 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOffloading Score: Measuring AI Reliance Through Counterfactual Workflows
May 28, 2026AI tools are increasingly integrated into real-world workflows. However, existing measures of reliance on these tools focus on AI output adoption or on self-reported indicators, rather than how task effort is distributed between users and tools. Here, we introduce offloading score, a measure of reliance that quantifies the fraction of cognitive effort offloaded to an AI tool. Offloading Score is simulation-based -- we construct a counterfactual workflow by estimating how the user would have completed the task without the tool, and then computing the fraction of steps saved by using the tool. We validate offloading score through intrinsic evaluations of metric validity, and a controlled user study ($n=40$) with developers performing programming tasks using AI tools. We vary time pressure to test whether reliance measures capture the known increase in reliance under time pressure. We show that offloading score detects significantly higher reliance in time-constrained settings ($+43\%$, $p=0.018$), while usage-based and self-reported baseline measures of reliance do not distinguish the conditions. We complement this with descriptive insights showing that higher reliance manifests as greater delegation of subtasks to the tool and more direct reuse of AI outputs. Finally, we demonstrate an approach of using offloading score in combination with target outcomes of a task (e.g., code understanding) to identify when reliance may be (in)appropriate. Our framework offers two contributions: an instrument users can apply to measure and reflect on their own reliance, and a quantitative signal that agent designers can utilize to mitigate overreliance.
SWE-chat: Coding Agent Interactions From Real Users in the Wild
Apr 22, 2026AI coding agents are being adopted at scale, yet we lack empirical evidence on how people actually use them and how much of their output is useful in practice. We present SWE-chat, the first large-scale dataset of real coding agent sessions collected from open-source developers in the wild. The dataset currently contains 6,000 sessions, comprising more than 63,000 user prompts and 355,000 agent tool calls. SWE-chat is a living dataset; our collection pipeline automatically and continually discovers and processes sessions from public repositories. Leveraging SWE-chat, we provide an initial empirical characterization of real-world coding agent usage and failure modes. We find that coding patterns are bimodal: in 41% of sessions, agents author virtually all committed code ("vibe coding"), while in 23%, humans write all code themselves. Despite rapidly improving capabilities, coding agents remain inefficient in natural settings. Just 44% of all agent-produced code survives into user commits, and agent-written code introduces more security vulnerabilities than code authored by humans. Furthermore, users push back against agent outputs -- through corrections, failure reports, and interruptions -- in 44% of all turns. By capturing complete interaction traces with human vs. agent code authorship attribution, SWE-chat provides an empirical foundation for moving beyond curated benchmarks towards an evidence-based understanding of how AI agents perform in real developer workflows.
No Single Best Model for Diversity: Learning a Router for Sample Diversity
Apr 02, 2026When posed with prompts that permit a large number of valid answers, comprehensively generating them is the first step towards satisfying a wide range of users. In this paper, we study methods to elicit a comprehensive set of valid responses. To evaluate this, we introduce \textbf{diversity coverage}, a metric that measures the total quality scores assigned to each \textbf{unique} answer in the predicted answer set relative to the best possible answer set with the same number of answers. Using this metric, we evaluate 18 LLMs, finding no single model dominates at generating diverse responses to a wide range of open-ended prompts. Yet, per each prompt, there exists a model that outperforms all other models significantly at generating a diverse answer set. Motivated by this finding, we introduce a router that predicts the best model for each query. On NB-Wildchat, our trained router outperforms the single best model baseline (26.3% vs $23.8%). We further show generalization to an out-of-domain dataset (NB-Curated) as well as different answer-generation prompting strategies. Our work lays foundation for studying generating comprehensive answers when we have access to a suite of models.
SparkMe: Adaptive Semi-Structured Interviewing for Qualitative Insight Discovery
Feb 24, 2026Qualitative insights from user experiences are critical for informing product and policy decisions, but collecting such data at scale is constrained by the time and availability of experts to conduct semi-structured interviews. Recent work has explored using large language models (LLMs) to automate interviewing, yet existing systems lack a principled mechanism for balancing systematic coverage of predefined topics with adaptive exploration, or the ability to pursue follow-ups, deep dives, and emergent themes that arise organically during conversation. In this work, we formulate adaptive semi-structured interviewing as an optimization problem over the interviewer's behavior. We define interview utility as a trade-off between coverage of a predefined interview topic guide, discovery of relevant emergent themes, and interview cost measured by length. Based on this formulation, we introduce SparkMe, a multi-agent LLM interviewer that performs deliberative planning via simulated conversation rollouts to select questions with high expected utility. We evaluate SparkMe through controlled experiments with LLM-based interviewees, showing that it achieves higher interview utility, improving topic guide coverage (+4.7% over the best baseline) and eliciting richer emergent insights while using fewer conversational turns than prior LLM interviewing approaches. We further validate SparkMe in a user study with 70 participants across 7 professions on the impact of AI on their workflows. Domain experts rate SparkMe as producing high-quality adaptive interviews that surface helpful profession-specific insights not captured by prior approaches. The code, datasets, and evaluation protocols for SparkMe are available as open-source at https://github.com/SALT-NLP/SparkMe.
LiteraryTaste: A Preference Dataset for Creative Writing Personalization
Nov 12, 2025People have different creative writing preferences, and large language models (LLMs) for these tasks can benefit from adapting to each user's preferences. However, these models are often trained over a dataset that considers varying personal tastes as a monolith. To facilitate developing personalized creative writing LLMs, we introduce LiteraryTaste, a dataset of reading preferences from 60 people, where each person: 1) self-reported their reading habits and tastes (stated preference), and 2) annotated their preferences over 100 pairs of short creative writing texts (revealed preference). With our dataset, we found that: 1) people diverge on creative writing preferences, 2) finetuning a transformer encoder could achieve 75.8% and 67.7% accuracy when modeling personal and collective revealed preferences, and 3) stated preferences had limited utility in modeling revealed preferences. With an LLM-driven interpretability pipeline, we analyzed how people's preferences vary. We hope our work serves as a cornerstone for personalizing creative writing technologies.
Principled Content Selection to Generate Diverse and Personalized Multi-Document Summaries
May 28, 2025
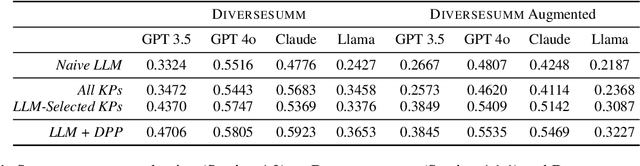
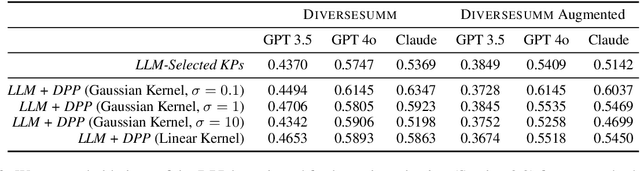
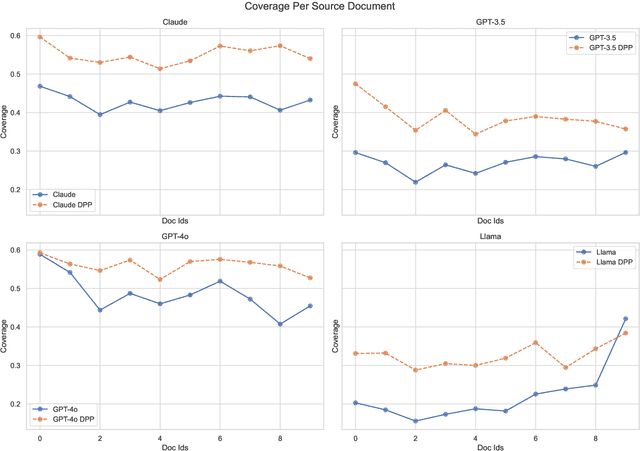
While large language models (LLMs) are increasingly capable of handling longer contexts, recent work has demonstrated that they exhibit the "lost in the middle" phenomenon (Liu et al., 2024) of unevenly attending to different parts of the provided context. This hinders their ability to cover diverse source material in multi-document summarization, as noted in the DiverseSumm benchmark (Huang et al., 2024). In this work, we contend that principled content selection is a simple way to increase source coverage on this task. As opposed to prompting an LLM to perform the summarization in a single step, we explicitly divide the task into three steps -- (1) reducing document collections to atomic key points, (2) using determinantal point processes (DPP) to perform select key points that prioritize diverse content, and (3) rewriting to the final summary. By combining prompting steps, for extraction and rewriting, with principled techniques, for content selection, we consistently improve source coverage on the DiverseSumm benchmark across various LLMs. Finally, we also show that by incorporating relevance to a provided user intent into the DPP kernel, we can generate personalized summaries that cover relevant source information while retaining coverage.
Evaluating the Diversity and Quality of LLM Generated Content
Apr 16, 2025



Recent work suggests that preference-tuning techniques--including Reinforcement Learning from Human Preferences (RLHF) methods like PPO and GRPO, as well as alternatives like DPO--reduce diversity, creating a dilemma given that such models are widely deployed in applications requiring diverse outputs. To address this, we introduce a framework for measuring effective semantic diversity--diversity among outputs that meet quality thresholds--which better reflects the practical utility of large language models (LLMs). Using open-ended tasks that require no human intervention, we find counterintuitive results: although preference-tuned models--especially those trained via RL--exhibit reduced lexical and syntactic diversity, they produce greater effective semantic diversity than SFT or base models, not from increasing diversity among high-quality outputs, but from generating more high-quality outputs overall. We discover that preference tuning reduces syntactic diversity while preserving semantic diversity--revealing a distinction between diversity in form and diversity in content that traditional metrics often overlook. Our analysis further shows that smaller models are consistently more parameter-efficient at generating unique content within a fixed sampling budget, offering insights into the relationship between model scaling and diversity. These findings have important implications for applications that require diverse yet high-quality outputs, from creative assistance to synthetic data generation.
Beyond Memorization: Mapping the Originality-Quality Frontier of Language Models
Apr 13, 2025As large language models (LLMs) are increasingly used for ideation and scientific discovery, it is important to evaluate their ability to generate novel output. Prior work evaluates novelty as the originality with respect to training data, but original outputs can be low quality. In contrast, non-expert judges may favor high-quality but memorized outputs, limiting the reliability of human preference as a metric. We propose a new novelty metric for LLM generations that balances originality and quality -- the harmonic mean of the fraction of \ngrams unseen during training and a task-specific quality score. We evaluate the novelty of generations from two families of open-data models (OLMo and Pythia) on three creative tasks: story completion, poetry writing, and creative tool use. We find that LLM generated text is less novel than human written text. To elicit more novel outputs, we experiment with various inference-time methods, which reveals a trade-off between originality and quality. While these methods can boost novelty, they do so by increasing originality at the expense of quality. In contrast, increasing model size or applying post-training reliably shifts the Pareto frontier, highlighting that starting with a stronger base model is a more effective way to improve novelty.
Modifying Large Language Model Post-Training for Diverse Creative Writing
Mar 21, 2025As creative writing tasks do not have singular correct answers, large language models (LLMs) trained to perform these tasks should be able to generate diverse valid outputs. However, LLM post-training often focuses on improving generation quality but neglects to facilitate output diversity. Hence, in creative writing generation, we investigate post-training approaches to promote both output diversity and quality. Our core idea is to include deviation -- the degree of difference between a training sample and all other samples with the same prompt -- in the training objective to facilitate learning from rare high-quality instances. By adopting our approach to direct preference optimization (DPO) and odds ratio preference optimization (ORPO), we demonstrate that we can promote the output diversity of trained models while minimally decreasing quality. Our best model with 8B parameters could achieve on-par diversity as a human-created dataset while having output quality similar to the best instruction-tuned models we examined, GPT-4o and DeepSeek-R1. We further validate our approaches with a human evaluation, an ablation, and a comparison to an existing diversification approach, DivPO.
Whose Boat Does it Float? Improving Personalization in Preference Tuning via Inferred User Personas
Jan 20, 2025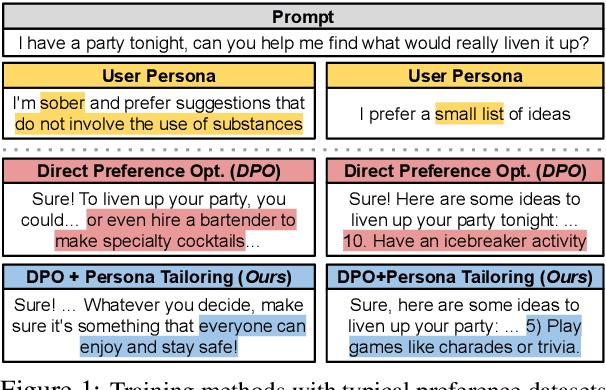

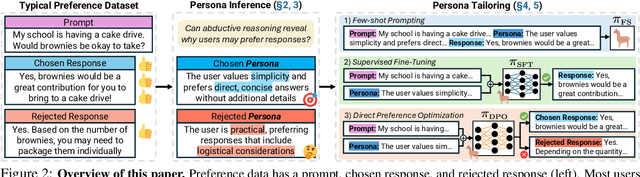
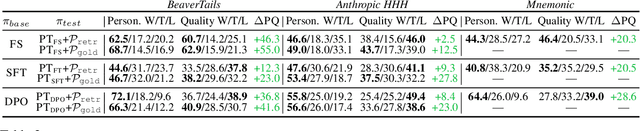
LLMs are tuned to follow instructions (aligned) by learning which of two outputs users prefer for a prompt. However, this preference data format does not convey why users prefer responses that are chosen or rejected, so LLMs trained on these datasets cannot tailor responses to varied user needs. To surface these parameters of personalization, we apply abductive reasoning to preference data, inferring needs and interests of users, i.e. personas, that may prefer each output. We test this idea in two steps: Persona Inference (PI)-abductively inferring personas of users who prefer chosen or rejected outputs-and Persona Tailoring (PT)-training models to tailor responses to personas from PI. We find: 1) LLMs infer personas accurately explaining why different users may prefer both chosen or rejected outputs; 2) Training on preference data augmented with PI personas via PT boosts personalization, enabling models to support user-written personas; and 3) Rejected response personas form harder personalization evaluations, showing PT better aids users with uncommon preferences versus typical alignment methods. We argue for an abductive view of preferences for personalization, asking not only which response is better but when, why, and for whom.