 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRefract ICL: Rethinking Example Selection in the Era of Million-Token Models
Jun 14, 2025The emergence of long-context large language models (LLMs) has enabled the use of hundreds, or even thousands, of demonstrations for in-context learning (ICL) - a previously impractical regime. This paper investigates whether traditional ICL selection strategies, which balance the similarity of ICL examples to the test input (using a text retriever) with diversity within the ICL set, remain effective when utilizing a large number of demonstrations. Our experiments demonstrate that, while longer contexts can accommodate more examples, simply increasing the number of demonstrations does not guarantee improved performance. Smart ICL selection remains crucial, even with thousands of demonstrations. To further enhance ICL in this setting, we introduce Refract ICL, a novel ICL selection algorithm specifically designed to focus LLM attention on challenging examples by strategically repeating them within the context and incorporating zero-shot predictions as error signals. Our results show that Refract ICL significantly improves the performance of extremely long-context models such as Gemini 1.5 Pro, particularly on tasks with a smaller number of output classes.
It's All Relative! -- A Synthetic Query Generation Approach for Improving Zero-Shot Relevance Prediction
Nov 14, 2023



Recent developments in large language models (LLMs) have shown promise in their ability to generate synthetic query-document pairs by prompting with as few as 8 demonstrations. This has enabled building better IR models, especially for tasks with no training data readily available. Typically, such synthetic query generation (QGen) approaches condition on an input context (e.g. a text document) and generate a query relevant to that context, or condition the QGen model additionally on the relevance label (e.g. relevant vs irrelevant) to generate queries across relevance buckets. However, we find that such QGen approaches are sub-optimal as they require the model to reason about the desired label and the input from a handful of examples. In this work, we propose to reduce this burden of LLMs by generating queries simultaneously for different labels. We hypothesize that instead of asking the model to generate, say, an irrelevant query given an input context, asking the model to generate an irrelevant query relative to a relevant query is a much simpler task setup for the model to reason about. Extensive experimentation across seven IR datasets shows that synthetic queries generated in such a fashion translates to a better downstream performance, suggesting that the generated queries are indeed of higher quality.
Teacher Perception of Automatically Extracted Grammar Concepts for L2 Language Learning
Oct 27, 2023



One of the challenges in language teaching is how best to organize rules regarding syntax, semantics, or phonology in a meaningful manner. This not only requires content creators to have pedagogical skills, but also have that language's deep understanding. While comprehensive materials to develop such curricula are available in English and some broadly spoken languages, for many other languages, teachers need to manually create them in response to their students' needs. This is challenging because i) it requires that such experts be accessible and have the necessary resources, and ii) describing all the intricacies of a language is time-consuming and prone to omission. In this work, we aim to facilitate this process by automatically discovering and visualizing grammar descriptions. We extract descriptions from a natural text corpus that answer questions about morphosyntax (learning of word order, agreement, case marking, or word formation) and semantics (learning of vocabulary). We apply this method for teaching two Indian languages, Kannada and Marathi, which, unlike English, do not have well-developed resources for second language learning. To assess the perceived utility of the extracted material, we enlist the help of language educators from schools in North America to perform a manual evaluation, who find the materials have potential to be used for their lesson preparation and learner evaluation.
Crossing the Threshold: Idiomatic Machine Translation through Retrieval Augmentation and Loss Weighting
Oct 20, 2023



Idioms are common in everyday language, but often pose a challenge to translators because their meanings do not follow from the meanings of their parts. Despite significant advances, machine translation systems still struggle to translate idiomatic expressions. We provide a simple characterization of idiomatic translation and related issues. This allows us to conduct a synthetic experiment revealing a tipping point at which transformer-based machine translation models correctly default to idiomatic translations. To expand multilingual resources, we compile a dataset of ~4k natural sentences containing idiomatic expressions in French, Finnish, and Japanese. To improve translation of natural idioms, we introduce two straightforward yet effective techniques: the strategic upweighting of training loss on potentially idiomatic sentences, and using retrieval-augmented models. This not only improves the accuracy of a strong pretrained MT model on idiomatic sentences by up to 13% in absolute accuracy, but also holds potential benefits for non-idiomatic sentences.
Ambiguity-Aware In-Context Learning with Large Language Models
Sep 14, 2023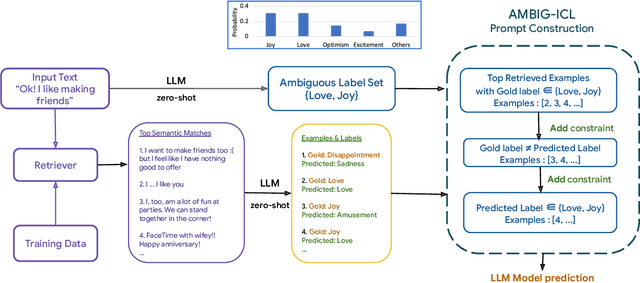
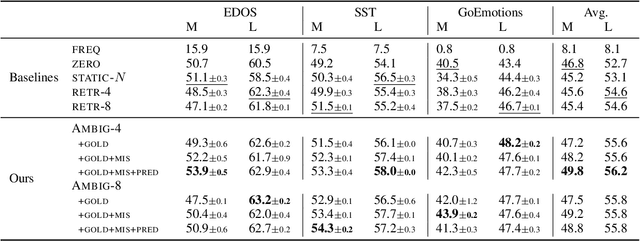
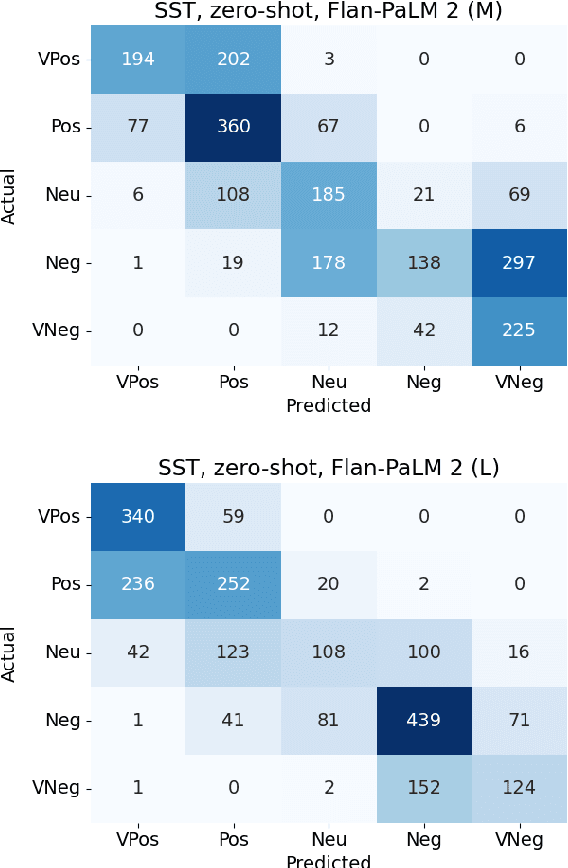
In-context learning (ICL) i.e. showing LLMs only a few task-specific demonstrations has led to downstream gains with no task-specific fine-tuning required. However, LLMs are sensitive to the choice of prompts, and therefore a crucial research question is how to select good demonstrations for ICL. One effective strategy is leveraging semantic similarity between the ICL demonstrations and test inputs by using a text retriever, which however is sub-optimal as that does not consider the LLM's existing knowledge about that task. From prior work (Min et al., 2022), we already know that labels paired with the demonstrations bias the model predictions. This leads us to our hypothesis whether considering LLM's existing knowledge about the task, especially with respect to the output label space can help in a better demonstration selection strategy. Through extensive experimentation on three text classification tasks, we find that it is beneficial to not only choose semantically similar ICL demonstrations but also to choose those demonstrations that help resolve the inherent label ambiguity surrounding the test example. Interestingly, we find that including demonstrations that the LLM previously mis-classified and also fall on the test example's decision boundary, brings the most performance gain.
Exploring the Viability of Synthetic Query Generation for Relevance Prediction
May 19, 2023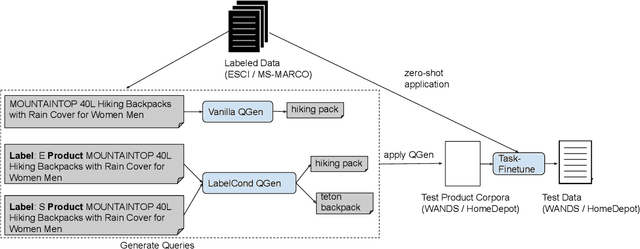
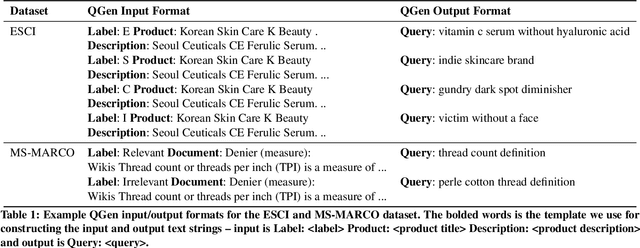

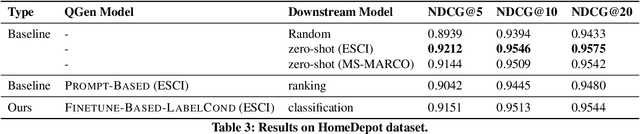
Query-document relevance prediction is a critical problem in Information Retrieval systems. This problem has increasingly been tackled using (pretrained) transformer-based models which are finetuned using large collections of labeled data. However, in specialized domains such as e-commerce and healthcare, the viability of this approach is limited by the dearth of large in-domain data. To address this paucity, recent methods leverage these powerful models to generate high-quality task and domain-specific synthetic data. Prior work has largely explored synthetic data generation or query generation (QGen) for Question-Answering (QA) and binary (yes/no) relevance prediction, where for instance, the QGen models are given a document, and trained to generate a query relevant to that document. However in many problems, we have a more fine-grained notion of relevance than a simple yes/no label. Thus, in this work, we conduct a detailed study into how QGen approaches can be leveraged for nuanced relevance prediction. We demonstrate that -- contrary to claims from prior works -- current QGen approaches fall short of the more conventional cross-domain transfer-learning approaches. Via empirical studies spanning 3 public e-commerce benchmarks, we identify new shortcomings of existing QGen approaches -- including their inability to distinguish between different grades of relevance. To address this, we introduce label-conditioned QGen models which incorporates knowledge about the different relevance. While our experiments demonstrate that these modifications help improve performance of QGen techniques, we also find that QGen approaches struggle to capture the full nuance of the relevance label space and as a result the generated queries are not faithful to the desired relevance label.
Salient Span Masking for Temporal Understanding
Mar 22, 2023



Salient Span Masking (SSM) has shown itself to be an effective strategy to improve closed-book question answering performance. SSM extends general masked language model pretraining by creating additional unsupervised training sentences that mask a single entity or date span, thus oversampling factual information. Despite the success of this paradigm, the span types and sampling strategies are relatively arbitrary and not widely studied for other tasks. Thus, we investigate SSM from the perspective of temporal tasks, where learning a good representation of various temporal expressions is important. To that end, we introduce Temporal Span Masking (TSM) intermediate training. First, we find that SSM alone improves the downstream performance on three temporal tasks by an avg. +5.8 points. Further, we are able to achieve additional improvements (avg. +0.29 points) by adding the TSM task. These comprise the new best reported results on the targeted tasks. Our analysis suggests that the effectiveness of SSM stems from the sentences chosen in the training data rather than the mask choice: sentences with entities frequently also contain temporal expressions. Nonetheless, the additional targeted spans of TSM can still improve performance, especially in a zero-shot context.
AUTOLEX: An Automatic Framework for Linguistic Exploration
Mar 25, 2022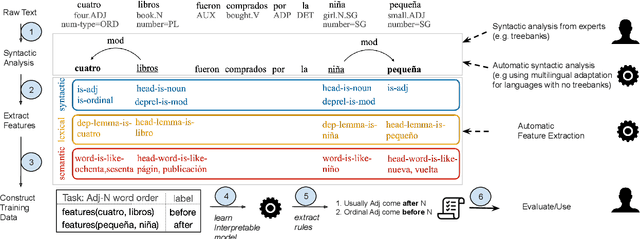
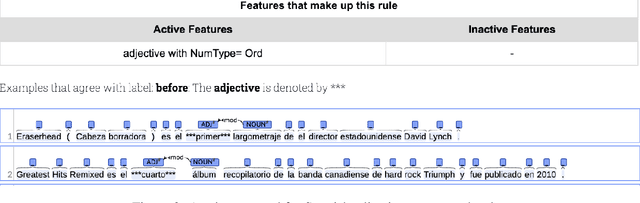
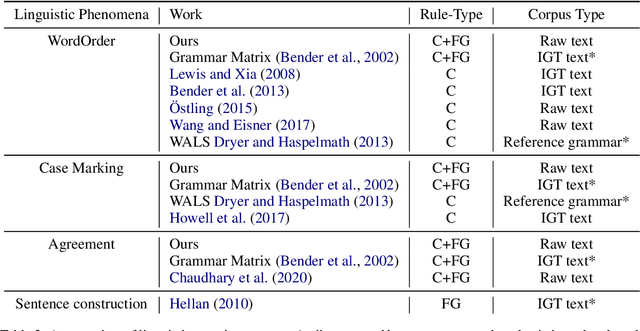
Each language has its own complex systems of word, phrase, and sentence construction, the guiding principles of which are often summarized in grammar descriptions for the consumption of linguists or language learners. However, manual creation of such descriptions is a fraught process, as creating descriptions which describe the language in "its own terms" without bias or error requires both a deep understanding of the language at hand and linguistics as a whole. We propose an automatic framework AutoLEX that aims to ease linguists' discovery and extraction of concise descriptions of linguistic phenomena. Specifically, we apply this framework to extract descriptions for three phenomena: morphological agreement, case marking, and word order, across several languages. We evaluate the descriptions with the help of language experts and propose a method for automated evaluation when human evaluation is infeasible.
When is Wall a Pared and when a Muro? -- Extracting Rules Governing Lexical Selection
Sep 13, 2021
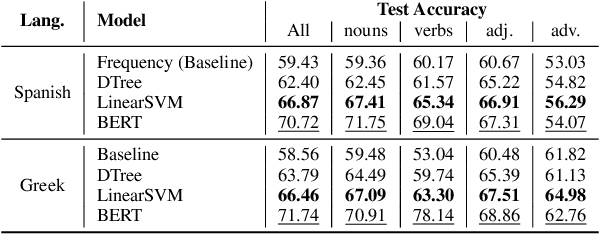
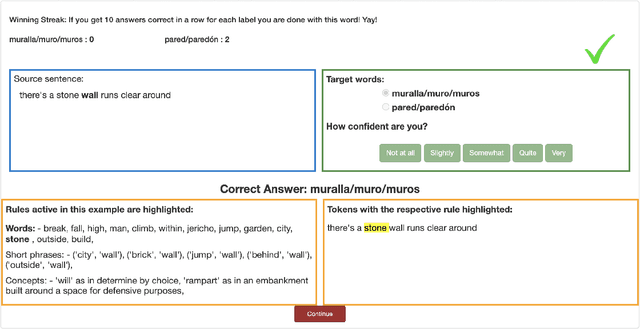

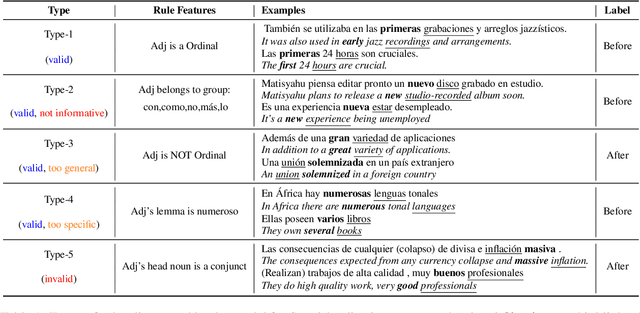
Learning fine-grained distinctions between vocabulary items is a key challenge in learning a new language. For example, the noun "wall" has different lexical manifestations in Spanish -- "pared" refers to an indoor wall while "muro" refers to an outside wall. However, this variety of lexical distinction may not be obvious to non-native learners unless the distinction is explained in such a way. In this work, we present a method for automatically identifying fine-grained lexical distinctions, and extracting concise descriptions explaining these distinctions in a human- and machine-readable format. We confirm the quality of these extracted descriptions in a language learning setup for two languages, Spanish and Greek, where we use them to teach non-native speakers when to translate a given ambiguous word into its different possible translations. Code and data are publicly released here (https://github.com/Aditi138/LexSelection)
Do Context-Aware Translation Models Pay the Right Attention?
May 21, 2021

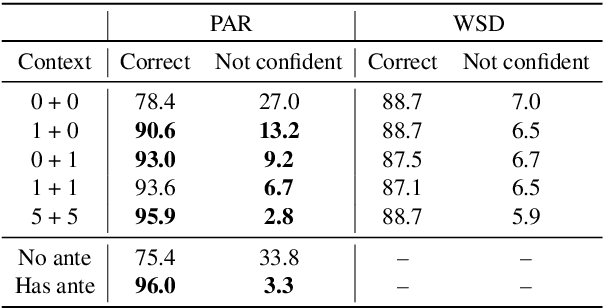
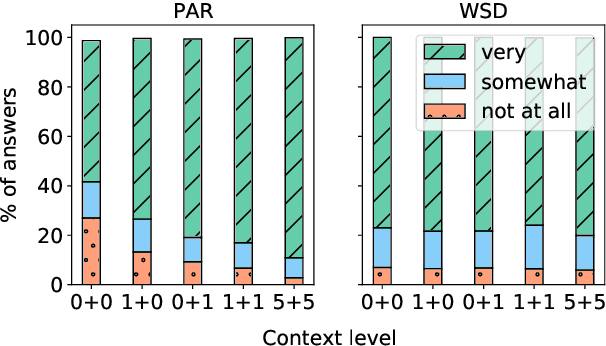
Context-aware machine translation models are designed to leverage contextual information, but often fail to do so. As a result, they inaccurately disambiguate pronouns and polysemous words that require context for resolution. In this paper, we ask several questions: What contexts do human translators use to resolve ambiguous words? Are models paying large amounts of attention to the same context? What if we explicitly train them to do so? To answer these questions, we introduce SCAT (Supporting Context for Ambiguous Translations), a new English-French dataset comprising supporting context words for 14K translations that professional translators found useful for pronoun disambiguation. Using SCAT, we perform an in-depth analysis of the context used to disambiguate, examining positional and lexical characteristics of the supporting words. Furthermore, we measure the degree of alignment between the model's attention scores and the supporting context from SCAT, and apply a guided attention strategy to encourage agreement between the two.