 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Agility and Adaptive Legged Locomotion via Curricular Hindsight Reinforcement Learning
Oct 24, 2023



Agile and adaptive maneuvers such as fall recovery, high-speed turning, and sprinting in the wild are challenging for legged systems. We propose a Curricular Hindsight Reinforcement Learning (CHRL) that learns an end-to-end tracking controller that achieves powerful agility and adaptation for the legged robot. The two key components are (I) a novel automatic curriculum strategy on task difficulty and (ii) a Hindsight Experience Replay strategy adapted to legged locomotion tasks. We demonstrated successful agile and adaptive locomotion on a real quadruped robot that performed fall recovery autonomously, coherent trotting, sustained outdoor speeds up to 3.45 m/s, and tuning speeds up to 3.2 rad/s. This system produces adaptive behaviours responding to changing situations and unexpected disturbances on natural terrains like grass and dirt.
Balancing Value Underestimation and Overestimation with Realistic Actor-Critic
Nov 10, 2021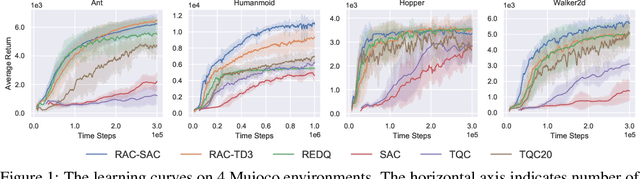

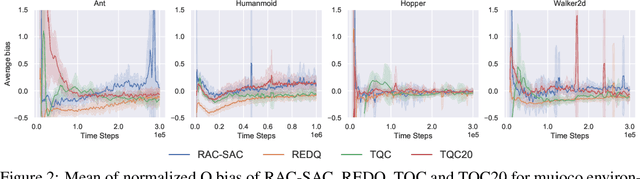
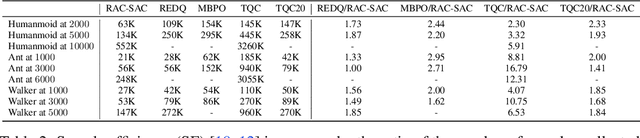
Model-free deep reinforcement learning (RL) has been successfully applied to challenging continuous control domains. However, poor sample efficiency prevents these methods from being widely used in real-world domains. We address this problem by proposing a novel model-free algorithm, Realistic Actor-Critic(RAC), which aims to solve trade-offs between value underestimation and overestimation by learning a policy family concerning various confidence-bounds of Q-function. We construct uncertainty punished Q-learning(UPQ), which uses uncertainty from the ensembling of multiple critics to control estimation bias of Q-function, making Q-functions smoothly shift from lower- to higher-confidence bounds. With the guide of these critics, RAC employs Universal Value Function Approximators (UVFA) to simultaneously learn many optimistic and pessimistic policies with the same neural network. Optimistic policies generate effective exploratory behaviors, while pessimistic policies reduce the risk of value overestimation to ensure stable updates of policies and Q-functions. The proposed method can be incorporated with any off-policy actor-critic RL algorithms. Our method achieve 10x sample efficiency and 25\% performance improvement compared to SAC on the most challenging Humanoid environment, obtaining the episode reward $11107\pm 475$ at $10^6$ time steps. All the source codes are available at https://github.com/ihuhuhu/RAC.