 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeASL Citizen: A Community-Sourced Dataset for Advancing Isolated Sign Language Recognition
Apr 12, 2023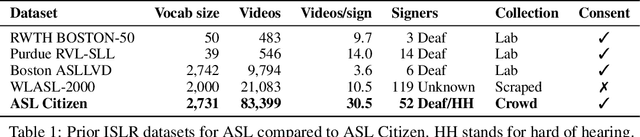


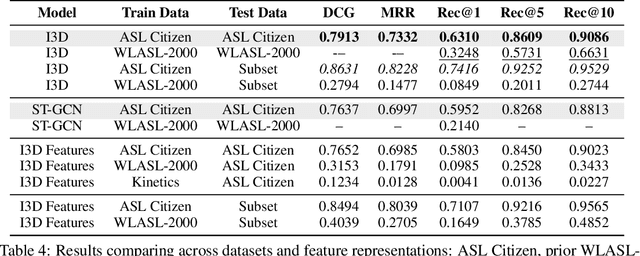
Sign languages are used as a primary language by approximately 70 million D/deaf people world-wide. However, most communication technologies operate in spoken and written languages, creating inequities in access. To help tackle this problem, we release ASL Citizen, the largest Isolated Sign Language Recognition (ISLR) dataset to date, collected with consent and containing 83,912 videos for 2,731 distinct signs filmed by 52 signers in a variety of environments. We propose that this dataset be used for sign language dictionary retrieval for American Sign Language (ASL), where a user demonstrates a sign to their own webcam with the aim of retrieving matching signs from a dictionary. We show that training supervised machine learning classifiers with our dataset greatly advances the state-of-the-art on metrics relevant for dictionary retrieval, achieving, for instance, 62% accuracy and a recall-at-10 of 90%, evaluated entirely on videos of users who are not present in the training or validation sets. An accessible PDF of this article is available at https://aashakadesai.github.io/research/ASL_Dataset__arxiv_.pdf