 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDesign Techniques for LLM-Powered Interactive Storytelling: A Case Study of the Dramamancer System
Jan 26, 2026The rise of Large Language Models (LLMs) has enabled a new paradigm for bridging authorial intent and player agency in interactive narrative. We consider this paradigm through the example of Dramamancer, a system that uses an LLM to transform author-created story schemas into player-driven playthroughs. This extended abstract outlines some design techniques and evaluation considerations associated with this system.
LiteraryTaste: A Preference Dataset for Creative Writing Personalization
Nov 12, 2025People have different creative writing preferences, and large language models (LLMs) for these tasks can benefit from adapting to each user's preferences. However, these models are often trained over a dataset that considers varying personal tastes as a monolith. To facilitate developing personalized creative writing LLMs, we introduce LiteraryTaste, a dataset of reading preferences from 60 people, where each person: 1) self-reported their reading habits and tastes (stated preference), and 2) annotated their preferences over 100 pairs of short creative writing texts (revealed preference). With our dataset, we found that: 1) people diverge on creative writing preferences, 2) finetuning a transformer encoder could achieve 75.8% and 67.7% accuracy when modeling personal and collective revealed preferences, and 3) stated preferences had limited utility in modeling revealed preferences. With an LLM-driven interpretability pipeline, we analyzed how people's preferences vary. We hope our work serves as a cornerstone for personalizing creative writing technologies.
Modifying Large Language Model Post-Training for Diverse Creative Writing
Mar 21, 2025As creative writing tasks do not have singular correct answers, large language models (LLMs) trained to perform these tasks should be able to generate diverse valid outputs. However, LLM post-training often focuses on improving generation quality but neglects to facilitate output diversity. Hence, in creative writing generation, we investigate post-training approaches to promote both output diversity and quality. Our core idea is to include deviation -- the degree of difference between a training sample and all other samples with the same prompt -- in the training objective to facilitate learning from rare high-quality instances. By adopting our approach to direct preference optimization (DPO) and odds ratio preference optimization (ORPO), we demonstrate that we can promote the output diversity of trained models while minimally decreasing quality. Our best model with 8B parameters could achieve on-par diversity as a human-created dataset while having output quality similar to the best instruction-tuned models we examined, GPT-4o and DeepSeek-R1. We further validate our approaches with a human evaluation, an ablation, and a comparison to an existing diversification approach, DivPO.
Phraselette: A Poet's Procedural Palette
Mar 08, 2025According to the recently introduced theory of artistic support tools, creativity support tools exert normative influences over artistic production, instantiating a normative ground that shapes both the process and product of artistic expression. We argue that the normative ground of most existing automated writing tools is misaligned with writerly values and identify a potential alternative frame-material writing support-for experimental poetry tools that flexibly support the finding, processing, transforming, and shaping of text(s). Based on this frame, we introduce Phraselette, an artistic material writing support interface that helps experimental poets search for words and phrases. To provide material writing support, Phraselette is designed to counter the dominant mode of automated writing tools, while offering language model affordances in line with writerly values. We further report on an extended expert evaluation involving 10 published poets that indicates support for both our framing of material writing support and for Phraselette itself.
From Test-Taking to Test-Making: Examining LLM Authoring of Commonsense Assessment Items
Oct 18, 2024LLMs can now perform a variety of complex writing tasks. They also excel in answering questions pertaining to natural language inference and commonsense reasoning. Composing these questions is itself a skilled writing task, so in this paper we consider LLMs as authors of commonsense assessment items. We prompt LLMs to generate items in the style of a prominent benchmark for commonsense reasoning, the Choice of Plausible Alternatives (COPA). We examine the outcome according to analyses facilitated by the LLMs and human annotation. We find that LLMs that succeed in answering the original COPA benchmark are also more successful in authoring their own items.
AbLit: A Resource for Analyzing and Generating Abridged Versions of English Literature
Feb 13, 2023
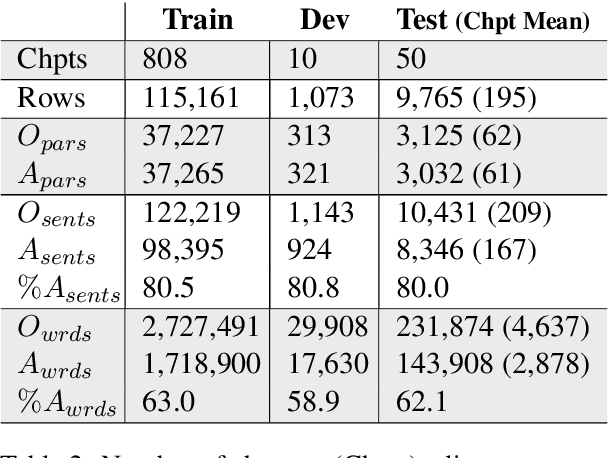
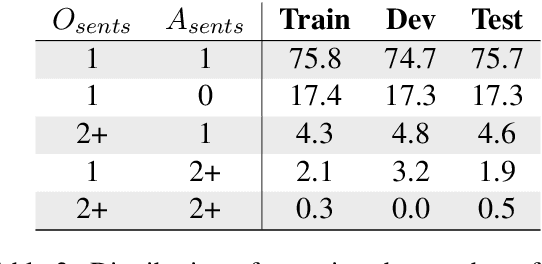
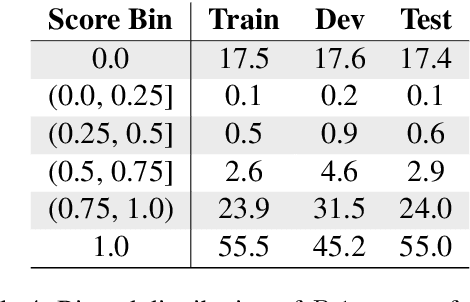
Creating an abridged version of a text involves shortening it while maintaining its linguistic qualities. In this paper, we examine this task from an NLP perspective for the first time. We present a new resource, AbLit, which is derived from abridged versions of English literature books. The dataset captures passage-level alignments between the original and abridged texts. We characterize the linguistic relations of these alignments, and create automated models to predict these relations as well as to generate abridgements for new texts. Our findings establish abridgement as a challenging task, motivating future resources and research. The dataset is available at github.com/roemmele/AbLit.
Inspiration through Observation: Demonstrating the Influence of Automatically Generated Text on Creative Writing
Jul 08, 2021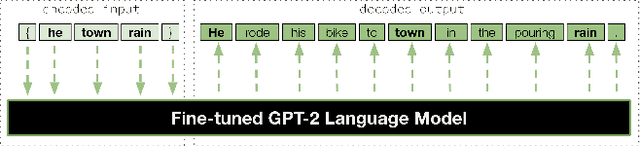

Getting machines to generate text perceived as creative is a long-pursued goal. A growing body of research directs this goal towards augmenting the creative writing abilities of human authors. In this paper, we pursue this objective by analyzing how observing examples of automatically generated text influences writing. In particular, we examine a task referred to as sentence infilling, which involves transforming a list of words into a complete sentence. We emphasize "storiability" as a desirable feature of the resulting sentences, where "storiable" sentences are those that suggest a story a reader would be curious to hear about. Both humans and an automated system (based on a neural language model) performed this sentence infilling task. In one setting, people wrote sentences on their own; in a different setting, people observed the sentences produced by the model while writing their own sentences. Readers then assigned storiability preferences to the resulting sentences in a subsequent evaluation. We find that human-authored sentences were judged as more storiable when authors observed the generated examples, and that storiability increased as authors derived more semantic content from the examples. This result gives evidence of an "inspiration through observation" paradigm for human-computer collaborative writing, through which human writing can be enhanced by text generation models without directly copying their output.
AnswerQuest: A System for Generating Question-Answer Items from Multi-Paragraph Documents
Mar 05, 2021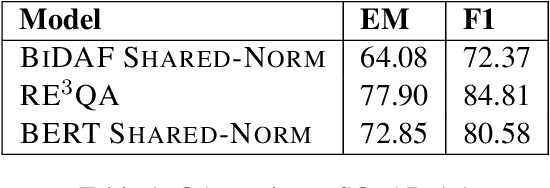

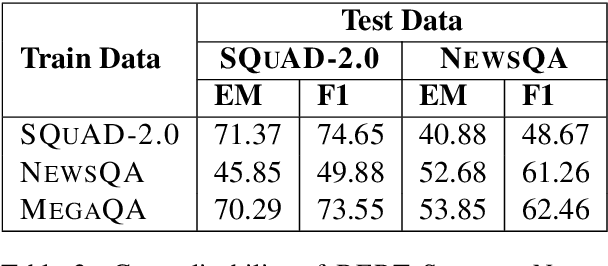

One strategy for facilitating reading comprehension is to present information in a question-and-answer format. We demo a system that integrates the tasks of question answering (QA) and question generation (QG) in order to produce Q&A items that convey the content of multi-paragraph documents. We report some experiments for QA and QG that yield improvements on both tasks, and assess how they interact to produce a list of Q&A items for a text. The demo is accessible at qna.sdl.com.