 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Sem-Lex Benchmark: Modeling ASL Signs and Their Phonemes
Sep 30, 2023Sign language recognition and translation technologies have the potential to increase access and inclusion of deaf signing communities, but research progress is bottlenecked by a lack of representative data. We introduce a new resource for American Sign Language (ASL) modeling, the Sem-Lex Benchmark. The Benchmark is the current largest of its kind, consisting of over 84k videos of isolated sign productions from deaf ASL signers who gave informed consent and received compensation. Human experts aligned these videos with other sign language resources including ASL-LEX, SignBank, and ASL Citizen, enabling useful expansions for sign and phonological feature recognition. We present a suite of experiments which make use of the linguistic information in ASL-LEX, evaluating the practicality and fairness of the Sem-Lex Benchmark for isolated sign recognition (ISR). We use an SL-GCN model to show that the phonological features are recognizable with 85% accuracy, and that they are effective as an auxiliary target to ISR. Learning to recognize phonological features alongside gloss results in a 6% improvement for few-shot ISR accuracy and a 2% improvement for ISR accuracy overall. Instructions for downloading the data can be found at https://github.com/leekezar/SemLex.
ASL Citizen: A Community-Sourced Dataset for Advancing Isolated Sign Language Recognition
Apr 12, 2023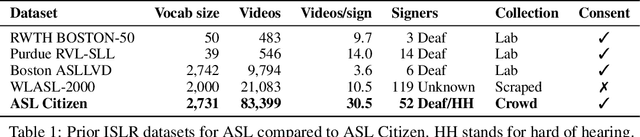


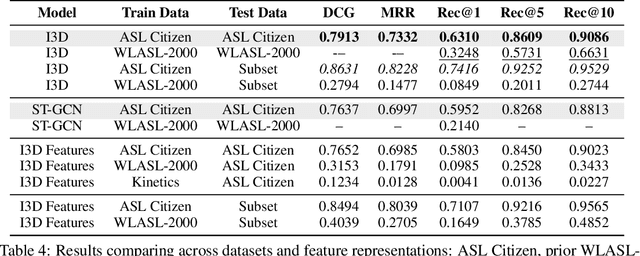
Sign languages are used as a primary language by approximately 70 million D/deaf people world-wide. However, most communication technologies operate in spoken and written languages, creating inequities in access. To help tackle this problem, we release ASL Citizen, the largest Isolated Sign Language Recognition (ISLR) dataset to date, collected with consent and containing 83,912 videos for 2,731 distinct signs filmed by 52 signers in a variety of environments. We propose that this dataset be used for sign language dictionary retrieval for American Sign Language (ASL), where a user demonstrates a sign to their own webcam with the aim of retrieving matching signs from a dictionary. We show that training supervised machine learning classifiers with our dataset greatly advances the state-of-the-art on metrics relevant for dictionary retrieval, achieving, for instance, 62% accuracy and a recall-at-10 of 90%, evaluated entirely on videos of users who are not present in the training or validation sets. An accessible PDF of this article is available at https://aashakadesai.github.io/research/ASL_Dataset__arxiv_.pdf