 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShape and Texture Recognition in Large Vision-Language Models
Mar 29, 2025



Shape and texture recognition is fundamental to visual perception. The ability to identify shapes regardless of orientation, texture, or context, and to recognize textures independently of their associated objects, is essential for general visual understanding of the world. We introduce the Large Shape & Textures dataset (LAS&T), a giant collection of diverse shapes and textures automatically extracted from real-world images. This dataset is used to evaluate how effectively leading Large Vision-Language Models (LVLMs) understand shapes, textures, and materials in both 2D and 3D scenes. For shape recognition, we test models' ability to match identical shapes that differ in orientation, texture, color, or environment. Our results show that LVLMs' shape identification capabilities remain significantly below human performance. Single alterations (orientation, texture) cause minor decreases in matching accuracy, while multiple changes precipitate dramatic drops. LVLMs appear to rely predominantly on high-level and semantic features and struggle with abstract shapes lacking clear class associations. For texture and material recognition, we evaluate models' ability to identify identical textures and materials across different objects and environments. Interestingly, leading LVLMs approach human-level performance in recognizing materials in 3D scenes, yet substantially underperform humans when identifying simpler 2D textures. The LAS&T dataset and benchmark, the largest and most diverse resource for shape and texture evaluation, is freely available with generation and testing scripts.
Do large language vision models understand 3D shapes?
Dec 17, 2024Large vision language models (LVLM) are the leading A.I approach for achieving a general visual understanding of the world. Models such as GPT, Claude, Gemini, and LLama can use images to understand and analyze complex visual scenes. 3D objects and shapes are the basic building blocks of the world, recognizing them is a fundamental part of human perception. The goal of this work is to test whether LVLMs truly understand 3D shapes by testing the models ability to identify and match objects of the exact same 3D shapes but with different orientations and materials/textures. Test images were created using CGI with a huge number of highly diverse objects, materials, and scenes. The results of this test show that the ability of such models to match 3D shapes is significantly below humans but much higher than random guesses. Suggesting that the models have gained some abstract understanding of 3D shapes but still trail far beyond humans in this task. Mainly it seems that the models can easily identify the same object with a different orientation as well as matching identical 3D shapes of the same orientation but with different material textures. However, when both the object material and orientation are changed, all models perform poorly relative to humans.
Vastextures: Vast repository of textures and PBR materials extracted from real-world images using unsupervised methods
Jun 24, 2024



Vastextures is a vast repository of 500,000 textures and PBR materials extracted from real-world images using an unsupervised process. The extracted materials and textures are extremely diverse and cover a vast range of real-world patterns, but at the same time less refined compared to existing repositories. The repository is composed of 2D textures cropped from natural images and SVBRDF/PBR materials generated from these textures. Textures and PBR materials are essential for CGI. Existing materials repositories focus on games, animation, and arts, that demand a limited amount of high-quality assets. However, virtual worlds and synthetic data are becoming increasingly important for training A.I systems for computer vision. This application demands a huge amount of diverse assets but at the same time less affected by noisy and unrefined assets. Vastexture aims to address this need by creating a free, huge, and diverse assets repository that covers as many real-world materials as possible. The materials are automatically extracted from natural images in two steps: 1) Automatically scanning a giant amount of images to identify and crop regions with uniform textures. This is done by splitting the image into a grid of cells and identifying regions in which all of the cells share a similar statistical distribution. 2) Extracting the properties of the PBR material from the cropped texture. This is done by randomly guessing every correlation between the properties of the texture image and the properties of the PBR material. The resulting PBR materials exhibit a vast amount of real-world patterns as well as unexpected emergent properties. Neutral nets trained on this repository outperformed nets trained using handcrafted assets.
Learning Zero-Shot Material States Segmentation, by Implanting Natural Image Patterns in Synthetic Data
Mar 14, 2024Visual understanding and segmentation of materials and their states is fundamental for understanding the physical world. The infinite textures, shapes, and often blurry boundaries formed by materials make this task particularly hard to generalize. Whether it's identifying wet regions of a surface, minerals in rocks, infected regions in plants, or pollution in water, each material state has its own unique form. For neural nets to learn general class-agnostic materials segmentation it is necessary to first collect and annotate data that capture this complexity. Collecting and manually annotating real-world images is limited by the cost and precision of manual labor. In contrast, synthetic CGI data is highly accurate and almost cost-free but fails to replicate the vast diversity of the material world. This work offers a method to bridge this crucial gap, by implanting patterns extracted from real-world images, in synthetic data. Hence, patterns automatically collected from natural images are used to map materials into synthetic scenes. This unsupervised approach allows the generated data to capture the vast complexity of the real world while maintaining the precision and scale of synthetic data. We also present the first general benchmark for class-agnostic material state segmentation. The benchmark contains a wide range of real-world images of material states, from cooking, food, rocks, construction, plants, and liquids each in various states (wet/dry/stained/cooked/burned/worn/rusted/sediment/foam...). The annotation includes both partial similarity between regions with similar but not identical materials, and hard segmentation of only points of the exact same material state. We show that net trains on MatSeg significantly outperform existing state-of-the-art methods on this task. The dataset, code, and trained model are available.
One-shot recognition of any material anywhere using contrastive learning with physics-based rendering
Dec 14, 2022


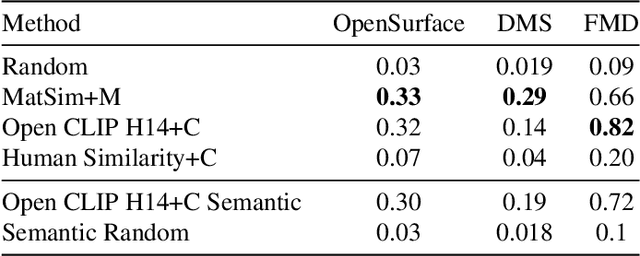
We present MatSim: a synthetic dataset, a benchmark, and a method for computer vision based recognition of similarities and transitions between materials and textures, focusing on identifying any material under any conditions using one or a few examples (one-shot learning). The visual recognition of materials is essential to everything from examining food while cooking to inspecting agriculture, chemistry, and industrial products. In this work, we utilize giant repositories used by computer graphics artists to generate a new CGI dataset for material similarity. We use physics-based rendering (PBR) repositories for visual material simulation, assign these materials random 3D objects, and render images with a vast range of backgrounds and illumination conditions (HDRI). We add a gradual transition between materials to support applications with a smooth transition between states (like gradually cooked food). We also render materials inside transparent containers to support beverage and chemistry lab use cases. We then train a contrastive learning network to generate a descriptor that identifies unfamiliar materials using a single image. We also present a new benchmark for a few-shot material recognition that contains a wide range of real-world examples, including the state of a chemical reaction, rotten/fresh fruits, states of food, different types of construction materials, types of ground, and many other use cases involving material states, transitions and subclasses. We show that a network trained on the MatSim synthetic dataset outperforms state-of-the-art models like Clip on the benchmark, despite being tested on material classes that were not seen during training. The dataset, benchmark, code and trained models are available online.
Predicting the Future of AI with AI: High-quality link prediction in an exponentially growing knowledge network
Sep 23, 2022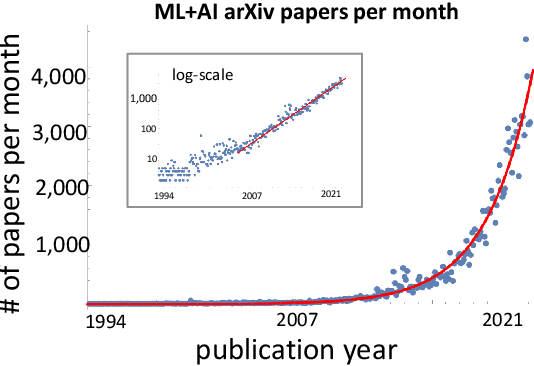
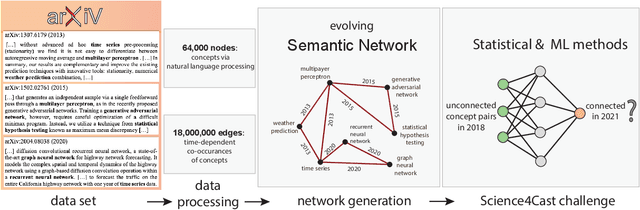
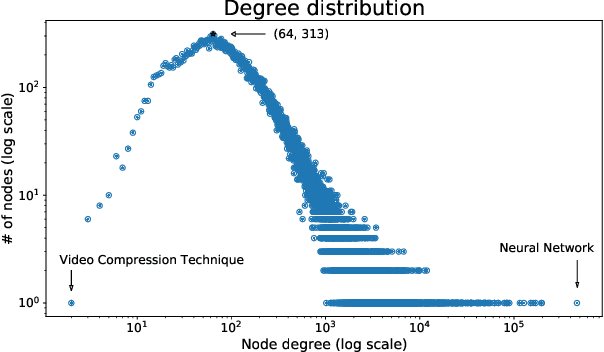
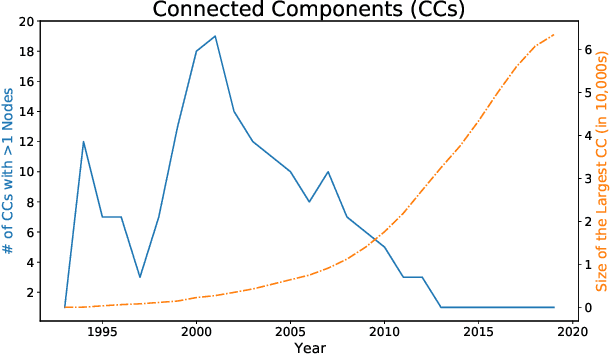
A tool that could suggest new personalized research directions and ideas by taking insights from the scientific literature could significantly accelerate the progress of science. A field that might benefit from such an approach is artificial intelligence (AI) research, where the number of scientific publications has been growing exponentially over the last years, making it challenging for human researchers to keep track of the progress. Here, we use AI techniques to predict the future research directions of AI itself. We develop a new graph-based benchmark based on real-world data -- the Science4Cast benchmark, which aims to predict the future state of an evolving semantic network of AI. For that, we use more than 100,000 research papers and build up a knowledge network with more than 64,000 concept nodes. We then present ten diverse methods to tackle this task, ranging from pure statistical to pure learning methods. Surprisingly, the most powerful methods use a carefully curated set of network features, rather than an end-to-end AI approach. It indicates a great potential that can be unleashed for purely ML approaches without human knowledge. Ultimately, better predictions of new future research directions will be a crucial component of more advanced research suggestion tools.
Seeing Glass: Joint Point Cloud and Depth Completion for Transparent Objects
Sep 30, 2021
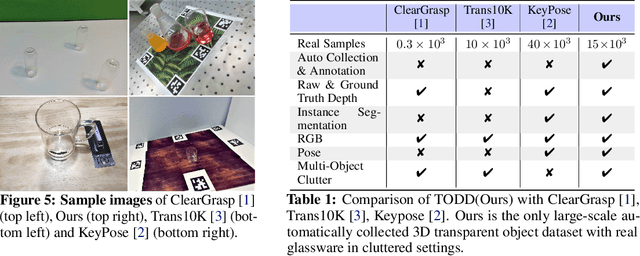
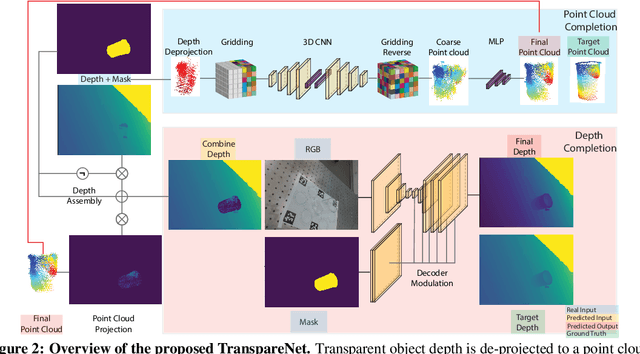
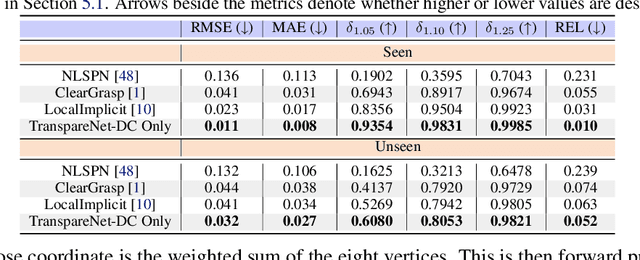
The basis of many object manipulation algorithms is RGB-D input. Yet, commodity RGB-D sensors can only provide distorted depth maps for a wide range of transparent objects due light refraction and absorption. To tackle the perception challenges posed by transparent objects, we propose TranspareNet, a joint point cloud and depth completion method, with the ability to complete the depth of transparent objects in cluttered and complex scenes, even with partially filled fluid contents within the vessels. To address the shortcomings of existing transparent object data collection schemes in literature, we also propose an automated dataset creation workflow that consists of robot-controlled image collection and vision-based automatic annotation. Through this automated workflow, we created Toronto Transparent Objects Depth Dataset (TODD), which consists of nearly 15000 RGB-D images. Our experimental evaluation demonstrates that TranspareNet outperforms existing state-of-the-art depth completion methods on multiple datasets, including ClearGrasp, and that it also handles cluttered scenes when trained on TODD. Code and dataset will be released at https://www.pair.toronto.edu/TranspareNet/
Predicting 3D shapes, masks, and properties of materials, liquids, and objects inside transparent containers, using the TransProteus CGI dataset
Sep 15, 2021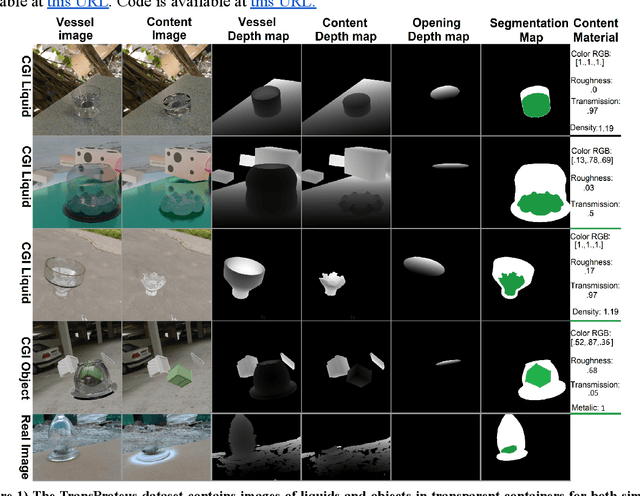
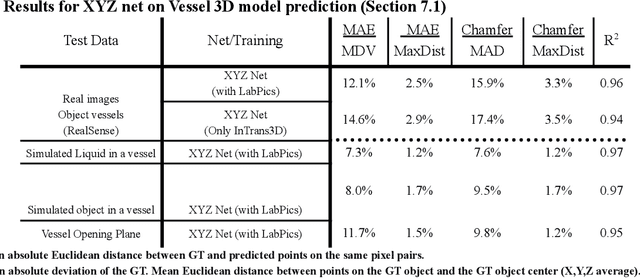
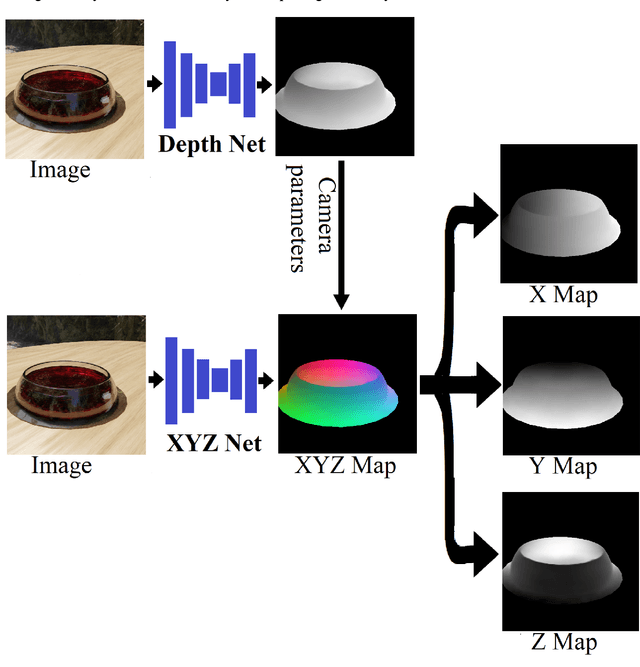
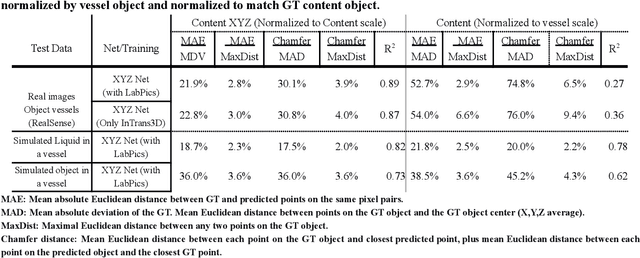
We present TransProteus, a dataset, and methods for predicting the 3D structure, masks, and properties of materials, liquids, and objects inside transparent vessels from a single image without prior knowledge of the image source and camera parameters. Manipulating materials in transparent containers is essential in many fields and depends heavily on vision. This work supplies a new procedurally generated dataset consisting of 50k images of liquids and solid objects inside transparent containers. The image annotations include 3D models, material properties (color/transparency/roughness...), and segmentation masks for the vessel and its content. The synthetic (CGI) part of the dataset was procedurally generated using 13k different objects, 500 different environments (HDRI), and 1450 material textures (PBR) combined with simulated liquids and procedurally generated vessels. In addition, we supply 104 real-world images of objects inside transparent vessels with depth maps of both the vessel and its content. We propose a camera agnostic method that predicts 3D models from an image as an XYZ map. This allows the trained net to predict the 3D model as a map with XYZ coordinates per pixel without prior knowledge of the image source. To calculate the training loss, we use the distance between pairs of points inside the 3D model instead of the absolute XYZ coordinates. This makes the loss function translation invariant. We use this to predict 3D models of vessels and their content from a single image. Finally, we demonstrate a net that uses a single image to predict the material properties of the vessel content and surface.
Computer vision for liquid samples in hospitals and medical labs using hierarchical image segmentation and relations prediction
May 04, 2021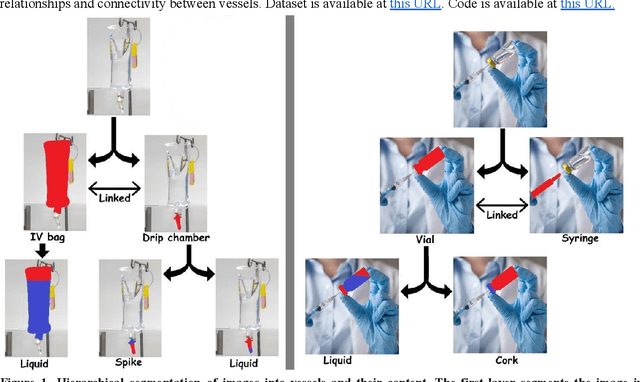
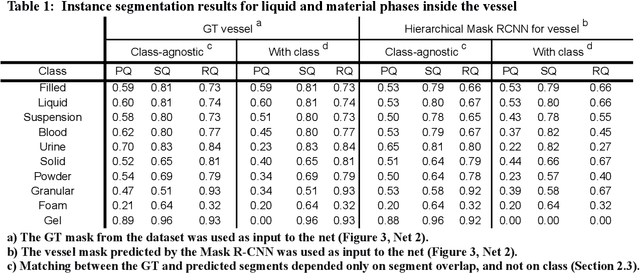
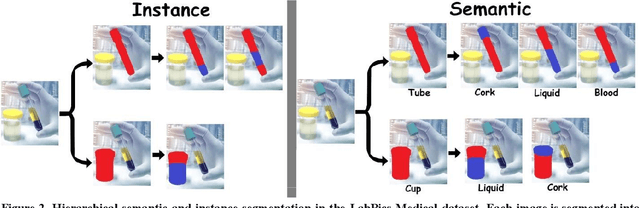
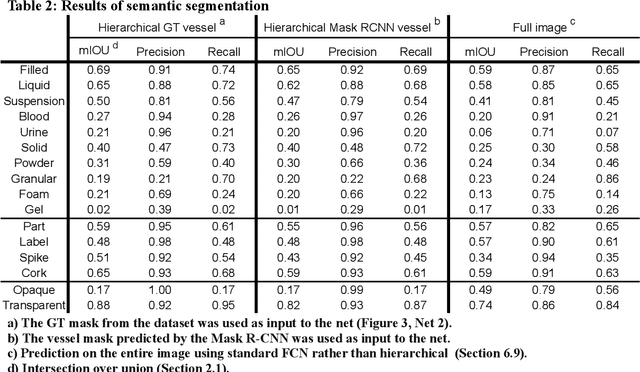
This work explores the use of computer vision for image segmentation and classification of medical fluid samples in transparent containers (for example, tubes, syringes, infusion bags). Handling fluids such as infusion fluids, blood, and urine samples is a significant part of the work carried out in medical labs and hospitals. The ability to accurately identify and segment the liquids and the vessels that contain them from images can help in automating such processes. Modern computer vision typically involves training deep neural nets on large datasets of annotated images. This work presents a new dataset containing 1,300 annotated images of medical samples involving vessels containing liquids and solid material. The images are annotated with the type of liquid (e.g., blood, urine), the phase of the material (e.g., liquid, solid, foam, suspension), the type of vessel (e.g., syringe, tube, cup, infusion bottle/bag), and the properties of the vessel (transparent, opaque). In addition, vessel parts such as corks, labels, spikes, and valves are annotated. Relations and hierarchies between vessels and materials are also annotated, such as which vessel contains which material or which vessels are linked or contain each other. Three neural networks are trained on the dataset: One network learns to detect vessels, a second net detects the materials and parts inside each vessel, and a third net identifies relationships and connectivity between vessels.
Deep Molecular Dreaming: Inverse machine learning for de-novo molecular design and interpretability with surjective representations
Dec 17, 2020
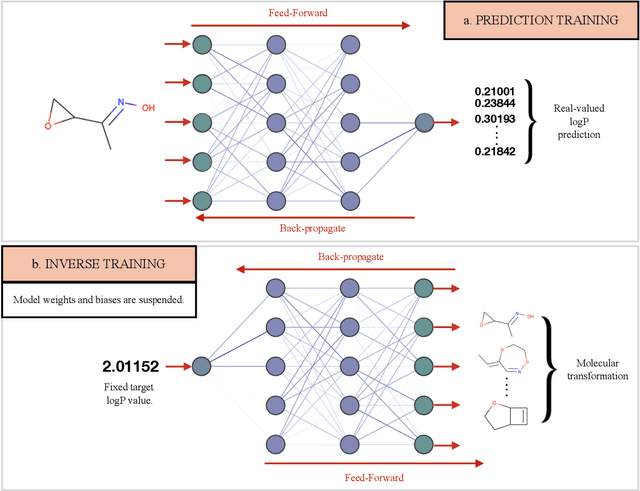

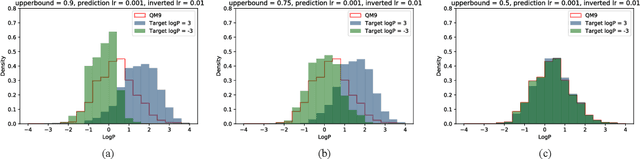
Computer-based de-novo design of functional molecules is one of the most prominent challenges in cheminformatics today. As a result, generative and evolutionary inverse designs from the field of artificial intelligence have emerged at a rapid pace, with aims to optimize molecules for a particular chemical property. These models 'indirectly' explore the chemical space; by learning latent spaces, policies, distributions or by applying mutations on populations of molecules. However, the recent development of the SELFIES string representation of molecules, a surjective alternative to SMILES, have made possible other potential techniques. Based on SELFIES, we therefore propose PASITHEA, a direct gradient-based molecule optimization that applies inceptionism techniques from computer vision. PASITHEA exploits the use of gradients by directly reversing the learning process of a neural network, which is trained to predict real-valued chemical properties. Effectively, this forms an inverse regression model, which is capable of generating molecular variants optimized for a certain property. Although our results are preliminary, we observe a shift in distribution of a chosen property during inverse-training, a clear indication of PASITHEA's viability. A striking property of inceptionism is that we can directly probe the model's understanding of the chemical space it was trained on. We expect that extending PASITHEA to larger datasets, molecules and more complex properties will lead to advances in the design of new functional molecules as well as the interpretation and explanation of machine learning models.