 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLong Chain-of-Thought Reasoning Across Languages
Aug 20, 2025

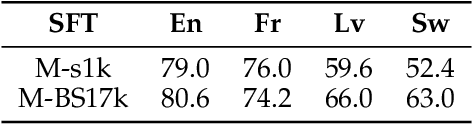

Scaling inference through long chains-of-thought (CoTs) has unlocked impressive reasoning capabilities in large language models (LLMs), yet the reasoning process remains almost exclusively English-centric. We construct translated versions of two popular English reasoning datasets, fine-tune Qwen 2.5 (7B) and Qwen 3 (8B) models, and present a systematic study of long CoT generation across French, Japanese, Latvian, and Swahili. Our experiments reveal three key findings. First, the efficacy of using English as a pivot language varies by language: it provides no benefit for French, improves performance when used as the reasoning language for Japanese and Latvian, and proves insufficient for Swahili where both task comprehension and reasoning remain poor. Second, extensive multilingual pretraining in Qwen 3 narrows but does not eliminate the cross-lingual performance gap. A lightweight fine-tune using only 1k traces still improves performance by over 30\% in Swahili. Third, data quality versus scale trade-offs are language dependent: small, carefully curated datasets suffice for English and French, whereas larger but noisier corpora prove more effective for Swahili and Latvian. Together, these results clarify when and why long CoTs transfer across languages and provide translated datasets to foster equitable multilingual reasoning research.
Understanding In-context Learning of Addition via Activation Subspaces
May 08, 2025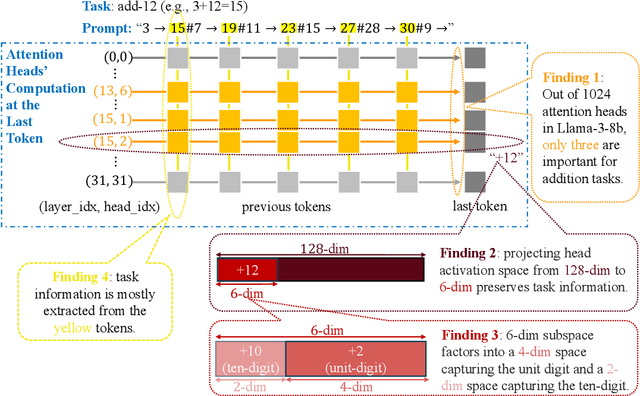
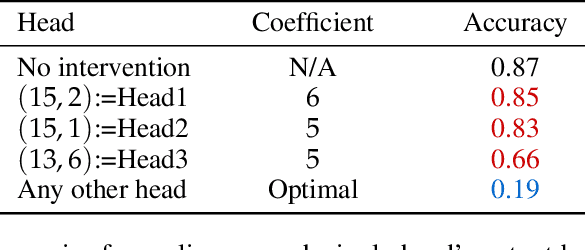
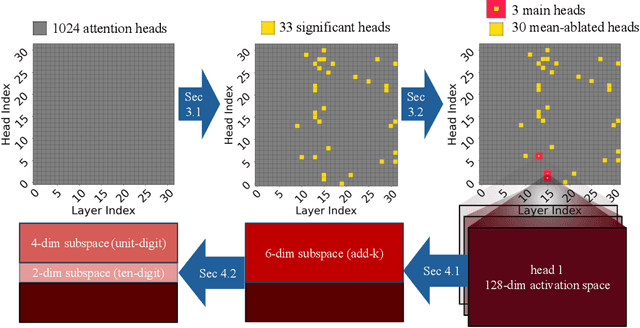
To perform in-context learning, language models must extract signals from individual few-shot examples, aggregate these into a learned prediction rule, and then apply this rule to new examples. How is this implemented in the forward pass of modern transformer models? To study this, we consider a structured family of few-shot learning tasks for which the true prediction rule is to add an integer $k$ to the input. We find that Llama-3-8B attains high accuracy on this task for a range of $k$, and localize its few-shot ability to just three attention heads via a novel optimization approach. We further show the extracted signals lie in a six-dimensional subspace, where four of the dimensions track the unit digit and the other two dimensions track overall magnitude. We finally examine how these heads extract information from individual few-shot examples, identifying a self-correction mechanism in which mistakes from earlier examples are suppressed by later examples. Our results demonstrate how tracking low-dimensional subspaces across a forward pass can provide insight into fine-grained computational structures.
Evaluating the Diversity and Quality of LLM Generated Content
Apr 16, 2025



Recent work suggests that preference-tuning techniques--including Reinforcement Learning from Human Preferences (RLHF) methods like PPO and GRPO, as well as alternatives like DPO--reduce diversity, creating a dilemma given that such models are widely deployed in applications requiring diverse outputs. To address this, we introduce a framework for measuring effective semantic diversity--diversity among outputs that meet quality thresholds--which better reflects the practical utility of large language models (LLMs). Using open-ended tasks that require no human intervention, we find counterintuitive results: although preference-tuned models--especially those trained via RL--exhibit reduced lexical and syntactic diversity, they produce greater effective semantic diversity than SFT or base models, not from increasing diversity among high-quality outputs, but from generating more high-quality outputs overall. We discover that preference tuning reduces syntactic diversity while preserving semantic diversity--revealing a distinction between diversity in form and diversity in content that traditional metrics often overlook. Our analysis further shows that smaller models are consistently more parameter-efficient at generating unique content within a fixed sampling budget, offering insights into the relationship between model scaling and diversity. These findings have important implications for applications that require diverse yet high-quality outputs, from creative assistance to synthetic data generation.
Which Attention Heads Matter for In-Context Learning?
Feb 19, 2025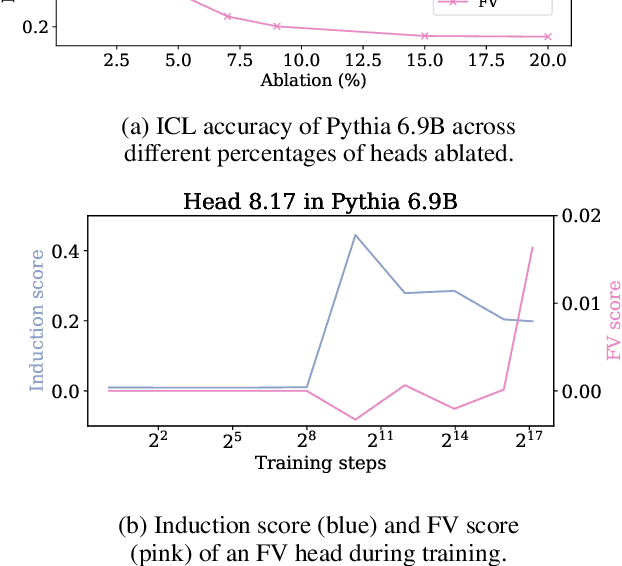


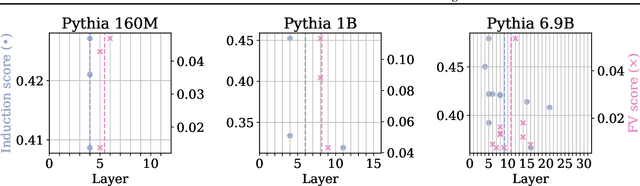
Large language models (LLMs) exhibit impressive in-context learning (ICL) capability, enabling them to perform new tasks using only a few demonstrations in the prompt. Two different mechanisms have been proposed to explain ICL: induction heads that find and copy relevant tokens, and function vector (FV) heads whose activations compute a latent encoding of the ICL task. To better understand which of the two distinct mechanisms drives ICL, we study and compare induction heads and FV heads in 12 language models. Through detailed ablations, we discover that few-shot ICL performance depends primarily on FV heads, especially in larger models. In addition, we uncover that FV and induction heads are connected: many FV heads start as induction heads during training before transitioning to the FV mechanism. This leads us to speculate that induction facilitates learning the more complex FV mechanism that ultimately drives ICL.
ASL STEM Wiki: Dataset and Benchmark for Interpreting STEM Articles
Nov 08, 2024Deaf and hard-of-hearing (DHH) students face significant barriers in accessing science, technology, engineering, and mathematics (STEM) education, notably due to the scarcity of STEM resources in signed languages. To help address this, we introduce ASL STEM Wiki: a parallel corpus of 254 Wikipedia articles on STEM topics in English, interpreted into over 300 hours of American Sign Language (ASL). ASL STEM Wiki is the first continuous signing dataset focused on STEM, facilitating the development of AI resources for STEM education in ASL. We identify several use cases of ASL STEM Wiki with human-centered applications. For example, because this dataset highlights the frequent use of fingerspelling for technical concepts, which inhibits DHH students' ability to learn, we develop models to identify fingerspelled words -- which can later be used to query for appropriate ASL signs to suggest to interpreters.
Using Language Models to Disambiguate Lexical Choices in Translation
Nov 08, 2024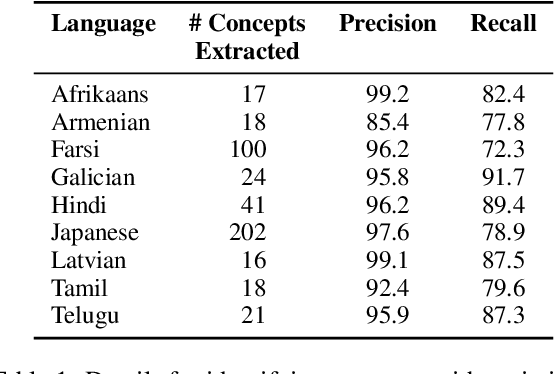
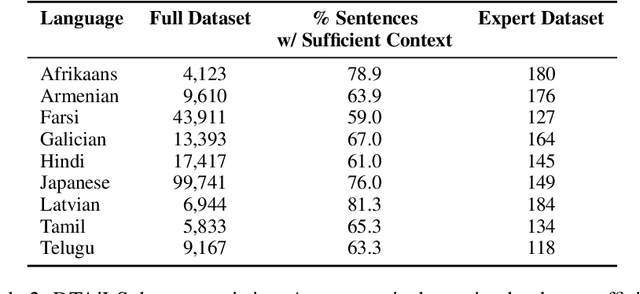
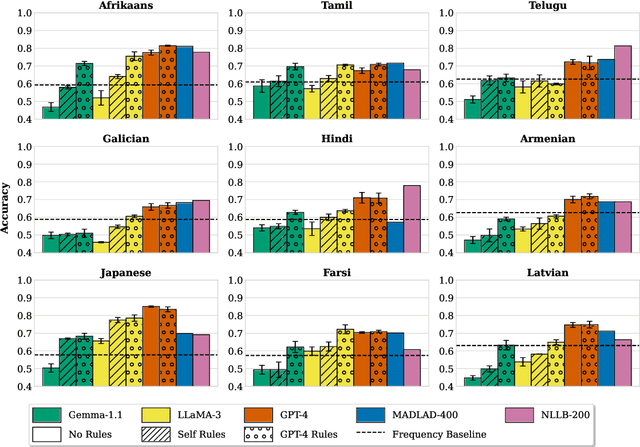
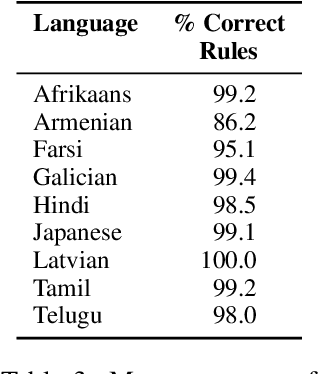
In translation, a concept represented by a single word in a source language can have multiple variations in a target language. The task of lexical selection requires using context to identify which variation is most appropriate for a source text. We work with native speakers of nine languages to create DTAiLS, a dataset of 1,377 sentence pairs that exhibit cross-lingual concept variation when translating from English. We evaluate recent LLMs and neural machine translation systems on DTAiLS, with the best-performing model, GPT-4, achieving from 67 to 85% accuracy across languages. Finally, we use language models to generate English rules describing target-language concept variations. Providing weaker models with high-quality lexical rules improves accuracy substantially, in some cases reaching or outperforming GPT-4.
American Sign Language Handshapes Reflect Pressures for Communicative Efficiency
Jun 06, 2024



Communicative efficiency is a prominent theory in linguistics and cognitive science. While numerous studies have shown how the pressure to save energy is reflected in the form of spoken languages, few have explored this phenomenon in signed languages. In this paper, we show how handshapes in American Sign Language (ASL) reflect these efficiency pressures and we present new evidence of communicative efficiency in the visual-gestural modality. We focus on handshapes that are used in both native ASL signs and signs borrowed from English to compare efficiency pressures from both ASL and English. First, we design new methodologies to quantify the articulatory effort required to produce handshapes as well as the perceptual effort needed to recognize them. Then, we compare correlations between communicative effort and usage statistics in ASL and English. Our findings reveal that frequent ASL handshapes are easier to produce and that pressures for communicative efficiency mostly come from ASL usage, not from English lexical borrowing.
Interpreting Language Models with Contrastive Explanations
Feb 21, 2022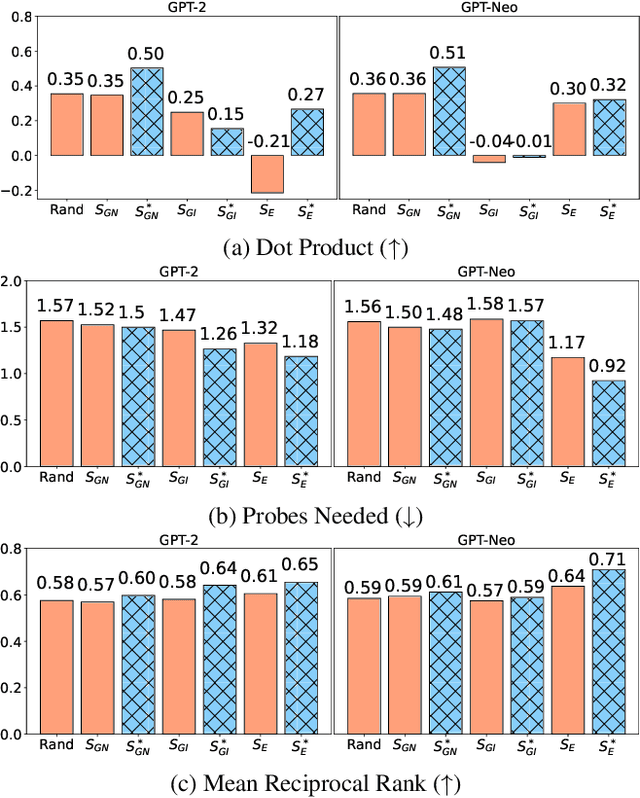



Model interpretability methods are often used to explain NLP model decisions on tasks such as text classification, where the output space is relatively small. However, when applied to language generation, where the output space often consists of tens of thousands of tokens, these methods are unable to provide informative explanations. Language models must consider various features to predict a token, such as its part of speech, number, tense, or semantics. Existing explanation methods conflate evidence for all these features into a single explanation, which is less interpretable for human understanding. To disentangle the different decisions in language modeling, we focus on explaining language models contrastively: we look for salient input tokens that explain why the model predicted one token instead of another. We demonstrate that contrastive explanations are quantifiably better than non-contrastive explanations in verifying major grammatical phenomena, and that they significantly improve contrastive model simulatability for human observers. We also identify groups of contrastive decisions where the model uses similar evidence, and we are able to characterize what input tokens models use during various language generation decisions.
When Does Translation Require Context? A Data-driven, Multilingual Exploration
Sep 15, 2021


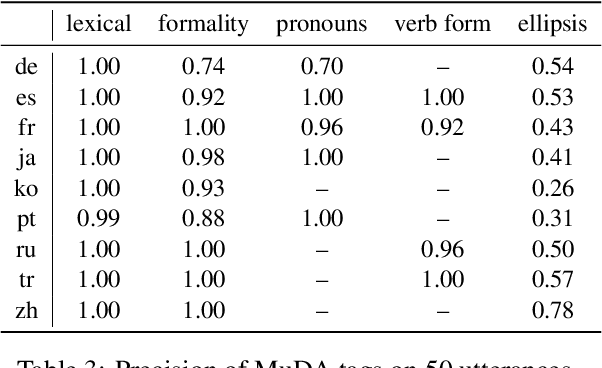
Although proper handling of discourse phenomena significantly contributes to the quality of machine translation (MT), common translation quality metrics do not adequately capture them. Recent works in context-aware MT attempt to target a small set of these phenomena during evaluation. In this paper, we propose a new metric, P-CXMI, which allows us to identify translations that require context systematically and confirm the difficulty of previously studied phenomena as well as uncover new ones that have not been addressed in previous work. We then develop the Multilingual Discourse-Aware (MuDA) benchmark, a series of taggers for these phenomena in 14 different language pairs, which we use to evaluate context-aware MT. We find that state-of-the-art context-aware MT models find marginal improvements over context-agnostic models on our benchmark, which suggests current models do not handle these ambiguities effectively. We release code and data to invite the MT research community to increase efforts on context-aware translation on discourse phenomena and languages that are currently overlooked.
When is Wall a Pared and when a Muro? -- Extracting Rules Governing Lexical Selection
Sep 13, 2021
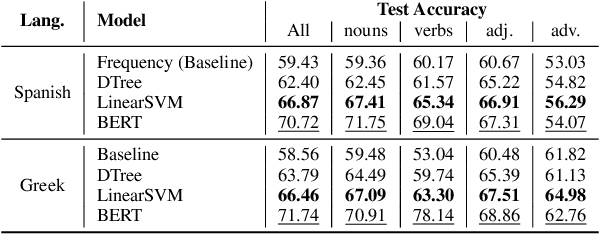
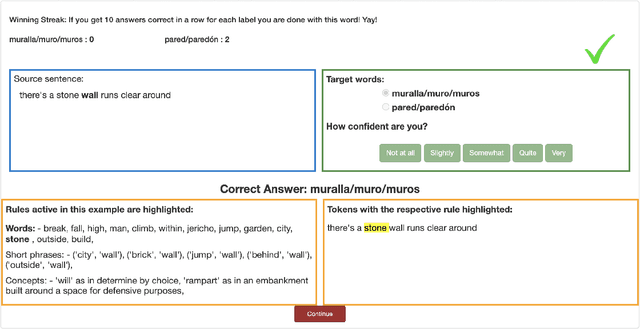

Learning fine-grained distinctions between vocabulary items is a key challenge in learning a new language. For example, the noun "wall" has different lexical manifestations in Spanish -- "pared" refers to an indoor wall while "muro" refers to an outside wall. However, this variety of lexical distinction may not be obvious to non-native learners unless the distinction is explained in such a way. In this work, we present a method for automatically identifying fine-grained lexical distinctions, and extracting concise descriptions explaining these distinctions in a human- and machine-readable format. We confirm the quality of these extracted descriptions in a language learning setup for two languages, Spanish and Greek, where we use them to teach non-native speakers when to translate a given ambiguous word into its different possible translations. Code and data are publicly released here (https://github.com/Aditi138/LexSelection)