 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGistify! Codebase-Level Understanding via Runtime Execution
Oct 30, 2025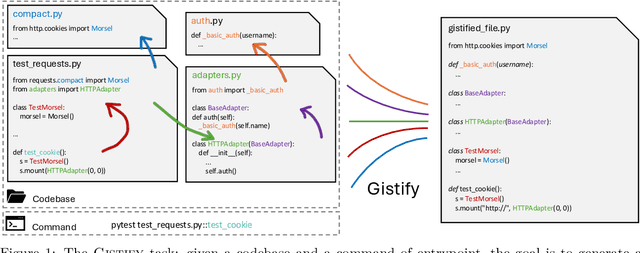
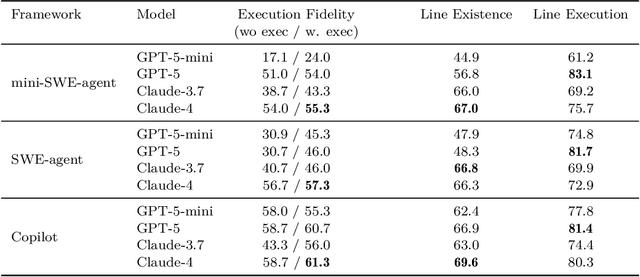

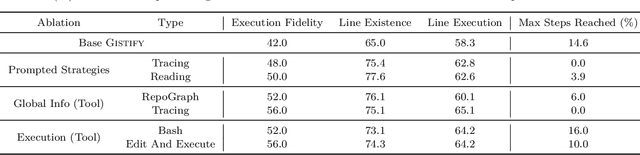
As coding agents are increasingly deployed in large codebases, the need to automatically design challenging, codebase-level evaluation is central. We propose Gistify, a task where a coding LLM must create a single, minimal, self-contained file that can reproduce a specific functionality of a codebase. The coding LLM is given full access to a codebase along with a specific entrypoint (e.g., a python command), and the generated file must replicate the output of the same command ran under the full codebase, while containing only the essential components necessary to execute the provided command. Success on Gistify requires both structural understanding of the codebase, accurate modeling of its execution flow as well as the ability to produce potentially large code patches. Our findings show that current state-of-the-art models struggle to reliably solve Gistify tasks, especially ones with long executions traces.
debug-gym: A Text-Based Environment for Interactive Debugging
Mar 27, 2025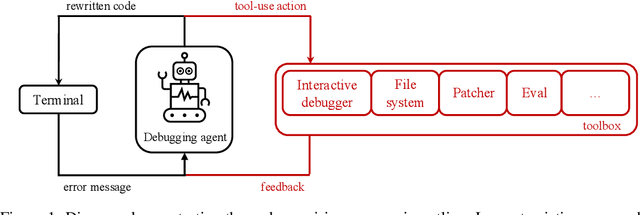
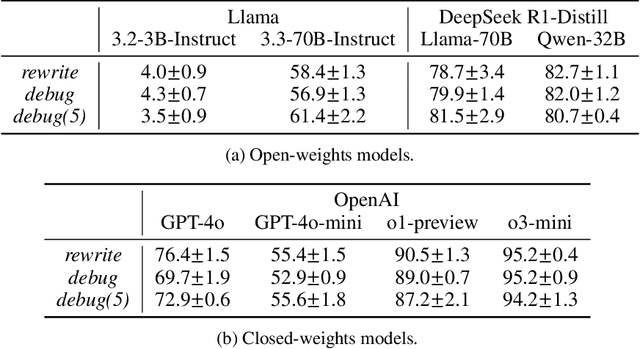
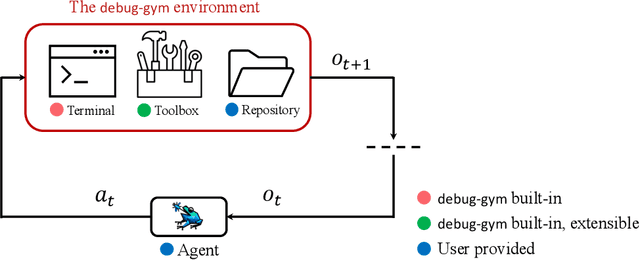
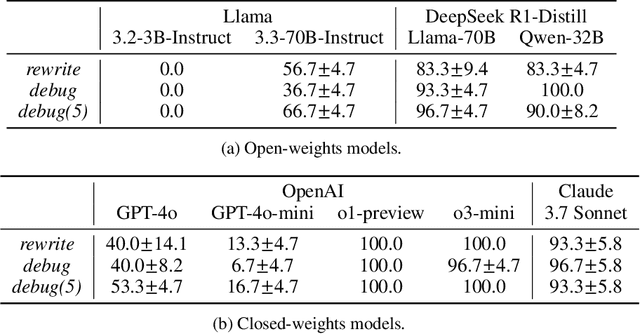
Large Language Models (LLMs) are increasingly relied upon for coding tasks, yet in most scenarios it is assumed that all relevant information can be either accessed in context or matches their training data. We posit that LLMs can benefit from the ability to interactively explore a codebase to gather the information relevant to their task. To achieve this, we present a textual environment, namely debug-gym, for developing LLM-based agents in an interactive coding setting. Our environment is lightweight and provides a preset of useful tools, such as a Python debugger (pdb), designed to facilitate an LLM-based agent's interactive debugging. Beyond coding and debugging tasks, this approach can be generalized to other tasks that would benefit from information-seeking behavior by an LLM agent.
ASL STEM Wiki: Dataset and Benchmark for Interpreting STEM Articles
Nov 08, 2024Deaf and hard-of-hearing (DHH) students face significant barriers in accessing science, technology, engineering, and mathematics (STEM) education, notably due to the scarcity of STEM resources in signed languages. To help address this, we introduce ASL STEM Wiki: a parallel corpus of 254 Wikipedia articles on STEM topics in English, interpreted into over 300 hours of American Sign Language (ASL). ASL STEM Wiki is the first continuous signing dataset focused on STEM, facilitating the development of AI resources for STEM education in ASL. We identify several use cases of ASL STEM Wiki with human-centered applications. For example, because this dataset highlights the frequent use of fingerspelling for technical concepts, which inhibits DHH students' ability to learn, we develop models to identify fingerspelled words -- which can later be used to query for appropriate ASL signs to suggest to interpreters.
ASL Citizen: A Community-Sourced Dataset for Advancing Isolated Sign Language Recognition
Apr 12, 2023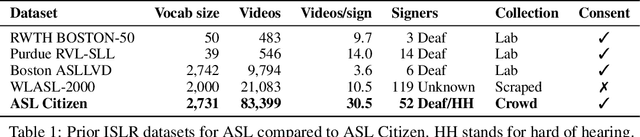


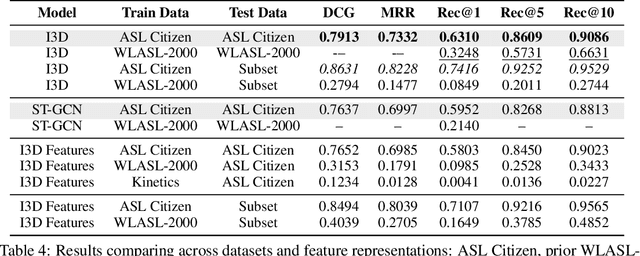
Sign languages are used as a primary language by approximately 70 million D/deaf people world-wide. However, most communication technologies operate in spoken and written languages, creating inequities in access. To help tackle this problem, we release ASL Citizen, the largest Isolated Sign Language Recognition (ISLR) dataset to date, collected with consent and containing 83,912 videos for 2,731 distinct signs filmed by 52 signers in a variety of environments. We propose that this dataset be used for sign language dictionary retrieval for American Sign Language (ASL), where a user demonstrates a sign to their own webcam with the aim of retrieving matching signs from a dictionary. We show that training supervised machine learning classifiers with our dataset greatly advances the state-of-the-art on metrics relevant for dictionary retrieval, achieving, for instance, 62% accuracy and a recall-at-10 of 90%, evaluated entirely on videos of users who are not present in the training or validation sets. An accessible PDF of this article is available at https://aashakadesai.github.io/research/ASL_Dataset__arxiv_.pdf