 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSnippet-based Conversational Recommender System
Nov 09, 2024



Conversational Recommender Systems (CRS) engage users in interactive dialogues to gather preferences and provide personalized recommendations. Traditionally, CRS rely on pre-defined attributes or expensive, domain-specific annotated datasets to guide conversations, which limits flexibility and adaptability across domains. In this work, we introduce SnipRec, a novel CRS that enhances dialogues and recommendations by extracting diverse expressions and preferences from user-generated content (UGC) like customer reviews. Using large language models, SnipRec maps user responses and UGC to concise snippets, which are used to generate clarification questions and retrieve relevant items. Our approach eliminates the need for domain-specific training, making it adaptable to new domains and effective without prior knowledge of user preferences. Extensive experiments on the Yelp dataset demonstrate the effectiveness of snippet-based representations against document and sentence-based representations. Additionally, SnipRec is able to improve Hits@10 by 0.25 over the course of five conversational turns, underscoring the efficiency of SnipRec in capturing user preferences through multi-turn conversations.
Natural Language Processing for Human Resources: A Survey
Oct 21, 2024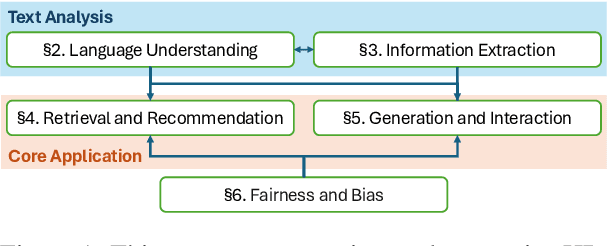
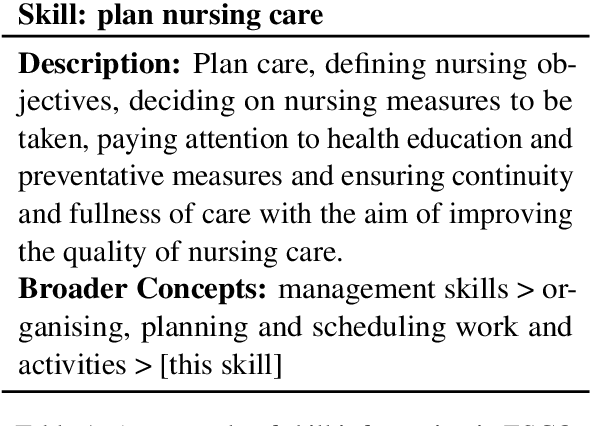

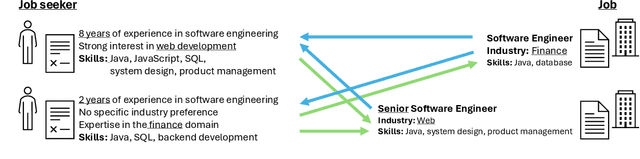
The domain of human resources (HR) includes a broad spectrum of tasks related to natural language processing (NLP) techniques. Recent breakthroughs in NLP have generated significant interest in its industrial applications in this domain and potentially alleviate challenges such as the difficulty of resource acquisition and the complexity of problems. At the same time, the HR domain can also present unique challenges that drive state-of-the-art in NLP research. To support this, we provide NLP researchers and practitioners with an overview of key HR tasks from an NLP perspective, illustrating how specific sub-tasks (e.g., skill extraction) contribute to broader objectives (e.g., job matching). Through this survey, we identify opportunities in NLP for HR and suggest directions for future exploration.
Contextualized Word Vector-based Methods for Discovering Semantic Differences with No Training nor Word Alignment
May 19, 2023



In this paper, we propose methods for discovering semantic differences in words appearing in two corpora based on the norms of contextualized word vectors. The key idea is that the coverage of meanings is reflected in the norm of its mean word vector. The proposed methods do not require the assumptions concerning words and corpora for comparison that the previous methods do. All they require are to compute the mean vector of contextualized word vectors and its norm for each word type. Nevertheless, they are (i) robust for the skew in corpus size; (ii) capable of detecting semantic differences in infrequent words; and (iii) effective in pinpointing word instances that have a meaning missing in one of the two corpora for comparison. We show these advantages for native and non-native English corpora and also for historical corpora.
Construction Grammar Provides Unique Insight into Neural Language Models
Feb 04, 2023



Construction Grammar (CxG) has recently been used as the basis for probing studies that have investigated the performance of large pretrained language models (PLMs) with respect to the structure and meaning of constructions. In this position paper, we make suggestions for the continuation and augmentation of this line of research. We look at probing methodology that was not designed with CxG in mind, as well as probing methodology that was designed for specific constructions. We analyse selected previous work in detail, and provide our view of the most important challenges and research questions that this promising new field faces.
Neural Polysynthetic Language Modelling
May 13, 2020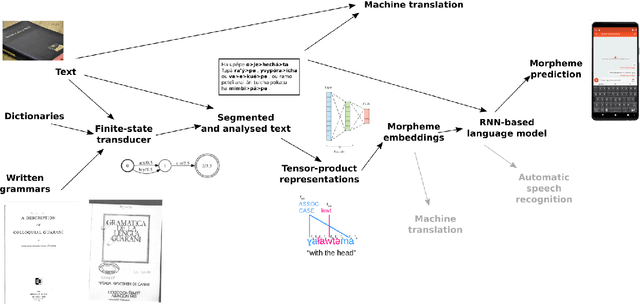

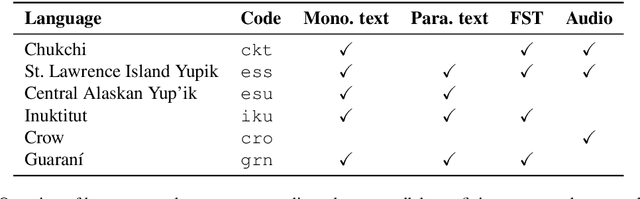
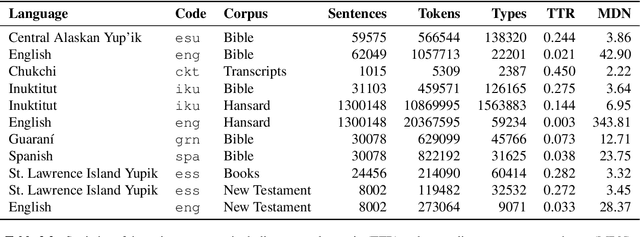
Research in natural language processing commonly assumes that approaches that work well for English and and other widely-used languages are "language agnostic". In high-resource languages, especially those that are analytic, a common approach is to treat morphologically-distinct variants of a common root as completely independent word types. This assumes, that there are limited morphological inflections per root, and that the majority will appear in a large enough corpus, so that the model can adequately learn statistics about each form. Approaches like stemming, lemmatization, or subword segmentation are often used when either of those assumptions do not hold, particularly in the case of synthetic languages like Spanish or Russian that have more inflection than English. In the literature, languages like Finnish or Turkish are held up as extreme examples of complexity that challenge common modelling assumptions. Yet, when considering all of the world's languages, Finnish and Turkish are closer to the average case. When we consider polysynthetic languages (those at the extreme of morphological complexity), approaches like stemming, lemmatization, or subword modelling may not suffice. These languages have very high numbers of hapax legomena, showing the need for appropriate morphological handling of words, without which it is not possible for a model to capture enough word statistics. We examine the current state-of-the-art in language modelling, machine translation, and text prediction for four polysynthetic languages: Guaran\'i, St. Lawrence Island Yupik, Central Alaskan Yupik, and Inuktitut. We then propose a novel framework for language modelling that combines knowledge representations from finite-state morphological analyzers with Tensor Product Representations in order to enable neural language models capable of handling the full range of typologically variant languages.
The ARIEL-CMU Systems for LoReHLT18
Feb 24, 2019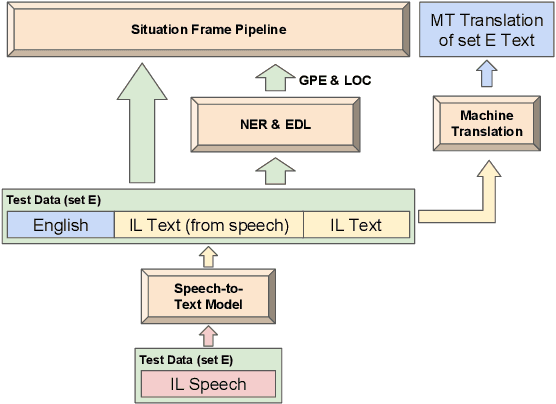
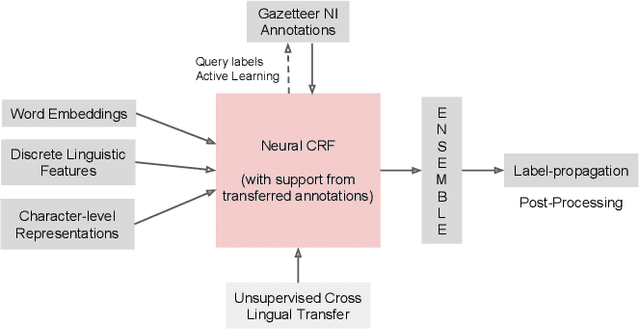
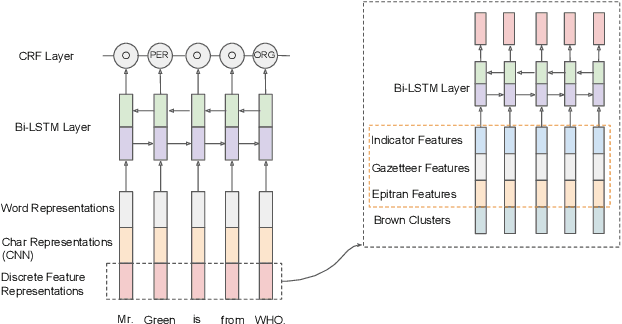
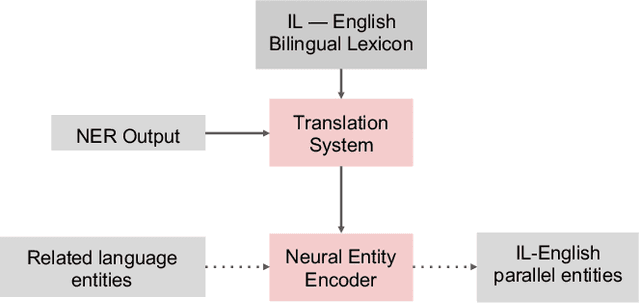
This paper describes the ARIEL-CMU submissions to the Low Resource Human Language Technologies (LoReHLT) 2018 evaluations for the tasks Machine Translation (MT), Entity Discovery and Linking (EDL), and detection of Situation Frames in Text and Speech (SF Text and Speech).
Unsupervised Cross-lingual Transfer of Word Embedding Spaces
Sep 10, 2018
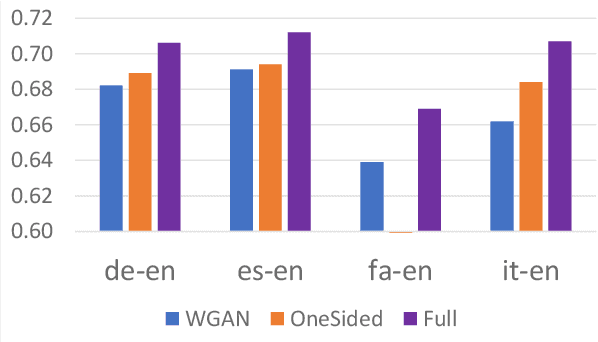
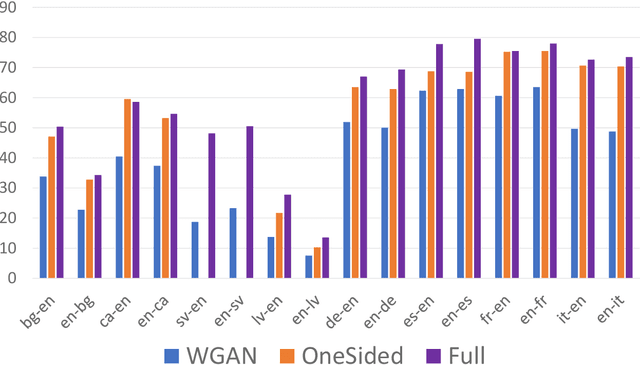
Cross-lingual transfer of word embeddings aims to establish the semantic mappings among words in different languages by learning the transformation functions over the corresponding word embedding spaces. Successfully solving this problem would benefit many downstream tasks such as to translate text classification models from resource-rich languages (e.g. English) to low-resource languages. Supervised methods for this problem rely on the availability of cross-lingual supervision, either using parallel corpora or bilingual lexicons as the labeled data for training, which may not be available for many low resource languages. This paper proposes an unsupervised learning approach that does not require any cross-lingual labeled data. Given two monolingual word embedding spaces for any language pair, our algorithm optimizes the transformation functions in both directions simultaneously based on distributional matching as well as minimizing the back-translation losses. We use a neural network implementation to calculate the Sinkhorn distance, a well-defined distributional similarity measure, and optimize our objective through back-propagation. Our evaluation on benchmark datasets for bilingual lexicon induction and cross-lingual word similarity prediction shows stronger or competitive performance of the proposed method compared to other state-of-the-art supervised and unsupervised baseline methods over many language pairs.