 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Polysynthetic Language Modelling
May 13, 2020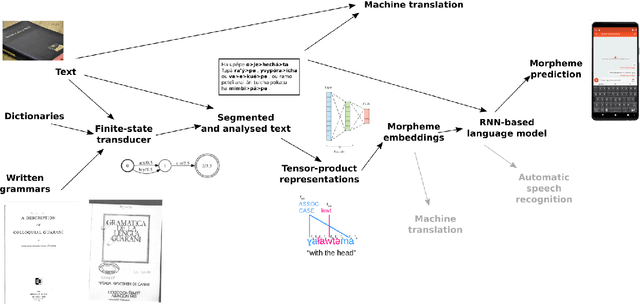

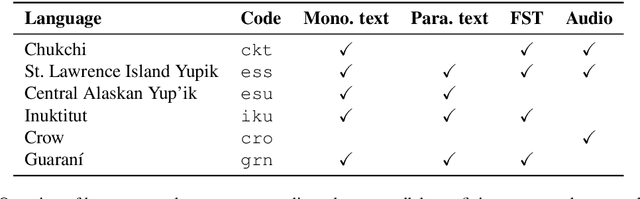
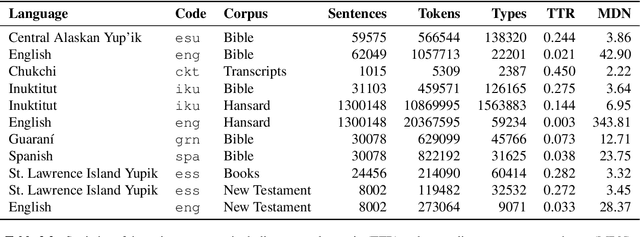
Research in natural language processing commonly assumes that approaches that work well for English and and other widely-used languages are "language agnostic". In high-resource languages, especially those that are analytic, a common approach is to treat morphologically-distinct variants of a common root as completely independent word types. This assumes, that there are limited morphological inflections per root, and that the majority will appear in a large enough corpus, so that the model can adequately learn statistics about each form. Approaches like stemming, lemmatization, or subword segmentation are often used when either of those assumptions do not hold, particularly in the case of synthetic languages like Spanish or Russian that have more inflection than English. In the literature, languages like Finnish or Turkish are held up as extreme examples of complexity that challenge common modelling assumptions. Yet, when considering all of the world's languages, Finnish and Turkish are closer to the average case. When we consider polysynthetic languages (those at the extreme of morphological complexity), approaches like stemming, lemmatization, or subword modelling may not suffice. These languages have very high numbers of hapax legomena, showing the need for appropriate morphological handling of words, without which it is not possible for a model to capture enough word statistics. We examine the current state-of-the-art in language modelling, machine translation, and text prediction for four polysynthetic languages: Guaran\'i, St. Lawrence Island Yupik, Central Alaskan Yupik, and Inuktitut. We then propose a novel framework for language modelling that combines knowledge representations from finite-state morphological analyzers with Tensor Product Representations in order to enable neural language models capable of handling the full range of typologically variant languages.
The ARIEL-CMU Systems for LoReHLT18
Feb 24, 2019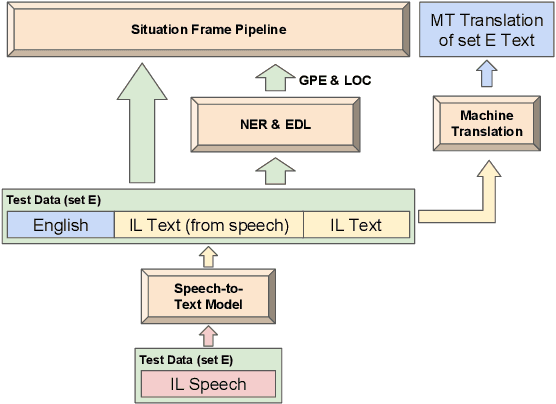
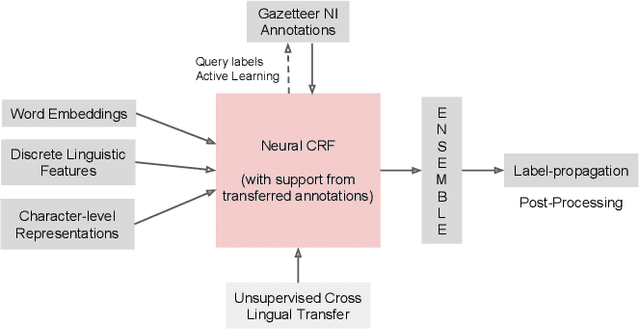
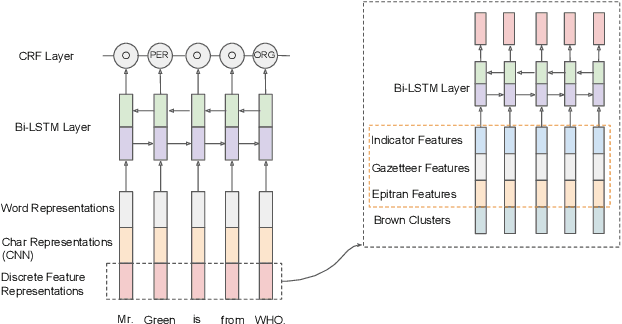
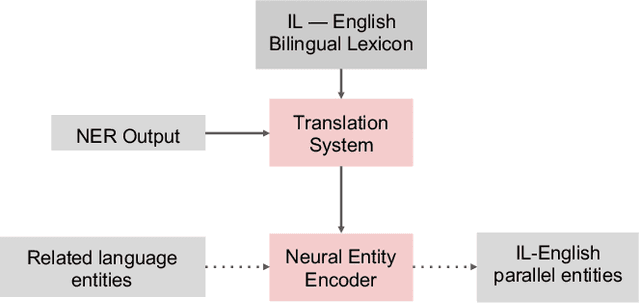
This paper describes the ARIEL-CMU submissions to the Low Resource Human Language Technologies (LoReHLT) 2018 evaluations for the tasks Machine Translation (MT), Entity Discovery and Linking (EDL), and detection of Situation Frames in Text and Speech (SF Text and Speech).
Efficient Dependency-Guided Named Entity Recognition
Oct 22, 2018

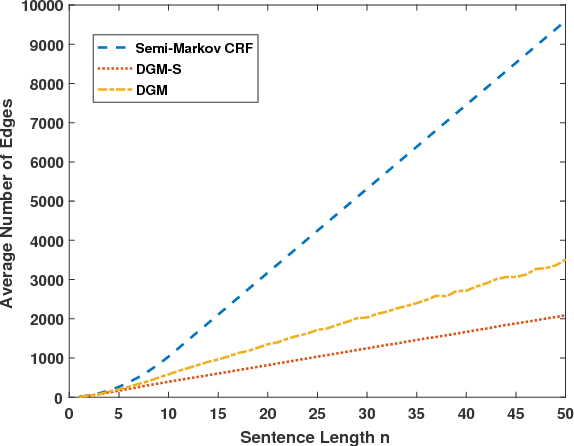
Named entity recognition (NER), which focuses on the extraction of semantically meaningful named entities and their semantic classes from text, serves as an indispensable component for several down-stream natural language processing (NLP) tasks such as relation extraction and event extraction. Dependency trees, on the other hand, also convey crucial semantic-level information. It has been shown previously that such information can be used to improve the performance of NER (Sasano and Kurohashi 2008, Ling and Weld 2012). In this work, we investigate on how to better utilize the structured information conveyed by dependency trees to improve the performance of NER. Specifically, unlike existing approaches which only exploit dependency information for designing local features, we show that certain global structured information of the dependency trees can be exploited when building NER models where such information can provide guided learning and inference. Through extensive experiments, we show that our proposed novel dependency-guided NER model performs competitively with models based on conventional semi-Markov conditional random fields, while requiring significantly less running time.
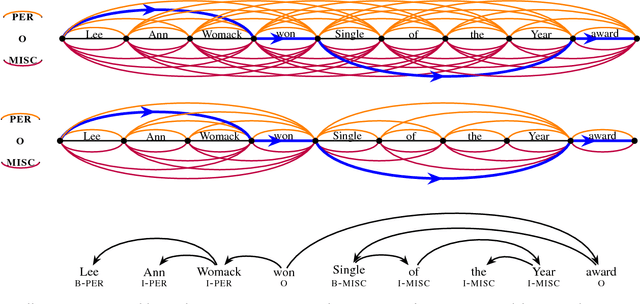
Labeling Gaps Between Words: Recognizing Overlapping Mentions with Mention Separators
Oct 22, 2018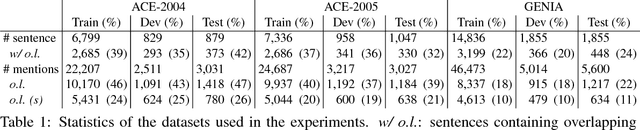

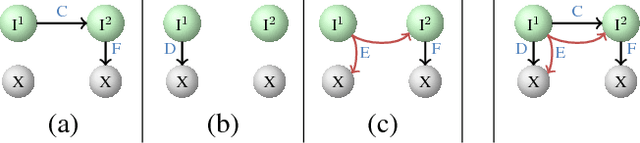
In this paper, we propose a new model that is capable of recognizing overlapping mentions. We introduce a novel notion of mention separators that can be effectively used to capture how mentions overlap with one another. On top of a novel multigraph representation that we introduce, we show that efficient and exact inference can still be performed. We present some theoretical analysis on the differences between our model and a recently proposed model for recognizing overlapping mentions, and discuss the possible implications of the differences. Through extensive empirical analysis on standard datasets, we demonstrate the effectiveness of our approach.
Learning to Recognize Discontiguous Entities
Oct 19, 2018

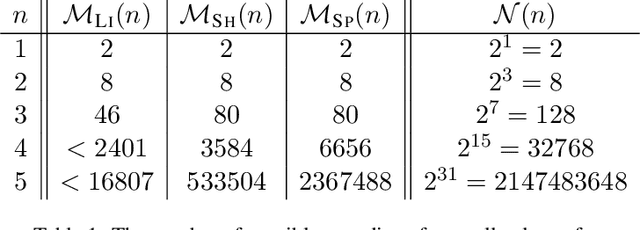

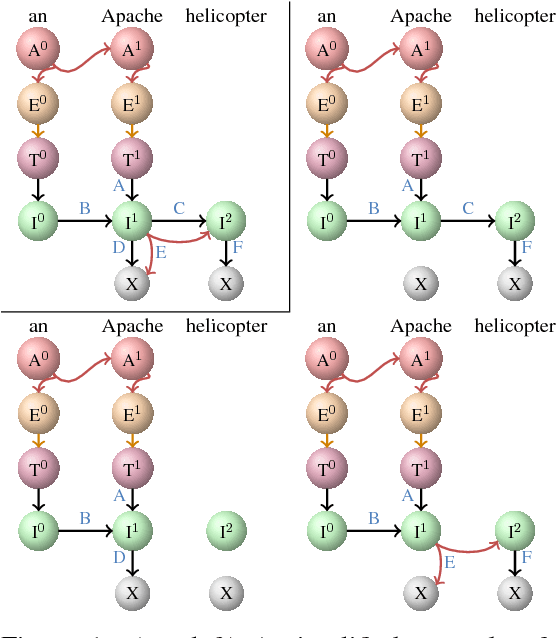
This paper focuses on the study of recognizing discontiguous entities. Motivated by a previous work, we propose to use a novel hypergraph representation to jointly encode discontiguous entities of unbounded length, which can overlap with one another. To compare with existing approaches, we first formally introduce the notion of model ambiguity, which defines the difficulty level of interpreting the outputs of a model, and then formally analyze the theoretical advantages of our model over previous existing approaches based on linear-chain CRFs. Our empirical results also show that our model is able to achieve significantly better results when evaluated on standard data with many discontiguous entities.
* 9+1 pages + 8 pages supplementary, published in EMNLP 2016
Weak Semi-Markov CRFs for NP Chunking in Informal Text
Oct 19, 2018


This paper introduces a new annotated corpus based on an existing informal text corpus: the NUS SMS Corpus (Chen and Kan, 2013). The new corpus includes 76,490 noun phrases from 26,500 SMS messages, annotated by university students. We then explored several graphical models, including a novel variant of the semi-Markov conditional random fields (semi-CRF) for the task of noun phrase chunking. We demonstrated through empirical evaluations on the new dataset that the new variant yielded similar accuracy but ran in significantly lower running time compared to the conventional semi-CRF.
* 5+1 pages, published in NAACL 2016