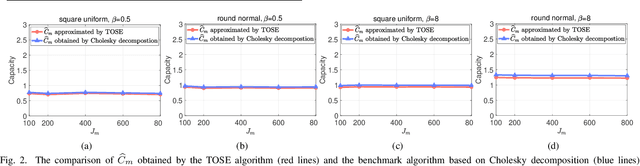
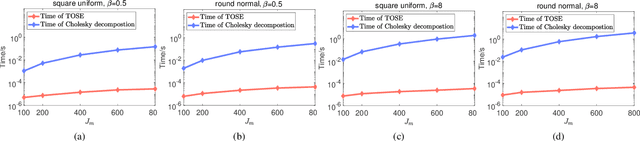
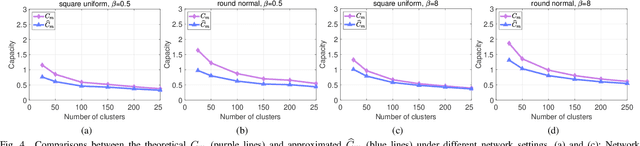
Capacity is one of the most important performance metrics for wireless communication networks. It describes the maximum rate at which the information can be transmitted of a wireless communication system. To support the growing demand for wireless traffic, wireless networks are becoming more dense and complicated, leading to a higher difficulty to derive the capacity. Unfortunately, most existing methods for the capacity calculation take a polynomial time complexity. This will become unaffordable for future ultra-dense networks, where both the number of base stations (BSs) and the number of users are extremely large. In this paper, we propose a fast algorithm TOSE to estimate the capacity for ultra-dense wireless networks. Based on the spiked model of random matrix theory (RMT), our algorithm can avoid the exact eigenvalue derivations of large dimensional matrices, which are complicated and inevitable in conventional capacity calculation methods. Instead, fast eigenvalue estimations can be realized based on the spike approximations in our TOSE algorithm. Our simulation results show that TOSE is an accurate and fast capacity approximation algorithm. Its estimation error is below 5%, and it runs in linear time, which is much lower than the polynomial time complexity of existing methods. In addition, TOSE has superior generality, since it is independent of the distributions of BSs and users, and the shape of network areas.
* 6 pages, 4 figures. arXiv admin note: text overlap with arXiv:2204.03393